




提到PG的repmgr,大家可能并不陌生,他是現(xiàn)在PG比較流行的一套開源工具,用于管理PostgreSQL服務(wù)器集群中的復(fù)制管理和故障轉(zhuǎn)移,也就是相當于一個集群管理+HA工具。當前PG的高可用方案,大致有keepalived、pgpool、repmgr、pacemaker+corosync、etcd+patroni等等。其中etcd+patroni和repmgr是目前用的較多的高可用。patroni的話需要至少三個以上且為奇數(shù)的 etcd 節(jié)點,而且大部分參數(shù)都需要通過更改 etcd 中鍵值來修改。而repmgr相對來說配置簡單、添加節(jié)點比較方便。
從openGauss數(shù)據(jù)庫開源以來,也研究MogDB/openGauss一年了,個人感覺MogDB/openGauss加上云和恩墨自主研發(fā)的MogHA高可用工具 和 PG的repmgr高可用方案比較類似。
眾所周知MogDB/openGauss數(shù)據(jù)庫是基于PostgreSQL研發(fā)而出,因此一些功能和工具也比較類似。
工具的話比較常用的gs_basebackup/pg_basebackup,gs_probackup/pg_probackup,pg_resetxlog等等。今天對于工具這邊就不做詳細說明了。如下,是我對MogDB/openGauss集群管理、MogHA高可用軟件以及PG的repmgr相對應(yīng)的功能的一些對比。接觸過MogDB/openGauss或者repmgr單一一種的可以試著了解一下另外一部分的,上手應(yīng)該會比較快。
1.查看集群狀態(tài)
2.MogDB/openGauss全量build & repmgr clone
3.MogDB/openGauss增量build & repmgr node rejoin --force-rewind
4.switchover
5.MogDB/openGauss高可用工具MogHA & repmgr 切換
一、查看集群狀態(tài)
1.MogHA/openGauss:
MogHA/openGauss的數(shù)據(jù)庫可以通過OM工具來查看集群狀態(tài)。
[omm@node1 ~]$ gs_om -t status --detail
[ Cluster State ]
cluster_state : Normal
redistributing : No
current_az : AZ_ALL
[ Datanode State ]
## node node_ip instance state | node node_ip instance state
1 node1 172.20.10.7 6001 /gaussdb/data/dn1 P Primary Normal | 2 node2 172.20.10.8 6002 /gaussdb/data/dn1 S Standby Normal
2.PG repmgr
/home/postgres/repmgr-5.1.0/repmgr -f /home/postgres/repmgr.conf cluster show
DEBUG: connecting to: "user=repmgr connect_timeout=2 dbname=repmgr host=172.20.10.1 port=6000 fallback_application_name=repmgr"
DEBUG: connecting to: "user=repmgr connect_timeout=2 dbname=repmgr host=172.20.10.1 port=6000 fallback_application_name=repmgr"
DEBUG: connecting to: "user=repmgr connect_timeout=2 dbname=repmgr host=172.20.10.2 port=6000 fallback_application_name=repmgr"
DEBUG: connecting to: "user=repmgr connect_timeout=2 dbname=repmgr host=172.20.10.1 port=6000 fallback_application_name=repmgr"
DEBUG: connecting to: "user=repmgr connect_timeout=2 dbname=repmgr host=172.20.10.3 port=6000 fallback_application_name=repmgr"
DEBUG: connecting to: "user=repmgr connect_timeout=2 dbname=repmgr host=172.20.10.1 port=6000 fallback_application_name=repmgr"
ID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string
----+-------------+---------+-----------+-------------+----------+----------+----------+------------------------------------------------------------------------
1 | enmo_6001 | primary | * running | | default | 100 | 1 | host=172.20.10.1 port=6000 user=repmgr dbname=repmgr connect_timeout=2
2 | enmo_6002 | standby | running | enmo_6001 | default | 100 | 1 | host=172.20.10.2 port=6000 user=repmgr dbname=repmgr connect_timeout=2
3 | enmo_6003 | standby | running | enmo_6001 | default | 100 | 1 | host=172.20.10.3 port=6000 user=repmgr dbname=repmgr connect_timeout=2
二、MogDB/openGauss全量build & repmgr clone
這兩種方法,MogDB/openGauss的build一般用在主備的數(shù)據(jù)不一致,且日志追不上的情況,備庫從主庫重新拉取一份數(shù)據(jù)目錄數(shù)據(jù),且在拉取之前會清空數(shù)據(jù)目錄,repmgr一般用在重新搭建主從,或者主備的數(shù)據(jù)不一致,且日志追不上的情況,或者timeline存在問題的時候。clone要在備機register之前做。
1.MogDB/openGauss
gs\_ctl build -D /gaussdb/data/dn1/ -b full
MogDB/openGauss的全量build是通過全量鏡像的方式重新同步主機的數(shù)據(jù)目錄 。
[omm@node2 ~]$ gs_ctl build -D /gaussdb/data/dn1/ -b full
[2021-09-30 07:27:48.355][18280][][gs_ctl]: gs_ctl full build ,datadir is /gaussdb/data/dn1
waiting for server to shut down.... done
server stopped
[2021-09-30 07:27:49.375][18280][][gs_ctl]: current workdir is (/home/omm).
