




Oracle表連接類型:
一、嵌套查詢
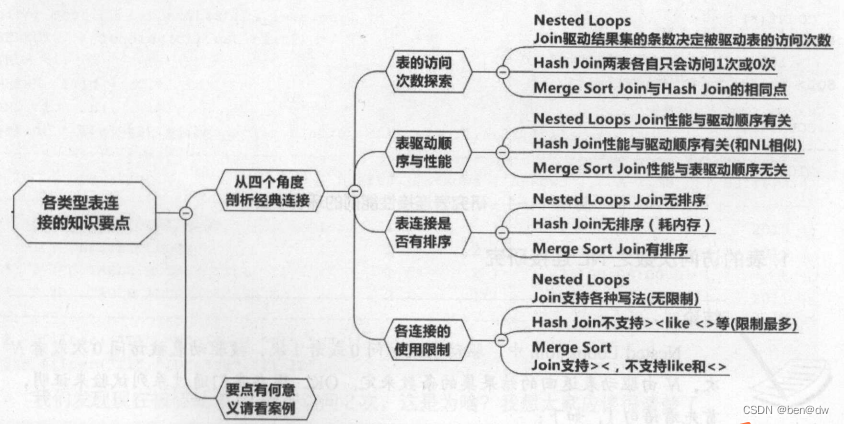
嵌套循環(huán)的算法:在嵌套循環(huán)連接中,有驅(qū)動(dòng)順序,驅(qū)動(dòng)表返回多少條記錄,被驅(qū)動(dòng)表就訪問(wèn)多少次,嵌套循環(huán)連接中無(wú)須排序。
嵌套循環(huán)可以快速返回兩表關(guān)聯(lián)的前幾條數(shù)據(jù),如果SQL中添加了HINT:FIRST_ROWS,在兩表關(guān)聯(lián)的時(shí)候,優(yōu)化器更傾向于嵌套循環(huán)。
在嵌套循環(huán)連接,要特別注意驅(qū)動(dòng)表的順序,小的結(jié)果集先訪問(wèn),大的結(jié)果集后訪問(wèn),才能保證被驅(qū)動(dòng)表的訪問(wèn)次數(shù)降到最低,從而提升性能。當(dāng)兩表使用外連接進(jìn)行關(guān)聯(lián),如果執(zhí)行計(jì)劃是走嵌套循環(huán),那么這時(shí)無(wú)法更改驅(qū)動(dòng)表,驅(qū)動(dòng)表將會(huì)被固定在主表。
驅(qū)嵌套循環(huán)被驅(qū)動(dòng)表必須走索引。如果嵌套循環(huán)被驅(qū)動(dòng)表的連接列沒(méi)有包含在索引中,那么被驅(qū)動(dòng)表只能走全表掃描,而且是反復(fù)多次全表掃描。當(dāng)被驅(qū)動(dòng)表很大時(shí),SQL就執(zhí)行不出結(jié)果。
嵌套循環(huán)被驅(qū)動(dòng)表走索引只能走INDEX UNIQUE SCAN和INDEX RANGE SCAN。嵌套循環(huán)被驅(qū)動(dòng)表不能走TABLE ACCESS FULL,不能走INDEX FULL SCAN,不能走INDEX SKIP SCAN,也不能走INDEX FAST FULL SCAN。
嵌套循環(huán)查詢HINT用法:/+leading(t1) use_nl(t2)/,其中t1為驅(qū)動(dòng)表,t2為被驅(qū)動(dòng)表
SELECT /+leading(t1) use_nl(t2)/ * FROM T1 INNER JOIN ON T1.ID = T2.ID
嵌套連接沒(méi)有連接條件限制
1、兩表關(guān)聯(lián)走不走NL是看兩個(gè)表關(guān)聯(lián)之后返回的數(shù)據(jù)量多少?還是看驅(qū)動(dòng)表返回的數(shù)據(jù)量多少?
如果兩個(gè)表是1:N關(guān)系,驅(qū)動(dòng)表位1,被驅(qū)動(dòng)表為N并且N很大,這時(shí)即使驅(qū)動(dòng)表返回?cái)?shù)據(jù)量很少,也不能嵌套循環(huán),因?yàn)閮杀黻P(guān)聯(lián)之后返回的數(shù)據(jù)量會(huì)很多。所以判斷兩個(gè)表關(guān)聯(lián)是否應(yīng)該走NL應(yīng)該直接查看兩個(gè)表關(guān)聯(lián)之后返回的數(shù)據(jù)量,如果兩個(gè)表關(guān)聯(lián)之后返回的數(shù)據(jù)量少(比如少于萬(wàn)行),可以走NL;返回的數(shù)據(jù)量多(比如大于萬(wàn)行)。應(yīng)該走HASH連接。
2、大表是否可以當(dāng)嵌套循環(huán)(NL)驅(qū)動(dòng)表?
