





引入 | 記一次從執(zhí)行計(jì)劃定位SQL問(wèn)題及性能優(yōu)化的思考過(guò)程
一、問(wèn)題復(fù)現(xiàn):
寫(xiě)在前面的話,童鞋遇到了這樣一個(gè)問(wèn)題-SQL慢查詢,在30萬(wàn)數(shù)據(jù)中查詢,某個(gè)接口響應(yīng)耗時(shí),導(dǎo)致頁(yè)面直接掛掉,其中,SQL引入了視圖,比較復(fù)雜,這里暫時(shí)就不貼代碼了。
下面列舉幾個(gè)示例,在實(shí)際項(xiàng)目中,當(dāng)數(shù)據(jù)量一上來(lái),就發(fā)現(xiàn)索引其實(shí)是多么的重要,怎么排查視圖中的表有沒(méi)有建立索引,其中索引有沒(méi)有失效,哪些索引沒(méi)有利用上,又是如何失效的,耗時(shí)分析等,或許這能給我們?cè)趯?shí)際項(xiàng)目中作SQL優(yōu)化,在整體思路上有著及其重要的啟發(fā)!
二、假設(shè)猜想:
1、在sql查詢條件中,未對(duì)條件字段建立索引?
2、在view中,表的訪問(wèn)方式、連接順序以及連接方式是否合理?
3、在已建立的索引中,索引是否命中,是否存在失效的情況,走全表掃描?
三、思考過(guò)程:
從頁(yè)面發(fā)起請(qǐng)求到后端服務(wù)接口響應(yīng)耗時(shí)至頁(yè)面直接掛掉:
1、首先,通過(guò)F12查閱頁(yè)面加載耗時(shí)以及對(duì)后端接口加入耗時(shí)日志,得以分析最長(zhǎng)耗時(shí)卡在DAO層,即SQL業(yè)務(wù)邏輯查詢-結(jié)果響應(yīng)。