[2021-09-30 07:27:49.375][18280][][gs_ctl]: fopen build pid file "/gaussdb/data/dn1/gs_build.pid" success
[2021-09-30 07:27:49.375][18280][][gs_ctl]: fprintf build pid file "/gaussdb/data/dn1/gs_build.pid" success
[2021-09-30 07:27:49.376][18280][][gs_ctl]: fsync build pid file "/gaussdb/data/dn1/gs_build.pid" success
[2021-09-30 07:27:49.376][18280][][gs_ctl]: set gaussdb state file when full build:db state(BUILDING_STATE), server mode(STANDBY_MODE), build mode(FULL_BUILD).
[2021-09-30 07:27:49.381][18280][dn_6001_6002][gs_ctl]: connect to server success, build started.
[2021-09-30 07:27:49.381][18280][dn_6001_6002][gs_ctl]: create build tag file success
[2021-09-30 07:27:49.806][18280][dn_6001_6002][gs_ctl]: clear old target dir success
[2021-09-30 07:27:49.806][18280][dn_6001_6002][gs_ctl]: create build tag file again success
[2021-09-30 07:27:49.806][18280][dn_6001_6002][gs_ctl]: get system identifier success
[2021-09-30 07:27:49.806][18280][dn_6001_6002][gs_ctl]: receiving and unpacking files...
[2021-09-30 07:27:49.806][18280][dn_6001_6002][gs_ctl]: create backup label success
[2021-09-30 07:27:50.634][18280][dn_6001_6002][gs_ctl]: xlog start point: 0/3A000028
[2021-09-30 07:27:50.634][18280][dn_6001_6002][gs_ctl]: begin build tablespace list
[2021-09-30 07:27:50.635][18280][dn_6001_6002][gs_ctl]: finish build tablespace list
[2021-09-30 07:27:50.635][18280][dn_6001_6002][gs_ctl]: begin get xlog by xlogstream
[2021-09-30 07:27:50.635][18280][dn_6001_6002][gs_ctl]: starting background WAL receiver
[2021-09-30 07:27:50.635][18280][dn_6001_6002][gs_ctl]: starting walreceiver
[2021-09-30 07:27:50.635][18280][dn_6001_6002][gs_ctl]: begin receive tar files
[2021-09-30 07:27:50.636][18280][dn_6001_6002][gs_ctl]: receiving and unpacking files...
[2021-09-30 07:27:50.656][18280][dn_6001_6002][gs_ctl]: check identify system success
[2021-09-30 07:27:50.657][18280][dn_6001_6002][gs_ctl]: send START_REPLICATION 0/3A000000 success
[2021-09-30 07:28:01.151][18280][dn_6001_6002][gs_ctl]: finish receive tar files
[2021-09-30 07:28:01.151][18280][dn_6001_6002][gs_ctl]: xlog end point: 0/3A000170
[2021-09-30 07:28:01.151][18280][dn_6001_6002][gs_ctl]: fetching MOT checkpoint
[2021-09-30 07:28:01.152][18280][dn_6001_6002][gs_ctl]: waiting for background process to finish streaming...
[2021-09-30 07:28:05.805][18280][dn_6001_6002][gs_ctl]: build dummy dw file success
[2021-09-30 07:28:05.805][18280][dn_6001_6002][gs_ctl]: rename build status file success
[2021-09-30 07:28:05.805][18280][dn_6001_6002][gs_ctl]: build completed(/gaussdb/data/dn1).
[2021-09-30 07:28:06.157][18280][dn_6001_6002][gs_ctl]: waiting for server to start...