可以,大表過(guò)濾之后返回的數(shù)據(jù)量很少就可以充當(dāng)NL驅(qū)動(dòng)表
3、select * from a inner join b on a.id = b.id;如果a有100條數(shù)據(jù),b表有100萬(wàn)行數(shù)據(jù),a與b是1:N關(guān)系,N很低,應(yīng)該怎么優(yōu)化SQL?
因?yàn)閍與b是1:N關(guān)系,N很低,可以在b的連接列(ID)上創(chuàng)建索引。讓a與b走嵌套循環(huán)(a nl b),這樣b表會(huì)被掃描100次,但是每次掃描走表的時(shí)候走的是id列的索引(范圍掃描)。如果讓a與b進(jìn)行hash連接,b表會(huì)被全表掃描(因?yàn)闆](méi)有過(guò)濾條件),需要查詢表中的100萬(wàn)數(shù)據(jù),而如果讓a和b進(jìn)行嵌套循環(huán),b表只需要查詢出表中最多幾百行數(shù)據(jù)(100*N)。一般情況下,一個(gè)小表與一個(gè)大表關(guān)聯(lián),可以考慮小表NL大表,大表走連接列索引(如果大表有過(guò)濾條件,需要將過(guò)濾條件與連接列組合起來(lái)創(chuàng)建組合索引),從而避免大表被全表掃描。
當(dāng)a與b是1:N關(guān)系,N非常大(比如幾十萬(wàn)),SQL執(zhí)行不出結(jié)果。主要是a與b關(guān)聯(lián)后返回大量數(shù)據(jù),因?yàn)榉祷亟Y(jié)果集太多,被驅(qū)動(dòng)表走索引,也就是說(shuō)該SQL可能是被驅(qū)動(dòng)表走索引返回大量數(shù)據(jù)導(dǎo)致的性能問(wèn)題。這時(shí)就不能走嵌套循環(huán)了,只能走HASH連接,于是用HINT:USE_HASH(A,B)。所以一般來(lái)說(shuō)看到SQL中有distinct ,group by ,count,分析函數(shù),一定要走HASH。因?yàn)橐话阌羞@些語(yǔ)句,它返回的結(jié)果集都非常大。
4、DBLINK永遠(yuǎn)不能作為NL的被驅(qū)動(dòng)表。
二、哈希連接
兩表關(guān)聯(lián)返回少量數(shù)據(jù)應(yīng)該走嵌套循環(huán),兩表關(guān)聯(lián)返回大量數(shù)據(jù)應(yīng)該走HASH連接。
HASH連接的算法:兩表等值關(guān)聯(lián),返回大量數(shù)據(jù),將較小的表選為驅(qū)動(dòng)表,將驅(qū)動(dòng)表的“SELECT列和JOIN列”讀入PGA中的WORK AREA,然后對(duì)驅(qū)動(dòng)表的連接列進(jìn)行hash運(yùn)算生成hash table,當(dāng)驅(qū)動(dòng)表的所有數(shù)據(jù)完全讀入PGA中的WORK AREA之后,再讀取被驅(qū)動(dòng)表(被驅(qū)動(dòng)表不需要讀入PGA中的WORK AREA中),對(duì)被驅(qū)動(dòng)表的連接列也進(jìn)行hash運(yùn)算,然后到PGA中的WORK AREA去探測(cè)hash table,找到數(shù)據(jù)就關(guān)聯(lián)上,找不到數(shù)據(jù)就沒(méi)關(guān)聯(lián)上。
在HASH連接中,有驅(qū)動(dòng)順序, 驅(qū)動(dòng)表和被驅(qū)動(dòng)表都只會(huì)訪問(wèn)0次或者1次
在HASH連接中,無(wú)須排序,消耗PGA內(nèi)存是因?yàn)橛糜诮ASH表,當(dāng)驅(qū)動(dòng)表太大、PGA不能完全容納驅(qū)動(dòng)表時(shí),驅(qū)動(dòng)表就會(huì)溢出到臨時(shí)表空間,進(jìn)而產(chǎn)生磁盤HASH連接,這時(shí)候HASH連接性能會(huì)嚴(yán)重下降。