2、接著,由于這里是遠(yuǎn)程排查,我們可以通過(guò)堡壘機(jī)的方式登入或者其他遠(yuǎn)程方式,然后打開(kāi)Oracle客戶端PL/SQL Developer,拷貝日志中打印的SQL語(yǔ)句在客戶端查詢。
3、然后,筆記本電腦的話可通過(guò)Fn+F5快捷鍵,在客戶端打開(kāi)當(dāng)前SQL的查詢計(jì)劃進(jìn)行具體排查,作進(jìn)一步分析。
圖一
圖二
圖三
這里,先對(duì)執(zhí)行計(jì)劃中一些概念作下詳細(xì)說(shuō)明:
資源成本耗費(fèi) (COST)
全表掃描(TABLE ACCESS FULL)
索引掃描 (INDEX SCAN)
嵌套循環(huán)(NESTED LOOPS)
哈希連接(HASH JOIN)
排序-合并連接(SORT MERGE JOIN)
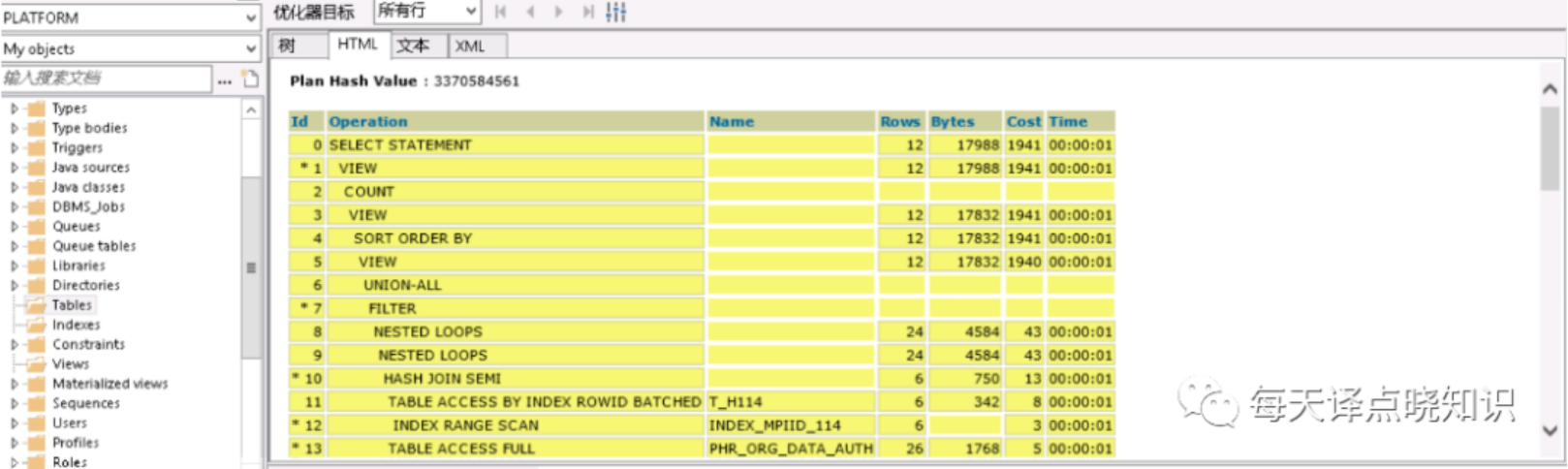
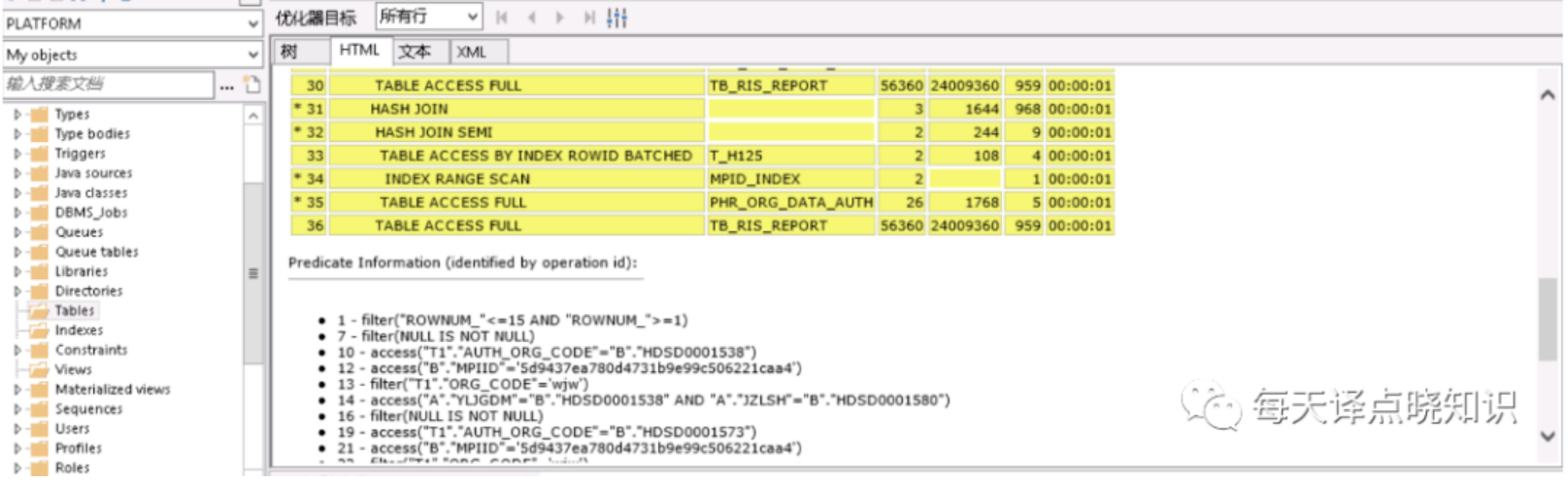
其中,每一個(gè)執(zhí)行步驟都有對(duì)應(yīng)的COST,可以從單步COST的高低,以及單步的估計(jì)結(jié)果集-對(duì)應(yīng)ROWS/基數(shù),來(lái)分析表的訪問(wèn)方式、連接順序以及連接方式是否合理。
我們從執(zhí)行計(jì)劃中可知,其中可看到走了全表掃描-TABLE ACCESS FULL的表,且掃描的行數(shù)ROWS以及COST也占居最高。分析到了這里,問(wèn)題的根源離我們又近了一步。但是當(dāng)我們查看打印出來(lái)的SQL語(yǔ)句并沒(méi)有查到當(dāng)前表名,那會(huì)不會(huì)是存在view視圖中呢?