2.PG repmgr
repmgr -h 172.20.10.7 -p6000 -U repmgr -d repmgr -f
而repmgr默認是通過pg_basebackup的方式,在日志里會打印出來,且查看源碼發(fā)現(xiàn)還支持barman的方式,openGauss的全量build在源碼里暫未找到調(diào)用gs_basebackup的相關(guān)代碼(可能我沒找到,歡迎幫我指正交流)
[postgres@enmo-02 ~]$repmgr -h 172.20.10.1 -p6000 -U repmgr -d repmgr -f /home/postgres/repmgr.conf standby clone
NOTICE: destination directory "/home/postgres/data" provided
INFO: connecting to source node
DETAIL: connection string is: host=172.20.10.1 port=6000 user=repmgr
dbname=repmgr
DETAIL: current installation size is 42 MB
DEBUG: 1 node records returned by source node
DEBUG: connecting to: "user=repmgr connect_timeout=2 dbname=repmgr
host=172.20.10.1 port=6000 fallback_application_name=repmgr"
DEBUG: upstream_node_id determined as 11
NOTICE: checking for available walsenders on the source node (2
required)
NOTICE: checking replication connections can be made to the source
server (2 required)
INFO: checking and correcting permissions on existing directory
"/home/postgres/data"
NOTICE: starting backup (using pg_basebackup)...
HINT: this may take some time; consider using the -c/--fastcheckpoint option
INFO: executing:
/usr/pgsql-11/bin/pg_basebackup -l "repmgr base backup" -D
/home/postgres/data -h 172.20.10.7 -p 6000 -U repmgr -X stream
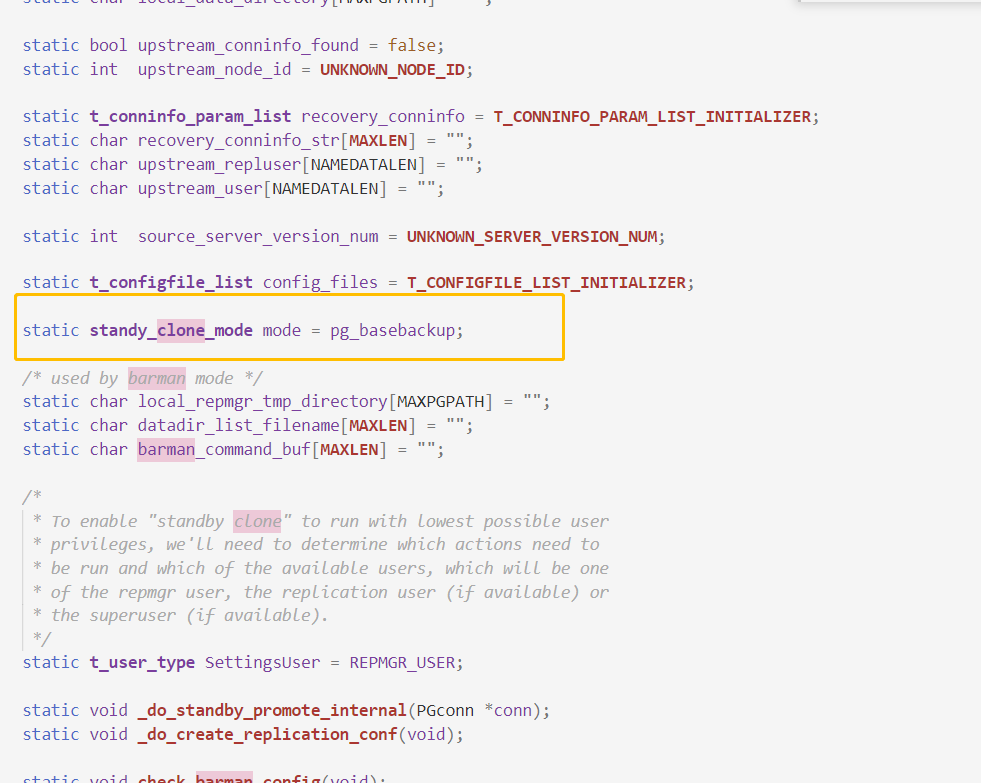
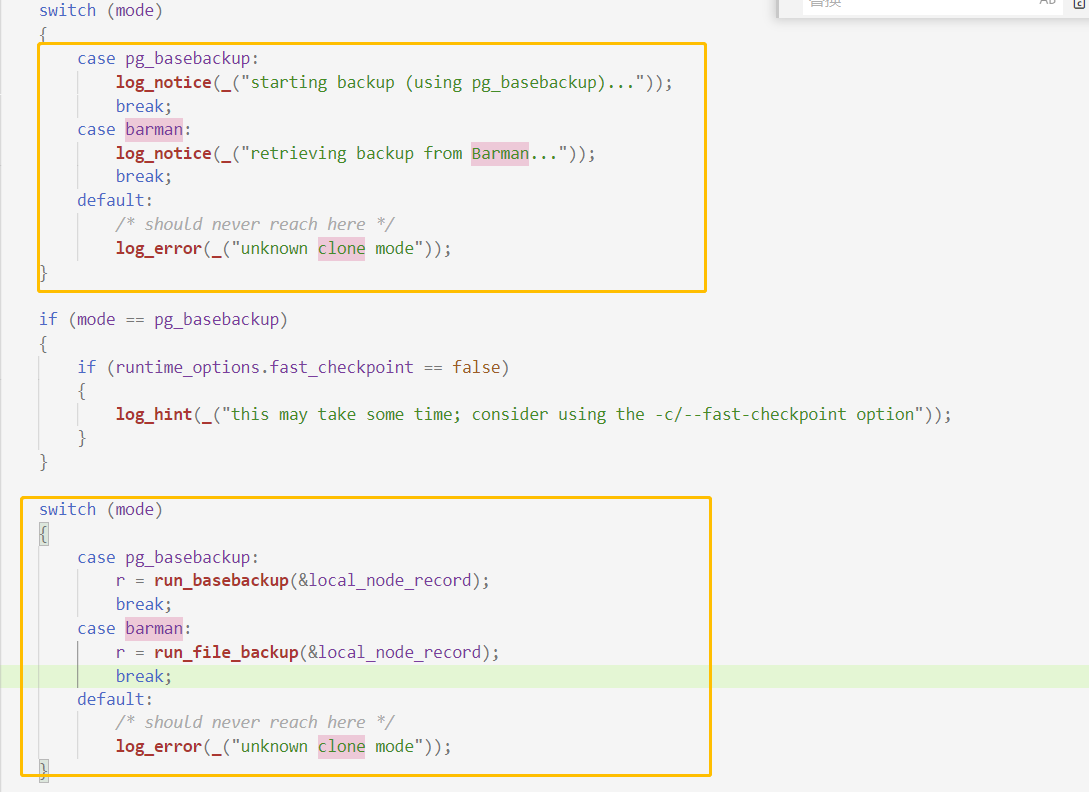
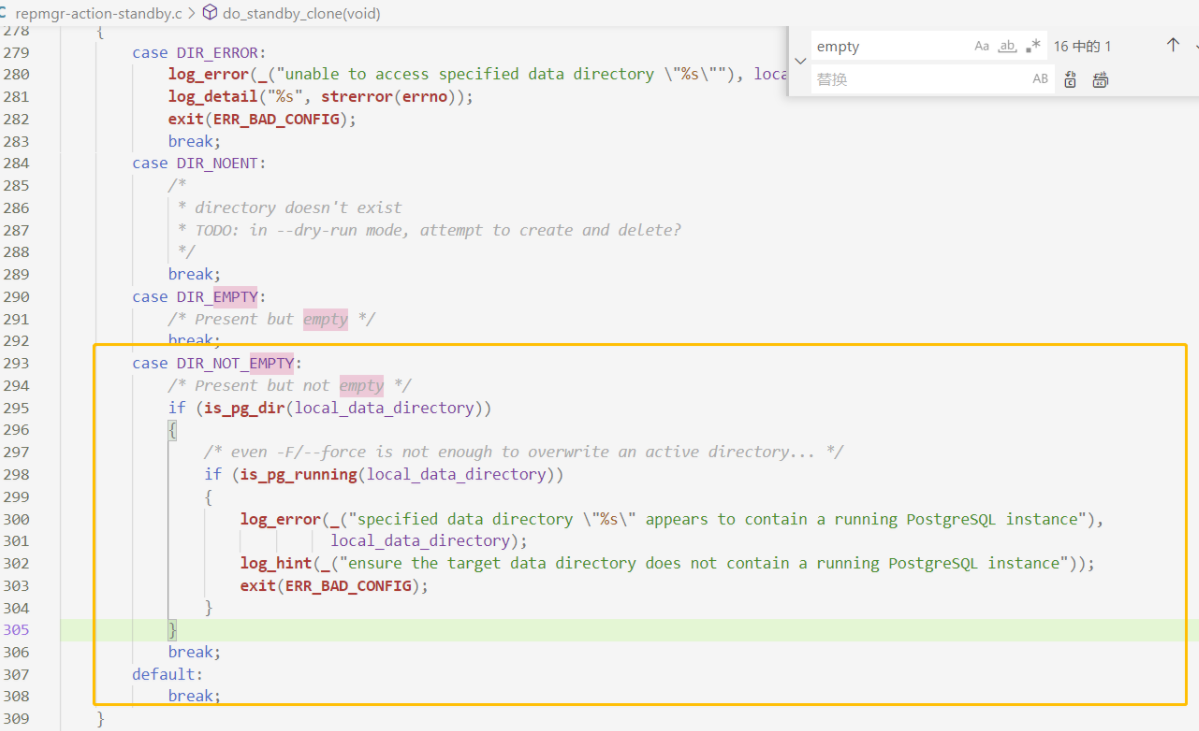
除此之外,發(fā)現(xiàn)MogDB/openGauss和repmgr在做全量build或者clone的時候,MogDB/openGauss會把數(shù)據(jù)目錄清空,而repmgr的clone則是覆蓋。