嵌套循環(huán)每循環(huán)一次,會(huì)將驅(qū)動(dòng)表連接列傳值給被驅(qū)動(dòng)表的連接列,也就是說(shuō)嵌套循環(huán)會(huì)進(jìn)行傳值。HASH連接沒(méi)有傳值的過(guò)程列在進(jìn)行HASH連接的時(shí)候,被驅(qū)動(dòng)表的連接列會(huì)產(chǎn)生HASH值,到PGA中去探測(cè)驅(qū)動(dòng)表所生成的hash table。HASH連接的驅(qū)動(dòng)表與被驅(qū)動(dòng)表的連接列都不需要?jiǎng)?chuàng)建索引。
OLAP環(huán)境多數(shù)SQL都是大規(guī)模的ETL,此類SQL返回的結(jié)果集很多,SQL執(zhí)行計(jì)劃通常以HASH為主,往往要大量消耗PGA,所以O(shè)LAP系統(tǒng)PGA設(shè)置較大。
在HASH連接 連接要特別注意驅(qū)動(dòng)表的順序,小的結(jié)果集先訪問(wèn),大的結(jié)果集后訪問(wèn),才能保證被驅(qū)動(dòng)表的訪問(wèn)次數(shù)降到最低,從而提升性能。
嵌套循環(huán)查詢HINT用法:/+leading(t1) use_hash(t2)/,其中t1為驅(qū)動(dòng)表,t2為被驅(qū)動(dòng)表
SELECT /+leading(t1) use_hash(t2)/ * FROM T1 INNER JOIN ON T1.ID = T2.ID。
HASH連接主要用于處理兩表等值關(guān)聯(lián)
不支持HASH連接的連接條件:連接條件是<> > <或者LIKE導(dǎo)致HASH連接無(wú)法使用
1、怎么優(yōu)化HASH連接
(1)因?yàn)镠ASH連接需要將驅(qū)動(dòng)表的select列和join列放入PGA中,所以,應(yīng)該盡量避免書寫select * from …語(yǔ)句,將需要的列放在select list中,這樣可以減少驅(qū)動(dòng)表對(duì)PGA的占用,避免驅(qū)動(dòng)表被溢出到臨時(shí)表空間,從而提升性能。如果無(wú)法避免驅(qū)動(dòng)表被溢出到臨時(shí)表空間,可以將臨時(shí)表空間創(chuàng)建在SSD上面或者RAID 0上,加快臨時(shí)數(shù)據(jù)的交換速度。
(2)HASH連接驅(qū)動(dòng)表看什么,看體積還是看行數(shù)?HASH看體積,NL看行數(shù)。HASH看體積,因?yàn)镠ASH是要全部放內(nèi)存的。HASH因?yàn)閱蝹€(gè)進(jìn)程最大2G,所以要看體積。
(3)HASH連接驅(qū)動(dòng)表非常大怎么優(yōu)化?開(kāi)并行,并行之后就不是一個(gè)進(jìn)程在HASH。
2、HASH連接需要注意地方
(1)HASH JOIN在OLTP環(huán)境一般沒(méi)有什么優(yōu)化的地方,在OLAP環(huán)境中可以利用并行優(yōu)化HASH JOIN。
(2)利用等待事件監(jiān)控HASH JOIN的時(shí)候,如果發(fā)現(xiàn)在做on-disk HASH JOIN(direct path read/write temp),可以加大PGA,或者手工設(shè)置work area分配較大的PGA內(nèi)存。
(3)在做SQL優(yōu)化的時(shí)候,你要檢查HASH JOIN的JOIN列(通過(guò)HASH JOIN前面的ID去找ACCESS)選擇性很低,那么HASH JOIN可能跑很久,這個(gè)時(shí)候可以嘗試構(gòu)造偽列進(jìn)行JOIN,如果無(wú)法構(gòu)造偽列,這個(gè)時(shí)候看看能否從業(yè)務(wù)上優(yōu)化,就不要想著SQL優(yōu)化了。
(4)HASH JOIN選擇小表做驅(qū)動(dòng)表,小表指的不是表的行數(shù),而是指的是行數(shù)*列寬度。
(5)HASH JOIN只能用于等值連接。
3、一般看到SQL里面有什么要走h(yuǎn)ash join ?