我們?cè)赑L/SQL客戶端通過(guò)每個(gè)表的仔細(xì)查閱,終于在view視圖中找到了走全表掃描的表,這下問(wèn)題就可以隨之迎刃而解?
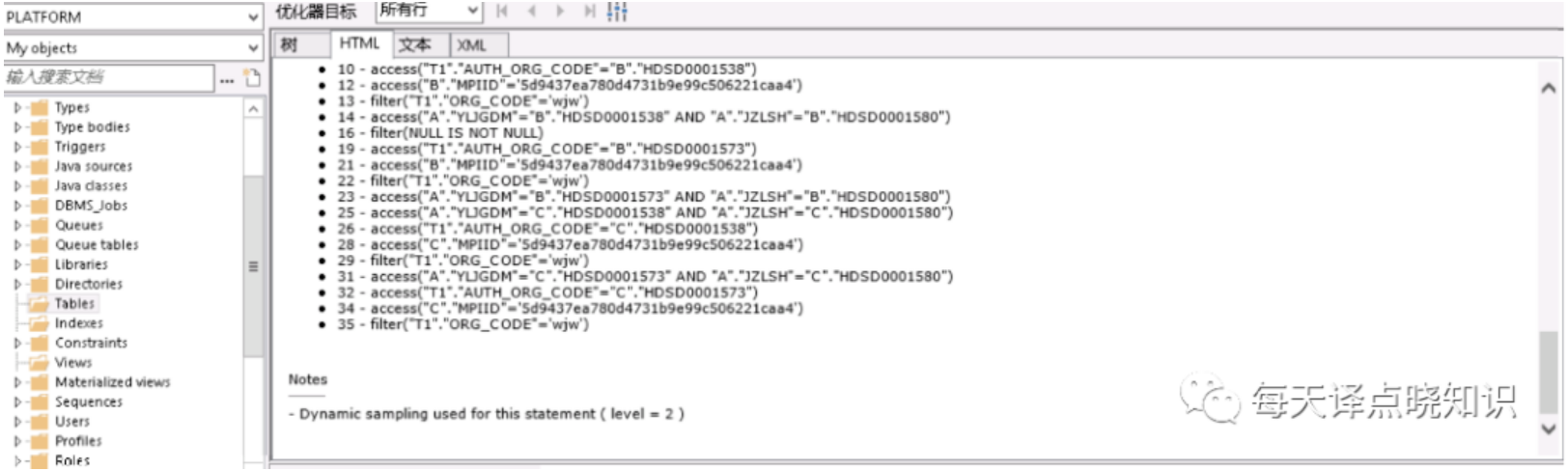
將復(fù)雜的SQL語(yǔ)句作查詢步驟化解-"以大化小,以小化無(wú)",拆解成多個(gè)單步驟SQL片段,對(duì)每個(gè)SQL片段進(jìn)行查詢計(jì)劃分析。但這里可優(yōu)先對(duì)走全表掃描的表作進(jìn)一步排查,分析之后,果然驗(yàn)證了之前的猜想。
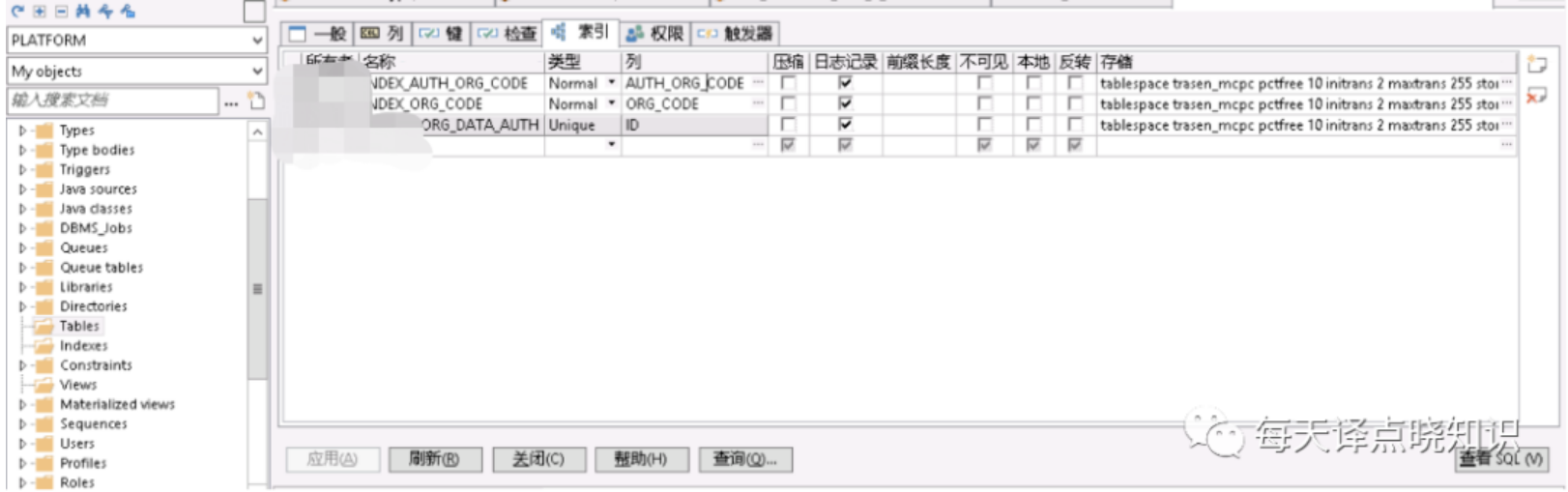
上述全表掃描的表這里分別以A、B表昵稱,在A、B表中分別有兩個(gè)字段作為查詢的條件屬性,其中A表走模糊查詢like '%A'而未命中索引,另一個(gè)B表是走條件查詢未建立索引。針對(duì)上述排查后的結(jié)果,分別對(duì)A表作like 'A%'(可通過(guò)oracle函數(shù)達(dá)到like效果,但模糊匹配,不管是前綴還是后綴最終還是要掃描行數(shù),其實(shí)還是可以更細(xì)粒度的優(yōu)化滴~暫不詳述),對(duì)B表查詢條件字段建立INDEX索引,類型為Normal即可。
重點(diǎn)說(shuō)明:本文重點(diǎn)在各種優(yōu)化的思路,例如百度的搜索引擎,海量數(shù)據(jù)中檢索有時(shí)候也是需要產(chǎn)品作出一部分妥協(xié)的,分頁(yè)限制,滾動(dòng)分頁(yè)等,上千萬(wàn)億級(jí)的數(shù)據(jù)不分庫(kù)分表,可以上ElasticSearch分布式全文搜索引擎,參考->http://www.sunline.cc/db/166356
圖四