MogHA/openGauss:
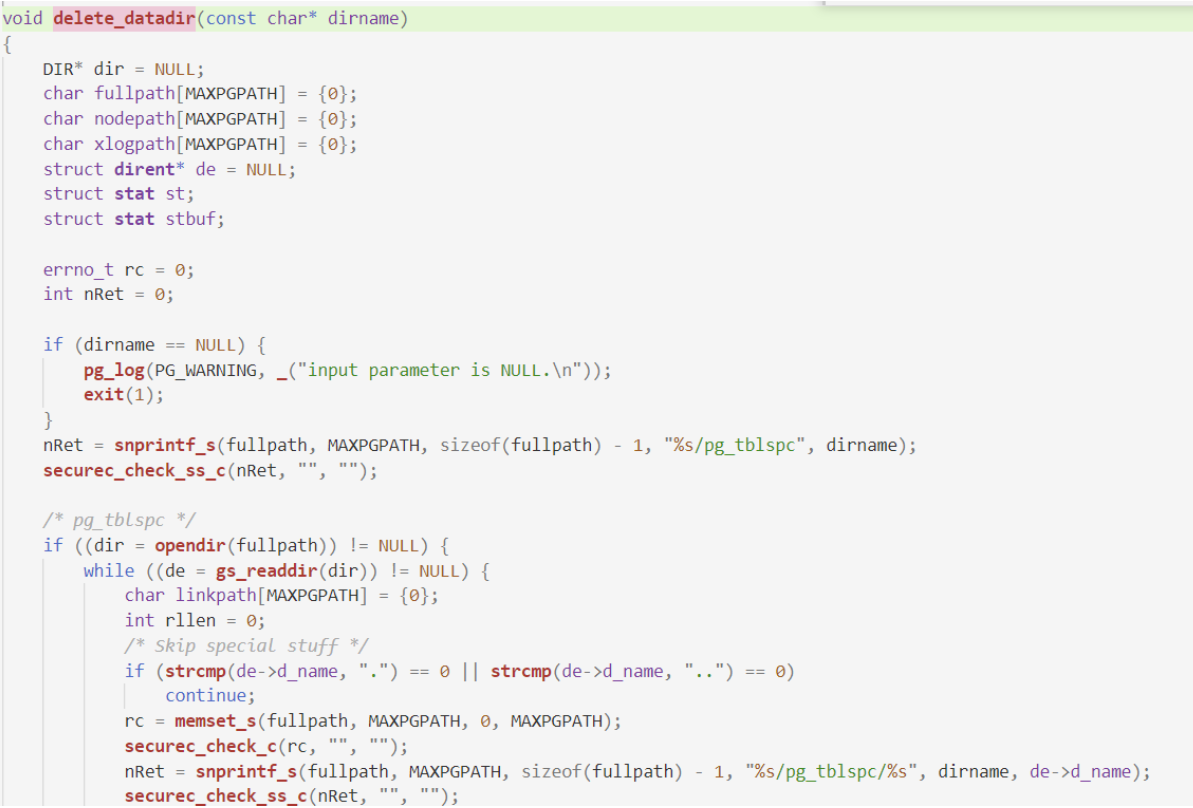
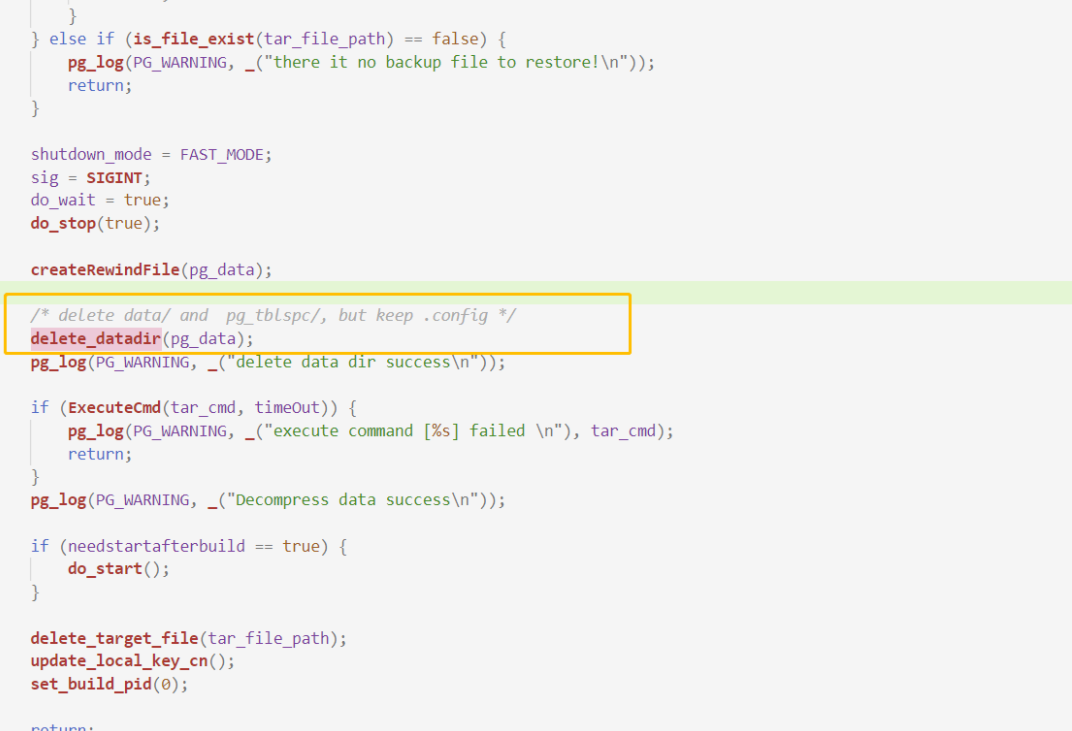
repmgr:
當然,repmgr加上 -F/–force也不能覆蓋一個活躍的目錄。
三.MogDB/openGauss增量build & repmgr node rejoin --force-rewind
MogHA/openGauss:
可以看到,MogHA/openGauss:在通過-b increment做增量build的時候,用到了gs_rewind,與其類似的repmgr也可以通過 repmgr node rejoin --force-rewind,實現(xiàn)類似的功能。
[omm@node2 ~]$ gs_ctl build -D /gaussdb/data/dn1/ -b increment
[2021-09-30 07:54:12.879][27818][][gs_ctl]: gs_ctl incremental build ,datadir is /gaussdb/data/dn1
waiting for server to shut down.... done
server stopped
[2021-09-30 07:54:13.897][27818][][gs_ctl]: fopen build pid file "/gaussdb/data/dn1/gs_build.pid" success
[2021-09-30 07:54:13.897][27818][][gs_ctl]: fprintf build pid file "/gaussdb/data/dn1/gs_build.pid" success
[2021-09-30 07:54:13.897][27818][][gs_ctl]: fsync build pid file "/gaussdb/data/dn1/gs_build.pid" success
[2021-09-30 07:54:13.902][27818][dn_6001_6002][gs_rewind]: set gaussdb state file when rewind:db state(BUILDING_STATE), server mode(STANDBY_MODE), build mode(INC_BUILD).
[2021-09-30 07:54:13.965][27818][dn_6001_6002][gs_rewind]: connected to server: host=172.20.10.7 port=26001 dbname=postgres application_name=gs_rewind connect_timeout=5
[2021-09-30 07:54:13.970][27818][dn_6001_6002][gs_rewind]: connect to primary success
[2021-09-30 07:54:13.971][27818][dn_6001_6002][gs_rewind]: get pg_control success
[2021-09-30 07:54:13.972][27818][dn_6001_6002][gs_rewind]: target server was interrupted in mode 2.