答:一般看到group by,sum,avg,max,min,distinct,count 就要走h(yuǎn)ash join,注意這是一般情況下
三、排序合并連接
排序合并連接算法:兩表關(guān)聯(lián),先對(duì)兩個(gè)表根據(jù)連接列進(jìn)行排序,將較小的表作為驅(qū)動(dòng)表(Oracle官方認(rèn)為排序合并連接沒(méi)有驅(qū)動(dòng)表),然后從驅(qū)動(dòng)表中取出連接列的值,到已經(jīng)排好序的被驅(qū)動(dòng)表中匹配數(shù)據(jù),如果匹配上數(shù)據(jù),就關(guān)聯(lián)成功。驅(qū)動(dòng)表返回多少行,被驅(qū)動(dòng)表就要被匹配多少次,這個(gè)匹配過(guò)程類似嵌套循環(huán),但是嵌套循環(huán)是從被驅(qū)動(dòng)表的索引中匹配數(shù)據(jù),而排序合并連接是在內(nèi)存中(PGA中的work area)匹配數(shù)據(jù)。
在排序合并連接中,根本沒(méi)有驅(qū)動(dòng)和被驅(qū)動(dòng)的概念,而嵌套循環(huán)連接和HASH連接要考慮驅(qū)動(dòng)和被驅(qū)動(dòng)的情況,在排序合并連接中,需要排序。
如果兩表是等值關(guān)聯(lián),一般不建議走排序合并連接,因?yàn)榕判蚝喜⑦B接需要將兩個(gè)表放入PGA中,而HASH連接只需要將驅(qū)動(dòng)表放入PGA中,排序合并連接與HASH連接相比,需要耗費(fèi)更多的PGA。即使排序合并連接中有一個(gè)表走的是INDEX FULL SCAN,另外一個(gè)表也需要放入PGA中,而這個(gè)表往往是大表,如果走HASH連接,大表會(huì)作為被驅(qū)動(dòng)表,是不會(huì)被放入PGA中的。因此,兩表等值關(guān)聯(lián),要么走NL(返回?cái)?shù)據(jù)量少),要么走HASH(返回?cái)?shù)據(jù)量多),一般情況下不要走SMJ。
排序合并連接HINT用法:/+ordered use_merge(t2)/
SELECT /+ordered use_merge(t2)/ * FROM T1 INNER JOIN ON T1.ID = T2.ID
表T1和被表T2都只會(huì)訪問(wèn)0次或者1次
不支持排序合并連接的連接條件:連接條件是instr、LIKE、substr、regexp_like排序合并連接無(wú)法使用,連接條件是instr、LIKE、substr、regexp_like只能走嵌套循環(huán)
支持排序合并連接的連接條件:支持>、>=和<、<=、<>之類的連接條件。
哈希連接和排序合并連接簡(jiǎn)單的優(yōu)化思路是:不要取多余的字段參與排序,也就是說(shuō)不要select查詢多余的字段
1、怎么優(yōu)化排序合并連接?
如果兩表關(guān)聯(lián)是等值關(guān)聯(lián),走的是排序合并連接,可以將表連接方式改為HASH連接。如果兩表關(guān)聯(lián)是非等值關(guān)聯(lián),比如>,>=,<,<=,<>,這時(shí)應(yīng)該從業(yè)務(wù)下手,嘗試將非等值關(guān)聯(lián)改寫成等值關(guān)聯(lián),因?yàn)榉堑戎店P(guān)聯(lián)返回的結(jié)果集“類似”于笛卡爾積,當(dāng)兩個(gè)表都比較大的時(shí)候,非等值關(guān)聯(lián)返回的數(shù)據(jù)量相當(dāng)“恐怖”。如果沒(méi)有辦法將非等值關(guān)聯(lián)改寫為等值關(guān)聯(lián),可以考慮增加兩表的現(xiàn)在條件,將兩個(gè)表數(shù)據(jù)量縮小,最后可以考慮開(kāi)啟并行查詢加快SQL執(zhí)行速度。返回大量數(shù)據(jù),最好走h(yuǎn)ash,但是hash有個(gè)缺陷就是只能等值連接。排序合并連接就是為了解決非等值關(guān)聯(lián),并行返回?cái)?shù)據(jù)量大的情況。
四、笛卡爾連接(CARTESIAN JOIN)
笛卡爾連接算法:兩個(gè)表沒(méi)有連接條件的時(shí)候就會(huì)產(chǎn)生笛卡爾兒積,這種連接方式就叫笛卡爾連接。
在多表關(guān)聯(lián)的時(shí)候,兩個(gè)表沒(méi)有直接關(guān)聯(lián)條件,但是優(yōu)化器錯(cuò)誤地把某個(gè)表返回的ROWS算為1行(注意必須是1行),這個(gè)時(shí)候也可能發(fā)生笛卡爾連接。
1、當(dāng)執(zhí)行計(jì)劃有笛卡爾連接應(yīng)該怎么優(yōu)化?
