




談到MySQL數(shù)據(jù)庫(kù)表設(shè)計(jì)和SQL優(yōu)化,都會(huì)了解要有索引,可以說(shuō)MySQL就是索引的代名詞。這話(huà)一點(diǎn)都不夸張。MySQL數(shù)據(jù)庫(kù)底層的innodb引擎就是索引組織表。數(shù)據(jù)行的所有操作都是基本主鍵進(jìn)行的。
數(shù)據(jù)庫(kù)中定義的主鍵具備如下特性:
1、任何兩行都不具有相同的主鍵值,保證唯一性。
2、每個(gè)行都必須具有一個(gè)主鍵值(主鍵列不允許NULL值)
目前來(lái)說(shuō)MySQL的處理邏輯都是跟主鍵綁在一起。主鍵的重要度不言而喻。
官方說(shuō)明
表中每一行都應(yīng)該有可以唯一標(biāo)識(shí)自己的一列,當(dāng)沒(méi)有設(shè)置主鍵的時(shí)候MySQL本身會(huì)生成隱藏的列做為主鍵。
-
When you define a PRIMARY KEY on your table, InnoDB uses it as the clustered index. Define a primary key for each table that you create. If there is no logical unique and non-null column or set of columns, add a new auto-increment column, whose values are filled in automatically.
當(dāng)表上定義一個(gè)主鍵時(shí),InnoDB使用它作為聚集索引。如果沒(méi)有邏輯惟一的非空列或列集,則建議添加一個(gè)新的自動(dòng)遞增列,其值將自動(dòng)填充。 -
If you do not define a PRIMARY KEY for your table, MySQL locates the first UNIQUE index where all the key columns are NOT NULL and InnoDB uses it as the clustered index.
如果沒(méi)有為表定義一個(gè)主鍵,MySQL定位第一個(gè)UNIQUE索引,所有的鍵列都不是NULL, InnoDB使用它作為聚集索引。 -