[2021-09-30 07:54:13.972][27818][dn_6001_6002][gs_rewind]: sanityChecks success
[2021-09-30 07:54:13.972][27818][dn_6001_6002][gs_rewind]: find last checkpoint at 0/3B3CE868 and checkpoint redo at 0/3B3CE7E8 from source control file
[2021-09-30 07:54:13.972][27818][dn_6001_6002][gs_rewind]: find last checkpoint at 0/3B3CE868 and checkpoint redo at 0/3B3CE7E8 from target control file
[2021-09-30 07:54:13.974][27818][dn_6001_6002][gs_rewind]: find max lsn success, find max lsn rec (0/3B3CE868) success.
[2021-09-30 07:54:13.979][27818][dn_6001_6002][gs_rewind]: request lsn is 0/3B3CE868 and its crc(source, target):[3849081485, 3849081485]
[2021-09-30 07:54:13.979][27818][dn_6001_6002][gs_rewind]: find common checkpoint 0/3B3CE868
[2021-09-30 07:54:13.979][27818][dn_6001_6002][gs_rewind]: find diverge point success
[2021-09-30 07:54:13.979][27818][dn_6001_6002][gs_rewind]: read checkpoint redo (0/3B3CE7E8) success before rewinding.
[2021-09-30 07:54:13.979][27818][dn_6001_6002][gs_rewind]: rewinding from checkpoint redo point at 0/3B3CE7E8 on timeline 1
[2021-09-30 07:54:13.979][27818][dn_6001_6002][gs_rewind]: diverge xlogfile is 00000001000000000000003B, older ones will not be copied or removed.
[2021-09-30 07:54:13.980][27818][dn_6001_6002][gs_rewind]: targetFileStatThread success pid 139740617094912.
[2021-09-30 07:54:13.980][27818][dn_6001_6002][gs_rewind]: reading source file list
[2021-09-30 07:54:13.980][27818][dn_6001_6002][gs_rewind]: traverse_datadir start.
[2021-09-30 07:54:13.983][27818][dn_6001_6002][gs_rewind]: filemap_list_to_array start.
[2021-09-30 07:54:13.983][27818][dn_6001_6002][gs_rewind]: filemap_list_to_array end sort start. length is 2704
[2021-09-30 07:54:13.983][27818][dn_6001_6002][gs_rewind]: sort end.
[2021-09-30 07:54:13.990][27818][dn_6001_6002][gs_rewind]: targetFileStatThread return success.
[2021-09-30 07:54:14.001][27818][dn_6001_6002][gs_rewind]: reading target file list
[2021-09-30 07:54:14.005][27818][dn_6001_6002][gs_rewind]: traverse target datadir success
[2021-09-30 07:54:14.005][27818][dn_6001_6002][gs_rewind]: reading WAL in target
[2021-09-30 07:54:14.005][27818][dn_6001_6002][gs_rewind]: could not read WAL record at 0/3B3CE900: invalid record length at 0/3B3CE900: wanted 32, got 0
[2021-09-30 07:54:14.006][27818][dn_6001_6002][gs_rewind]: calculate totals rewind success
[2021-09-30 07:54:14.006][27818][dn_6001_6002][gs_rewind]: need to copy 17MB (total source directory size is 540MB)
[2021-09-30 07:54:14.006][27818][dn_6001_6002][gs_rewind]: starting background WAL receiver
[2021-09-30 07:54:14.006][27818][dn_6001_6002][gs_rewind]: Starting copy xlog, start point: 0/3B3CE7E8
[2021-09-30 07:54:14.006][27818][dn_6001_6002][gs_rewind]: in gs_rewind proecess,so no need remove.
[2021-09-30 07:54:14.012][27818][dn_6001_6002][gs_rewind]: check identify system success
[2021-09-30 07:54:14.012][27818][dn_6001_6002][gs_rewind]: send START_REPLICATION 0/3B000000 success
[2021-09-30 07:54:14.047][27818][dn_6001_6002][gs_rewind]: receiving and unpacking files...
[2021-09-30 07:54:14.173][27818][dn_6001_6002][gs_rewind]: execute file map success
[2021-09-30 07:54:14.174][27818][dn_6001_6002][gs_rewind]: find minRecoveryPoint success from xlog insert location 0/3B3D2D80
[2021-09-30 07:54:14.174][27818][dn_6001_6002][gs_rewind]: update pg_control file success, minRecoveryPoint: 0/3B3D2D80, ckpLoc:0/3B3CE868, ckpRedo:0/3B3CE7E8, preCkp:0/3B3CE750
[2021-09-30 07:54:14.176][27818][dn_6001_6002][gs_rewind]: update pg_dw file success
[2021-09-30 07:54:14.177][27818][dn_6001_6002][gs_rewind]: xlog end point: 0/3B3D2D80
[2021-09-30 07:54:14.177][27818][dn_6001_6002][gs_rewind]: waiting for background process to finish streaming...