首先應(yīng)該檢查表是否有關(guān)聯(lián)條件,如果表沒(méi)有關(guān)聯(lián)條件,那么應(yīng)該詢問(wèn)開(kāi)發(fā)與業(yè)務(wù)人員為何表沒(méi)有關(guān)聯(lián)條件,是否為了滿足業(yè)務(wù)需求而故意不寫關(guān)聯(lián)條件。
其次應(yīng)該檢查離笛卡爾連接最近的表是否真的返回1行數(shù)據(jù),如果返回行數(shù)真的只有1行,那么走笛卡爾連接是沒(méi)有問(wèn)題的,如果返回行數(shù)超過(guò)1行,那就需要檢查為什么Rows會(huì)估算錯(cuò)誤(一般是表統(tǒng)計(jì)信息沒(méi)有收集,導(dǎo)致ROWS估算錯(cuò)誤),同時(shí)糾正錯(cuò)誤的ROWS, 糾正錯(cuò)誤的ROWS之后,優(yōu)化器就不會(huì)走笛卡爾連接了。
五、標(biāo)量子查詢(SCALAR SUBQUERY)
標(biāo)量子查詢算法:當(dāng)一個(gè)子查詢介于select與from之間,這種子查詢叫標(biāo)量子查詢。
標(biāo)量子查詢類似一個(gè)天然的嵌套循環(huán),而且驅(qū)動(dòng)表固定為主表。嵌套循環(huán)被驅(qū)動(dòng)表的連接列必須包含在索引中。同理,標(biāo)量子查詢中子查詢的表連接列也必須包含在索引中。
在工作中,盡量避免使用標(biāo)量子查詢,假如主表返回大量數(shù)據(jù),主表的連接列基數(shù)很高,那么子查詢中的表會(huì)被多次掃描,從而嚴(yán)重影響SQL性能。如果主表數(shù)據(jù)量小或者主表的連接列基數(shù)很低,那么這個(gè)時(shí)候也可以用標(biāo)量子查詢,但是記住要給子查詢中的連接列建立索引。
當(dāng)SQL里面有標(biāo)量子查詢,可以將標(biāo)量子查詢等價(jià)改寫成外連接,從而可以進(jìn)行HASH連接。
六、半連接(SEMI JOIN)
半連接算法:兩個(gè)表關(guān)聯(lián)只返回一個(gè)表的數(shù)據(jù)就叫半連接。半連接一般就是指的IN和EXISTS。半連接優(yōu)化最為復(fù)雜
SELECT * FROM SCOTT.DEPT WHERE DEPTNO IN (SELECT DEPTNO FROM SCOTT.EMP);
SELECT * FROM SCOTT.DEPT S WHERE EXISTS (SELECT 1 FROM SCOTT.EMP T WHERE S.DEPTNO = T.DEPTNO);
IN和EXISTS可以等價(jià)改寫為內(nèi)連接。
SELECT S.*
FROM SCOTT.DEPT S
INNER JOIN (SELECT DEPTNO FROM SCOTT.EMP T GROUP BY DEPTNO) E
ON S.DEPTNO = E.DEPTNO
在將半連接改寫為內(nèi)連接的時(shí)候,要注意主表與子表(子查詢的表)的關(guān)系。
(1)如果半連接中主表屬于1的關(guān)系,子表(子查詢的表)屬于N的關(guān)系,在改寫為內(nèi)連接的時(shí)候,子表需要加上group by 去重。注意:這個(gè)時(shí)候半連接性能高于內(nèi)連接。
(2)如果半連接中主表屬于N的關(guān)系,子表(子查詢的表)屬于1的關(guān)系,在改寫為內(nèi)連接的時(shí)候,子表就不需要去重了。注意:這個(gè)時(shí)候半連接與內(nèi)連接性能一樣。
(3)如果半連接中主表屬于N的關(guān)系,子表(子查詢的表)屬于N的關(guān)系,這個(gè)時(shí)候可以先對(duì)子表去重,將子表轉(zhuǎn)化為1的關(guān)系,然后再關(guān)聯(lián),千萬(wàn)不能先關(guān)聯(lián)再去重。
SELECT /+LEADING(S@A) USE_NL(S@A,T)/
GCODE, NAME, IDCODE
FROM ZHXX_LGY.LY_T_CHREC T