If the table has no PRIMARY KEY or suitable UNIQUE index, InnoDB internally generates a hidden clustered index named GEN_CLUST_INDEX on a synthetic column containing row ID values. The rows are ordered by the ID that InnoDB assigns to the rows in such a table. The row ID is a 6-byte field that increases monotonically as new rows are inserted. Thus, the rows ordered by the row ID are physically in insertion order.
如果該表沒(méi)有PRIMARY KEY或合適的UNIQUE索引,InnoDB內(nèi)部會(huì)在分配給一個(gè)6字節(jié)ID字段,作為隱藏的聚集索引,名為GEN_CLUST_INDEX 。行是按照隱藏ID為主鍵進(jìn)行排序。因此,在插入新行時(shí)單調(diào)增加, 按行ID排序的行在物理上是按插入順序排列的。
備注:聚集索引=主鍵=PRIMAYR KEY
表設(shè)計(jì)和SQL語(yǔ)句中的主鍵
在MySQL數(shù)據(jù)處理中,可以說(shuō)主鍵就是大腦邏輯:
InnoDB引擎使用聚集索引,數(shù)據(jù)記錄本身被存于主索引(一顆B+Tree)的葉子節(jié)點(diǎn)上。
這就要求同一個(gè)葉子節(jié)點(diǎn)內(nèi)(大小為一個(gè)內(nèi)存頁(yè)或磁盤(pán)頁(yè))的各條數(shù)據(jù)記錄按主鍵順序存放,因此每當(dāng)有一條新的記錄插入時(shí),MySQL會(huì)根據(jù)其主鍵將其插入適當(dāng)?shù)墓?jié)點(diǎn)和位置,如果頁(yè)面達(dá)到裝載因子(InnoDB默認(rèn)為15/16),則開(kāi)辟一個(gè)新的頁(yè)(節(jié)點(diǎn))。
MySQL的數(shù)據(jù)結(jié)構(gòu)和普通的查詢(xún)?nèi)缦拢?/p>
#例如創(chuàng)建如下一張表:
mysql> CREATE TABLE users(
id INT NOT NULL,