Ok,now,我們繼續(xù)看一下select的效果,頁(yè)面正常請(qǐng)求后端服務(wù)接口,完成數(shù)據(jù)加載渲染,頁(yè)面終于跑起來(lái)了,后端服務(wù)接口響應(yīng)耗時(shí)日志打印,也從之前的請(qǐng)求耗時(shí)大幅縮短,繼續(xù)在Oracle客戶端查看執(zhí)行計(jì)劃,也未出現(xiàn)走全表掃描的情況。
四、解決方案:
針對(duì)失效的索引或查詢條件字段未建立的索引,根據(jù)查詢計(jì)劃定位其問(wèn)題及根源,并同時(shí)對(duì)參與條件查詢的字段,調(diào)整并建立合適的索引及類型。
五、反思總結(jié):
當(dāng)然優(yōu)化的點(diǎn)有很多,上述只是通過(guò)查詢計(jì)劃對(duì)索引作了合理的調(diào)整,當(dāng)數(shù)據(jù)量基數(shù)非常之大的時(shí)候,關(guān)系型數(shù)據(jù)庫(kù)可作分庫(kù)分表,非關(guān)系型數(shù)據(jù)庫(kù)可對(duì)數(shù)據(jù)作建模設(shè)計(jì),選取Elastic Search-分布式全文檢索-倒排索引或MongoDb等等,根據(jù)合適的業(yè)務(wù)場(chǎng)景擇優(yōu)選取,具體也可參考小編CSDN博文:
https://blog.csdn.net/yxd179引出這樣一個(gè)小問(wèn)題-思考:當(dāng)你去圖書(shū)館借書(shū)或者書(shū)店的時(shí)候,想必都有用到過(guò)通過(guò)書(shū)的類型,書(shū)的名稱去縮小你需要查找的范圍,那為什么通過(guò)目錄,索引搜索就這么快?什么情況下索引會(huì)失效?Oracle、Mysql、ES索引底層又是怎么實(shí)現(xiàn)的呢?^_^
當(dāng)然,我們也可以在工作之余去看看底層的數(shù)據(jù)結(jié)構(gòu),B樹(shù),B+樹(shù),Hash索引,倒排索引......