[2021-09-30 07:54:19.086][27818][dn_6001_6002][gs_rewind]: creating backup label and updating control file
[2021-09-30 07:54:19.086][27818][dn_6001_6002][gs_rewind]: create backup label success
[2021-09-30 07:54:19.086][27818][dn_6001_6002][gs_rewind]: read checkpoint redo (0/3B3CE7E8) success.
[2021-09-30 07:54:19.086][27818][dn_6001_6002][gs_rewind]: read checkpoint rec (0/3B3CE868) success.
[2021-09-30 07:54:19.086][27818][dn_6001_6002][gs_rewind]: dn incremental build completed.
[2021-09-30 07:54:19.090][27818][dn_6001_6002][gs_rewind]: fetching MOT checkpoint
[2021-09-30 07:54:19.201][27818][dn_6001_6002][gs_ctl]: waiting for server to start...
repmgr:
命令為:
repmgr node rejoin -d ‘host=172.20.10.1 user=repmgr dbname=repmgr connect\_timeout=2’ --force-rewind --verbose
四.switchover
都是在備機執(zhí)行,將本節(jié)點提升為主庫,同時主節(jié)點降級為該新主的備機。
MogHA/openGauss:
gs_ctl switchover -D /gaussdb/data/dn1
[omm@node2 ~]$ gs_ctl switchover -D /gaussdb/data/dn1
[2021-09-30 08:02:09.192][30742][][gs_ctl]: gs_ctl switchover ,datadir is /gaussdb/data/dn1
[2021-09-30 08:02:09.192][30742][][gs_ctl]: switchover term (1)
[2021-09-30 08:02:09.196][30742][][gs_ctl]: waiting for server to switchover..........
[2021-09-30 08:02:16.327][30742][][gs_ctl]: done
[2021-09-30 08:02:16.327][30742][][gs_ctl]: switchover completed (/gaussdb/data/dn1)
repmgr:
repmgr -f /home/postgres/repmgr.conf standby switchover -U repmgr --verbose
[postgres@enmo-02 ~]$ repmgr -f /home/postgres/repmgr.conf standby switchover -U repmgr --verbose
NOTICE: using provided configuration file "/home/postgres/repmgr.conf"
WARNING: following problems with command line parameters detected:
database connection parameters not required when executing STANDBY SWITCHOVER
DEBUG: connecting to: "user=repmgr connect_timeout=2 dbname=repmgr host=10.28.3.134 port=6000 fallback_application_name=repmgr"
DEBUG: set_config():
SET synchronous_commit TO 'local'
DEBUG: get_node_record():
SELECT n.node_id, n.type, n.upstream_node_id, n.node_name, n.conninfo, n.repluser, n.slot_name, n.location, n.priority, n.active, n.config_file, '' AS upstream_node_name, NULL AS attached FROM repmgr.nodes n WHERE n.node_id = 2
NOTICE: executing switchover on node "falcon_6002" (ID: 2)
DEBUG: get_recovery_type(): SELECT pg_catalog.pg_is_in_recovery()
INFO: searching for primary node
DEBUG: get_primary_connection():
五.MogDB/openGauss高可用工具MogHA & repmgr 切換
在這一方面MogHA/openGauss的集群管理工具是gs_om,通過gs_om -t status --detail或者gs_om -t query 查看集群的相關(guān)狀態(tài),但是OM工具本身是不支持高可用的自動切換的,因此,針對這個問題,云和恩墨自主研發(fā)了MogHA高可用工具,它可以通過網(wǎng)絡(luò),主備角色狀態(tài),孤單檢查,心跳檢查等多個維度對數(shù)據(jù)庫和主備節(jié)點進行檢查,確保MogHA/openGauss數(shù)據(jù)庫集群能提供長穩(wěn)運行,且最大程度降低故障切換對業(yè)務(wù)的影響。支持腦裂檢查以及假主處理,vip自動漂移到新主節(jié)點的功能,是一款比較方便且可信的高可用工具。
而repmgr在這邊可以通過編寫repmgr_promote.sh和repmgr_follow.shd腳本的方式,實現(xiàn)數(shù)據(jù)庫的高可用自動切換。和MogDB/openGauss+MogHA+OM的一套體系相比,缺少了MogHA在switchover之后對數(shù)據(jù)庫節(jié)點角色檢查并vip飄移到新主的功能,可能是美中不足。