name VARCHAR(20) NOT NULL,
age INT NOT NULL,
PRIMARY KEY(id)
);
mysql> INSERT INTO users(id,name,age)VALUES(3,'TOM',18),(5,'Bob',21),(7,'Ana',17),(8,'Rex',55),(9,'Toy',35);
#新建一個(gè)以age字段的二級(jí)索引:
mysql>ALTER TABLE users ADD INDEX index_age(age);
mysql>SELECT * FROM users WHERE age=35;
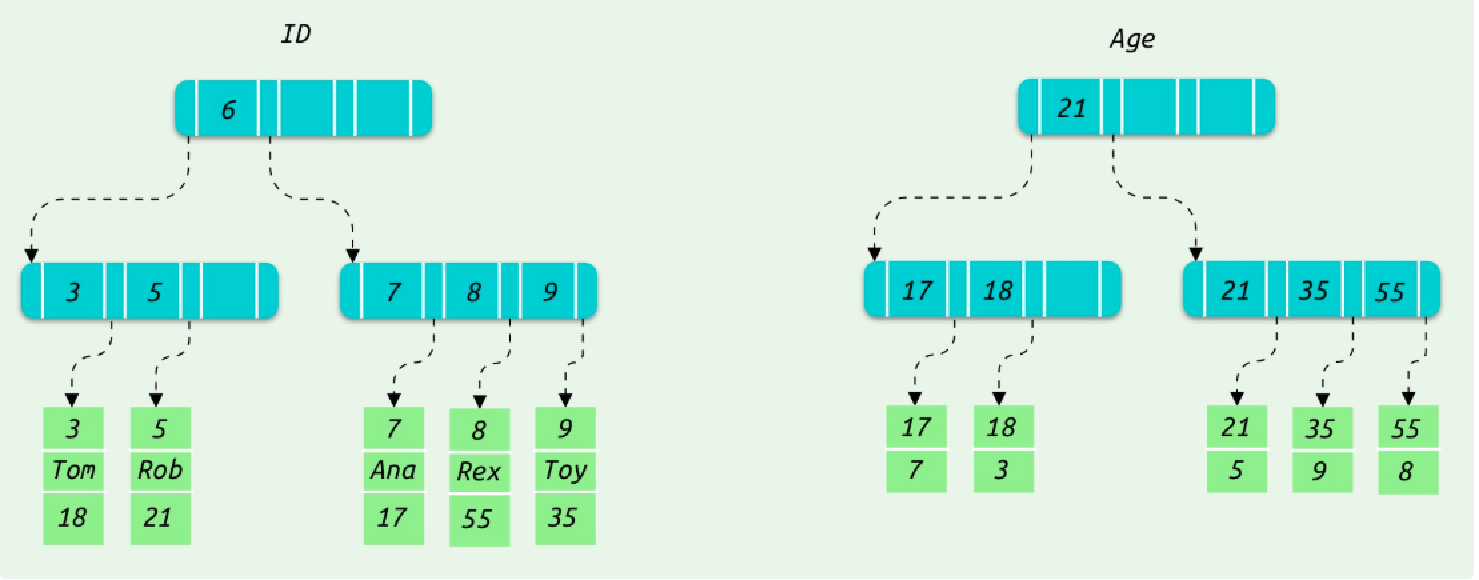
二級(jí)索引的檢索過(guò)程:
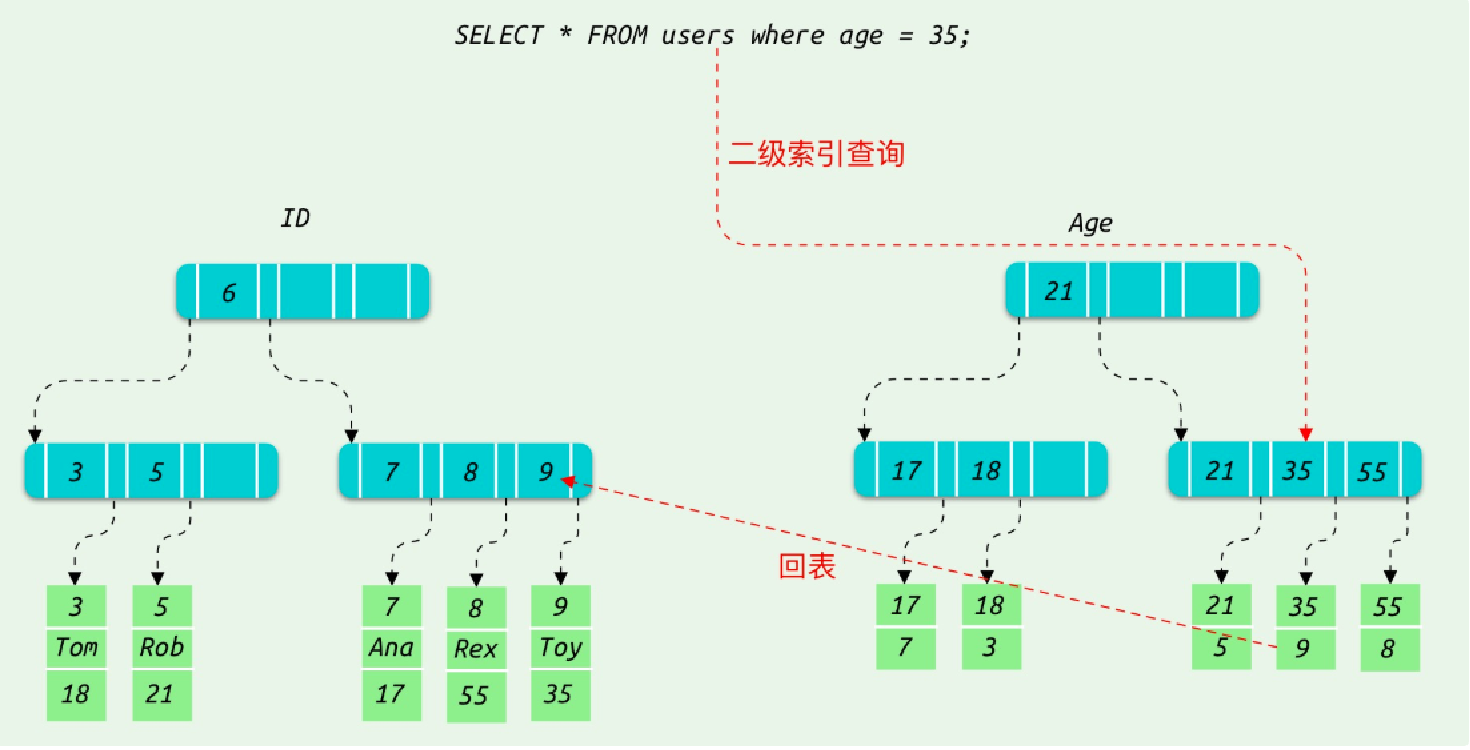
備注:二級(jí)索引是指定字段與主鍵的映射,主鍵長(zhǎng)度越小,普通索引的葉子節(jié)點(diǎn)就越小,二級(jí)索引占用的空間也就越小,所以要避免使用過(guò)長(zhǎng)的字段作為主鍵。
除此之外REPLACE INTO,ON DUPLICATE KEY UPDATE ,第三方mydumper單表邏輯導(dǎo)出并行方式都是依賴(lài)于主鍵或UNIQUE鍵。
高可用復(fù)制模式下主鍵
MySQL復(fù)制是邏輯復(fù)制,雖然有些差異,但等價(jià)于把SQL語(yǔ)句在另一個(gè)節(jié)點(diǎn)執(zhí)行;
1.存在沒(méi)有主鍵的表,導(dǎo)致備庫(kù)應(yīng)用每個(gè)Event 都需要全表掃描,導(dǎo)致大量的延遲。現(xiàn)在了解為什么主從復(fù)制延遲會(huì)經(jīng)常碰到。
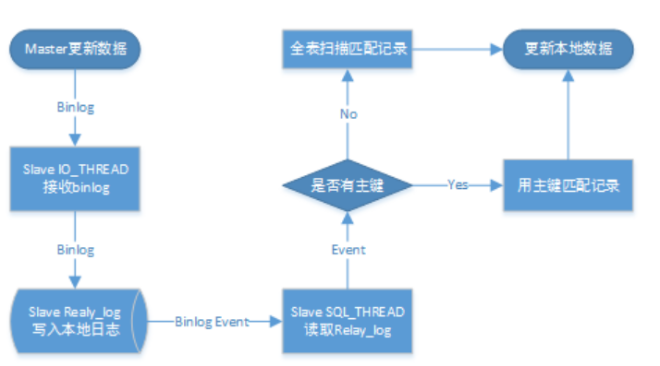
2.MGR里主鍵的必要性
要被組復(fù)制的每個(gè)表都必須有一個(gè)定義好的主鍵,或者一個(gè)等效的主鍵,其中等效的主鍵是一個(gè)非空的唯一鍵。這樣的鍵作為表中每一行的唯一標(biāo)識(shí)符是必需的,這樣系統(tǒng)就可以通過(guò)準(zhǔn)確地識(shí)別每個(gè)事務(wù)修改哪些行來(lái)確定哪些事務(wù)發(fā)生了沖突。
應(yīng)該選擇什么樣主鍵
MySQL數(shù)據(jù)結(jié)構(gòu)中理想狀態(tài)下主鍵是什么樣?
