




PG更新表元組(數據行)時不會直接修改該元組,它會寫入新版本元組并保留舊版本元組,這樣來提高并發讀取的請求,舊版本的"死元組"稍后由VACUUM來清理。
因而如果我們刪除一行數據并且插入一行新數據,數據庫里是有一個死元組和一個新的活元組。所以我們通常會這樣向別人解釋PG里的"UPDATE":
update ≈ delete + insert
下面我們通過實驗來理解這個"約等于"的差異。
創建測試表并插入一條數據:
CREATE TABLE test_update (
id int2 PRIMARY KEY,
val int2 NOT NULL
);
INSERT INTO test_update VALUES (1, 100);
接下來的兩個測試,我們使用兩個并發會話發起語句,如下圖。
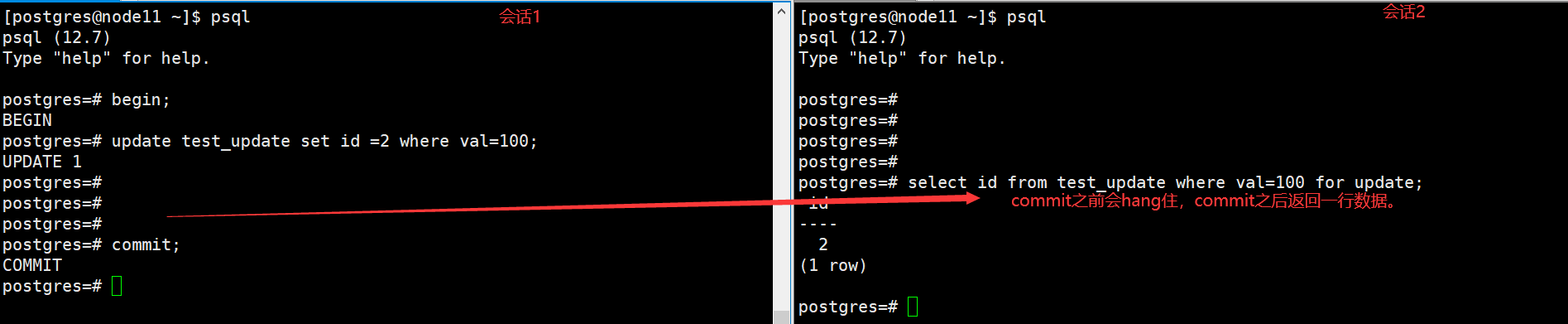
重置表后開始第二次測試
TRUNCATE test_update;
INSERT INTO test_update VALUES (1, 100);
第二次測試我們使用delete和insert操作來進行測試,如下圖
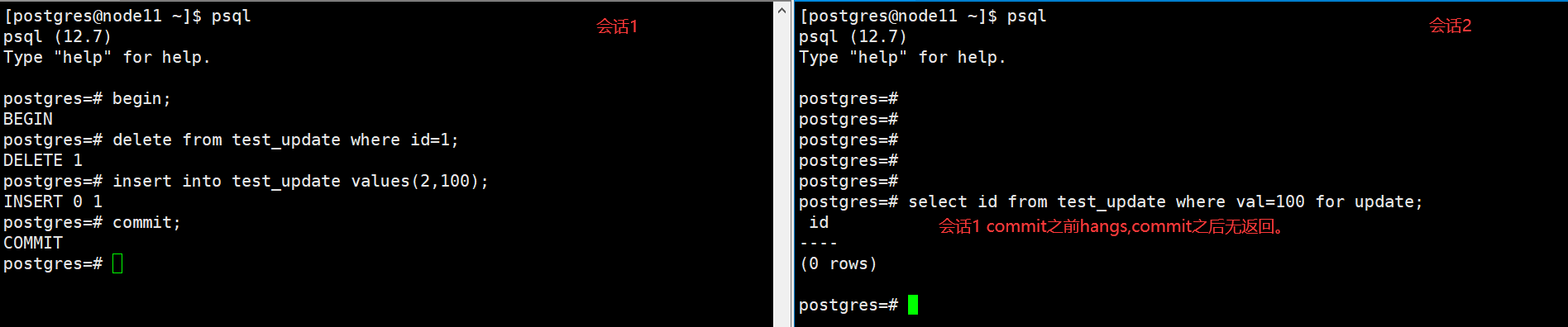
對上面兩個測試結果差異的解釋可以參考官方文檔XACT-READ-COMMITTED
UPDATE, DELETE, SELECT FOR UPDATE, and SELECT FOR SHARE commands behave the same as SELECT in terms of searching for target rows: they will only find target rows that were committed as of the command start time. However, such a target row might have already been updated (or deleted or locked) by another concurrent transaction by the time it is found. In this case, the would-be updater will wait for the first updating transaction to commit or roll back (if it is still in progress). If the first updater rolls back, then its effects are negated and the second updater can proceed with updating the originally found row. If the first updater commits, the second updater will ignore the row if the first updater deleted it, otherwise it will attempt to apply its operation to the updated version of the row. The search condition of the command (the WHERE clause) is re-evaluated to see if the updated version of the row still matches the search condition. If so, the second updater proceeds with its operation using the updated version of the row. In the case of SELECT FOR UPDATE and SELECT FOR SHARE, this means it is the updated version of the row that is locked and returned to the client.
上面解釋了第一個測試返回一行數據的原因,而在第二個測試中,刪除的行和新插入的行之間沒有聯系(第一個測試里通過pageinspect可以觀察ctid值),所以第二種情況下并沒有得到結果。
參考文章:
https://www.cybertec-postgresql.com/en/is-update-the-same-as-delete-insert-in-postgresql/