在SQL優(yōu)化這一塊,若大家有需要,歡迎在文末留言分享:
根據(jù)大家的需求度,后續(xù)考慮在GitHub上開(kāi)源一款SQL插件,支持插拔式-需要時(shí)開(kāi)啟,可自動(dòng)將復(fù)雜SQL填充參數(shù),打印SQL語(yǔ)句,并打印其執(zhí)行計(jì)劃及耗時(shí),助力于生產(chǎn)環(huán)境分析SQL,排查問(wèn)題,性能優(yōu)化。
引出這樣一個(gè)小案例-思考:
現(xiàn)有這樣一個(gè)場(chǎng)景,在某張單表中數(shù)據(jù)量在1000-2000萬(wàn),怎么樣能夠通過(guò)程序快速把這樣1000-2000萬(wàn)數(shù)據(jù)讀取,并同步到一些其他的大數(shù)據(jù)組件作下一步數(shù)據(jù)分析。
或許這就是一點(diǎn)不一樣的IDEA應(yīng)對(duì)不一樣的場(chǎng)景,深度分頁(yè)越往后,查詢的效率會(huì)下降。
這里也給出Oracle跟MySQL在上千萬(wàn)級(jí)數(shù)據(jù)作深度分頁(yè)優(yōu)化的IDEA:
1、Oracle非主鍵字段實(shí)現(xiàn)自增
select count(*) from yd_info;
(1)alter table yd_info add info_id int;
select * from yd_info;
(2)update yd_info set info_id=rownum;
(3)commit;
select * from yd_info;2、Mysql非主鍵字段實(shí)現(xiàn)自增
(1)先添加字段,設(shè)置字段類型等基本屬性:
alter table yd_info add info_id int(11) not NUll;
(2)為該字段添加任意key:
alter table yd_info ADD KEY `INFO_ID_KEY`(`INFO_ID`);
(3)將該字段修改為自增屬性:
alter table yd_info MODIFY `INFO_ID` int(11) auto_increment;上面就此建立了INFO_ID輔助字段,當(dāng)然索引是需要存儲(chǔ)的,內(nèi)存換時(shí)間,擇優(yōu)選取,當(dāng)你想要設(shè)置的區(qū)間(start,end)跟info_id作判斷即可,想必我們?cè)?/span>SQL分頁(yè)中怎么避免深度分頁(yè)的問(wèn)題啦!
附注:Mark一下之前的思考過(guò)程,堅(jiān)持不易-自我驅(qū)動(dòng),由于時(shí)間等原因,闡述不一定俱全。本文暫時(shí)就到這里。對(duì)于SQL性能調(diào)優(yōu)這塊,方式有很多,希望對(duì)各位讀者,在數(shù)據(jù)庫(kù)SQL問(wèn)題定位過(guò)程中能夠有所幫助,歡迎提出寶貴建議^_^
「 往期文章 」
數(shù)據(jù)庫(kù)在線實(shí)訓(xùn)平臺(tái)-MySQL篇
數(shù)倉(cāng)進(jìn)階 | 記一次OLAP分析引擎演進(jìn)思考過(guò)程
鯤鵬認(rèn)證 | 多數(shù)據(jù)庫(kù)切換之Oracle遷移至MySQL篇
開(kāi)源數(shù)據(jù)庫(kù) | 記一次基于鯤鵬歐拉操作系統(tǒng)openGauss實(shí)踐過(guò)程
MySQL優(yōu)化案例 | 查看SQL語(yǔ)句執(zhí)行計(jì)劃
達(dá)夢(mèng) | 記一次國(guó)產(chǎn)數(shù)據(jù)庫(kù)適配的思考過(guò)程
Elasticsearch讀寫(xiě)數(shù)據(jù)工作原理 | MySQL的重復(fù)數(shù)據(jù)插入處理
Elasticsearch進(jìn)階篇 | 記kibana執(zhí)行dsl腳本實(shí)戰(zhàn)過(guò)程
Kafka | 記一次修復(fù)Kafka分區(qū)所在broker宕機(jī)故障-引發(fā)當(dāng)前分區(qū)不可用的思考過(guò)程
序列化 | Google的Gson與Alibaba的FastJson機(jī)制