1、不更新主鍵列的值
2、不重用主鍵列的值
3、不在主鍵列中使用可能會(huì)更改的值
4、字段長(zhǎng)度需要控制好,避免索引也頻繁的分裂合并
1.自增主鍵
無(wú)特殊需求下Innodb建議使用與業(yè)務(wù)無(wú)關(guān)的自增ID作為主鍵:
1、如果表使用自增主鍵,以利于插入性能的提高。那么每次插入新的記錄,記錄就會(huì)順序添加到當(dāng)前索引節(jié)點(diǎn)的后續(xù)位置,當(dāng)一頁(yè)寫(xiě)滿(mǎn),就會(huì)自動(dòng)開(kāi)辟一個(gè)新的頁(yè)這樣就會(huì)形成一個(gè)緊湊的索引結(jié)構(gòu),近似順序填滿(mǎn)。由于每次插入時(shí)也不需要移動(dòng)已有數(shù)據(jù),因此效率很高,也不會(huì)增加很多開(kāi)銷(xiāo)在維護(hù)索引上。

自增型主鍵設(shè)計(jì)(int,bigint)可以降低二級(jí)索引的空間,提升二級(jí)索引的內(nèi)存命中率;
自增型的主鍵可以減小page的碎片,提升空間和內(nèi)存的使用;
2、 如果使用非自增主鍵(如果身份證號(hào),機(jī)構(gòu)唯一代碼等),由于每次插入主鍵的值近似于隨機(jī),因此每次新紀(jì)錄都要被插到現(xiàn)有索引頁(yè)得中間某個(gè)位置
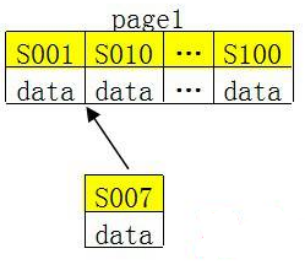
MySQL不得不為了將新記錄插到合適位置而移動(dòng)數(shù)據(jù),甚至目標(biāo)頁(yè)面可能已經(jīng)被回寫(xiě)到磁盤(pán)上而從緩存中清掉,此時(shí)又要從磁盤(pán)上讀回來(lái),這增加了很多開(kāi)銷(xiāo),同時(shí)頻繁的移動(dòng)、分頁(yè)操作造成了大量的碎片,得到了不夠緊湊的索引結(jié)構(gòu),后續(xù)不得不通過(guò)OPTIMIZE TABLE來(lái)重建表并優(yōu)化填充頁(yè)面。
3.使用自增長(zhǎng)做主鍵的優(yōu)缺點(diǎn):
-
優(yōu)點(diǎn)
1、很小的數(shù)據(jù)存儲(chǔ)空間
2、性能最好
3、容易緩存 -
缺點(diǎn)
1、如果存在大量的數(shù)據(jù),可能會(huì)超出自增長(zhǎng)的取值范圍。
2、可能不是連續(xù)的。5.7版本bug 重新啟動(dòng),自增序列丟失問(wèn)題
3、沒(méi)有業(yè)務(wù)意義
4、很難處理分布式存儲(chǔ)的數(shù)據(jù)表,尤其是需要合并表的情況下會(huì)存在沖突。
5、安全性低,因?yàn)槭怯幸?guī)律的,容易被非法獲取數(shù)據(jù)。
2.UUID生成的主鍵
UUID是Universally Unique Identifier的縮寫(xiě),它是在一定的范圍內(nèi)(從特定的名字空間到全球)唯一的機(jī)器生成的標(biāo)識(shí)符
- 經(jīng)由一定的算法機(jī)器生成為了保證UUID的唯一性,規(guī)范定義了包括網(wǎng)卡MAC地址、時(shí)間戳、名字空間(Namespace)、隨機(jī)或偽隨機(jī)數(shù)、時(shí)序等元素,以及從這些元素生成UUID的算法。