WHERE GCODE IN (SELECT /+QB_NAME(A)/
GCODE
FROM ZHXX_LGY.LY_T_CHREC S
WHERE NAME = ‘張三’
AND BDATE = ‘19941109’)
為何不寫HINT/+use_nl(s,t) leading(s)/,因?yàn)镺racle數(shù)據(jù)庫(kù)中,每個(gè)子查詢都會(huì)自動(dòng)生成一個(gè)查詢塊(query block),子查詢里面的表會(huì)自動(dòng)地被優(yōu)化器取別名,在子查詢中,HINT寫成use_nl(s,t)會(huì)導(dǎo)致CBO無(wú)法識(shí)別LY_T_CHREC表,為了讓CBO識(shí)別到LY_T_CHREC表,在子查詢中添加了qb_name這個(gè)HINT,給子查詢?nèi)e名A。
七、反半連接(ANTI JOIN)
反半連接算法:兩表關(guān)聯(lián)只返回主表的數(shù)據(jù),而且只返回主表與子表沒(méi)有關(guān)聯(lián)上的數(shù)據(jù),這種連接就叫反連接。反連接一般就是指NOT IN 和 NOT EXISTS。
SELECT * FROM SCOTT.DEPT WHERE DEPTNO NOT IN (SELECT DEPTNO FROM SCOTT.EMP);
SELECT * FROM SCOTT.DEPT S WHERE NOT EXISTS (SELECT 1 FROM SCOTT.EMP T WHERE S.DEPTNO = T.DEPTNO);
需要注意的是,NOT IN里面如果有NULL,整個(gè)查詢會(huì)返回空,而IN里面有NULL,查詢不受NULL影響。所以在將NOT EXISTS等價(jià)改寫為NOT IN的時(shí)候,要注意NULL。一般情況下,如果反連接采用NOT IN寫法,需要在where條件中剔除NULL。
SELECT * FROM SCOTT.DEPT WHERE DEPTNO NOT IN (SELECT DEPTNO FROM SCOTT.EMP WHERE DEPTNO IS NOT NULL)
NOT IN 和 NOT EXISTS除了可以相互等價(jià)改寫以外,還可以等價(jià)改寫為外連接+子表連接條件IS NULL。
SELECT S.* FROM SCOTT.DEPT S LEFT JOIN SCOTT.EMP E ON S.DEPTNO = E.DEPTNO WHERE E.DEPTNO IS NULL
1、為什么反連接可以改寫為“外連接+子表連接條件IS NULL”?
反半連接算法:兩表關(guān)聯(lián)只返回主表的數(shù)據(jù),而且只返回主表與子表沒(méi)有關(guān)聯(lián)上的數(shù)據(jù)。半連接改寫為內(nèi)連接不同的是,反連接改寫為外連接不需要考慮兩表之間的關(guān)系。
八、FILTER
FILTER算法:如果子查詢(in/exists/not in/not exists)沒(méi)能展開(kāi)(unnest),在執(zhí)行計(jì)劃中就會(huì)產(chǎn)生FILTER,F(xiàn)ILTER類似嵌套循環(huán),F(xiàn)ILTER算法與標(biāo)量子查詢一模一樣。假如主表返回大量數(shù)據(jù),主表的連接列基數(shù)很高,那么子查詢中的表會(huì)被多次掃描。
九、IN與EXISTS誰(shuí)快誰(shuí)慢
很多人都受過(guò)in與exists誰(shuí)快誰(shuí)慢的問(wèn)題的困擾。如果執(zhí)行計(jì)劃中沒(méi)有產(chǎn)生FILTER,那么可以參考以下思路:in與exists是半連接,半連接也是屬于表連接,那么既然是表連接,需要關(guān)心的是兩表的大小以及兩表之間究竟走什么連接方式,還要控制兩表的連接方式,才能隨心所欲優(yōu)化SQL。
原文鏈接:https://blog.csdn.net/xiaobinhxb/article/details/126317295