- 非人工指定,非人工識(shí)別
UUID是不能人工指定的。UUID的復(fù)雜性決定了“一般人“不能直接從一個(gè)UUID知道哪個(gè)對(duì)象和它關(guān)聯(lián)。 - 在特定的范圍內(nèi)重復(fù)的可能性極小
UUID的生成規(guī)范定義的算法主要目的就是要保證其唯一性。但這個(gè)唯一性是有限的,只在特定的范圍內(nèi)才能得到保證. - UUID通常以36字節(jié)的字符串表示,示例如下:3F2504E0-4F89-11D3-9A0C-0305E82C3301
- 時(shí)間戳+UUID版本號(hào),分三段占16個(gè)字符(60bit+4bit),
- Clock Sequence號(hào)與保留字段,占4個(gè)字符(13bit+3bit),
- 節(jié)點(diǎn)標(biāo)識(shí)占12個(gè)字符(48bit)
UUID 去除“-”: 32字節(jié),但對(duì)于mysql 來(lái)說(shuō)還是字段太長(zhǎng),字段基本無(wú)意義。
使用UUID做主鍵的優(yōu)點(diǎn):
1、出現(xiàn)重復(fù)的機(jī)會(huì)基本無(wú)
2、分布式環(huán)境下適合大量數(shù)據(jù)中的插入和更新操作
3、跨服務(wù)器數(shù)據(jù)合并非常方便
4、安全性較高
使用UUID做主鍵的缺點(diǎn):
1、存儲(chǔ)空間大(16 byte),因此它將會(huì)占用更多的磁盤(pán)空間
2、會(huì)降低性能
3、無(wú)法緩存大量數(shù)據(jù)
4、由于每次插入主鍵的值近似于隨機(jī),因此每次新紀(jì)錄都要被插到現(xiàn)有索引頁(yè)得中間某個(gè)位置,此時(shí)MySQL不得不為了將新記錄插到合適位置而移動(dòng)數(shù)據(jù),甚至目標(biāo)頁(yè)面可能已經(jīng)被回寫(xiě)到磁盤(pán)上而從緩存中清掉,此時(shí)又要從磁盤(pán)上讀回來(lái),這增加了很多開(kāi)銷(xiāo),同時(shí)頻繁的移動(dòng)、分頁(yè)操作造成了大量的碎片,得到了不夠緊湊的索引結(jié)構(gòu),后續(xù)不得不通過(guò)OPTIMIZE TABLE來(lái)重建表并優(yōu)化填充頁(yè)面。
5、對(duì)于更新UUID操作:UUID的無(wú)序和空間占的大小導(dǎo)致插入時(shí)候要耗費(fèi)更多的時(shí)間去創(chuàng)建和維護(hù)索引
下面介紹下雪花算法:
SnowFlake算法介紹:
SnowFlake算法生成id的結(jié)果是一個(gè)64bit大小的整數(shù),它的結(jié)構(gòu)如下圖:
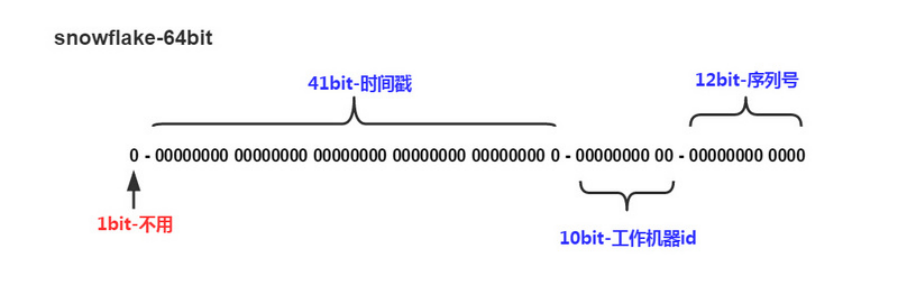

通過(guò)多從了解和收集信息: Twitter分布式自增ID算法snowflake算法生成id:Long類(lèi)型占8個(gè)字
snowflake算法的好處:
- 生成的id是一個(gè)數(shù)字的Long類(lèi)型
- 無(wú)需鏈接數(shù)據(jù)庫(kù)或者redis,超高性能
snowflake算法的弊端:
- 每毫秒只能生成4096個(gè)id(內(nèi)理論上最多可以生成1000*(2^12),也就是409.6萬(wàn)個(gè)ID)。
隨著cpu不斷的進(jìn)步,每毫秒4096個(gè)id將不能滿(mǎn)足。
可以不用擔(dān)心,即便cpu性能超過(guò)了這個(gè)值,那么只需等待到下一個(gè)毫秒 - 每毫秒重新計(jì)數(shù),空閑時(shí)間會(huì)浪費(fèi)很多id空間。
-系統(tǒng)時(shí)間不可回退,回退將會(huì)導(dǎo)致id重復(fù)。另:系統(tǒng)時(shí)間可以前進(jìn),不受影響。
為了保證唯一性,業(yè)務(wù)UUID生成方式SnowFlake算法生成id:
SnowFlake算法生成Long類(lèi)型占8個(gè)字節(jié) 可在前面加2個(gè)類(lèi)型的業(yè)務(wù)字段
業(yè)務(wù)UUID=Long類(lèi)型占8個(gè)字節(jié)+ 2個(gè)英文字節(jié)( 20個(gè)長(zhǎng)度的UUID)
業(yè)務(wù)UUID=UUID去除”-”+ 2個(gè)英文字節(jié)( 32個(gè)長(zhǎng)度的UUID)
3.業(yè)務(wù)含義的主鍵
通過(guò)架構(gòu)規(guī)劃定義的主鍵,應(yīng)該是最有效的,利用率最高的。
比如訂單方式:
地區(qū)+UNIX_TIMESTAMP+產(chǎn)品編號(hào)+隨機(jī)號(hào):SH+1637416219+P23+05
綜合考慮建議使用業(yè)務(wù)主鍵,如uuid和自增主鍵使用的建議如下:
1、單實(shí)例下 ,并且數(shù)據(jù)量比較大(百萬(wàn)級(jí))時(shí),用自增長(zhǎng)的,此時(shí)最好能考慮下安全性,做些安全措施。
2、單實(shí)例下,并且數(shù)據(jù)量沒(méi)那么大,對(duì)速度和存儲(chǔ)要求不高時(shí),用UUID。
3、分布式的,那么首選UUID,分布式一般對(duì)速度和存儲(chǔ)要求不高。
4、分布式的,并且數(shù)據(jù)量達(dá)到千萬(wàn)級(jí)別可更高時(shí),對(duì)速度和存儲(chǔ)有要求時(shí),可以用自增長(zhǎng)。
總結(jié)
總之主鍵對(duì)于MySQL來(lái)說(shuō),是非常重要的,每張表的設(shè)計(jì)的時(shí),都應(yīng)該把主鍵默認(rèn)的加上,不管需不需要它。無(wú)主鍵的時(shí)候 可以選擇自增型的主鍵。一個(gè)表必須要有一個(gè)主鍵,為方便擴(kuò)展、松耦合,高可用的系統(tǒng)做鋪墊。
①可以使用自增加主鍵 ID bigint(20) unsigned NOT NULL AUTO_INCREMENT,
②直接使用uuid
③按照業(yè)務(wù)考慮,自定義主鍵。 (snowflake+業(yè)務(wù)id)
④自定義有業(yè)務(wù)意義的主鍵
