




Part1問題環(huán)境
Oracle 11GR2 Rac
Linux服務(wù)器
Part2問題定位
群友發(fā)了一個(gè)AWR報(bào)告,說是數(shù)據(jù)庫負(fù)載特比高,需要幫忙看看什么情況
2.1、查看數(shù)據(jù)庫負(fù)載
DB Time / Elapsed = 207.26 倍
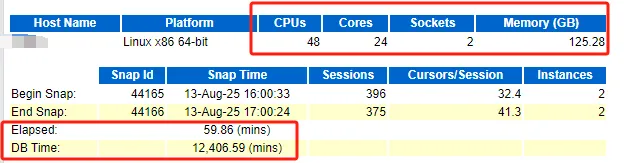 負(fù)載很大
負(fù)載很大
2.2、判斷數(shù)據(jù)庫使用類型
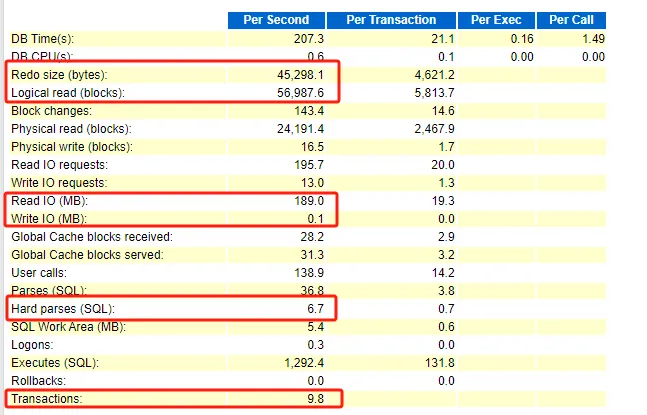 要初步判斷數(shù)據(jù)庫的適用類型,究竟是邏輯型數(shù)據(jù)庫還是IO型數(shù)據(jù)庫,這個(gè)有助于接下來的分析思路
要初步判斷數(shù)據(jù)庫的適用類型,究竟是邏輯型數(shù)據(jù)庫還是IO型數(shù)據(jù)庫,這個(gè)有助于接下來的分析思路
每秒 Redo的產(chǎn)生量是 45kb/s,低的嚇人
每秒邏輯讀的產(chǎn)生量是 445MB/s
每秒物理讀的產(chǎn)生量是 189M/s
每秒物理寫的產(chǎn)生量是 0.1M/s
每秒硬解析的產(chǎn)生量是 6.7個(gè)/s
每秒事務(wù)的產(chǎn)生量是 9.8個(gè)/s
基本判斷數(shù)據(jù)庫屬于邏輯型數(shù)據(jù)庫,數(shù)據(jù)量產(chǎn)生的很小,物理讀的也不小,但是在這里我基本判斷還是一個(gè)由于查詢事務(wù)導(dǎo)致的數(shù)據(jù)庫高負(fù)載,只不過邏輯查詢更嚴(yán)重一些。
2.3、數(shù)據(jù)庫命中率判斷
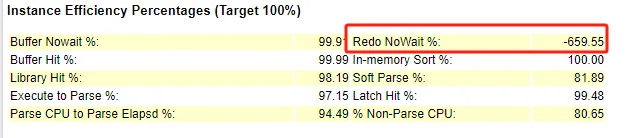 Redo NoWait %這個(gè)數(shù)值低于95%就需要嚴(yán)重關(guān)注,它的含義是redo提交不需要等待的百分比,這個(gè)已經(jīng)到了負(fù)值,說明數(shù)據(jù)庫提交方面遇到了很嚴(yán)重的問題。
Redo NoWait %這個(gè)數(shù)值低于95%就需要嚴(yán)重關(guān)注,它的含義是redo提交不需要等待的百分比,這個(gè)已經(jīng)到了負(fù)值,說明數(shù)據(jù)庫提交方面遇到了很嚴(yán)重的問題。
2.4、等待時(shí)間排序的等待事件
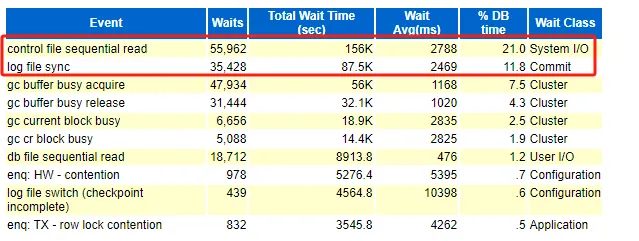 問題太多,一下子不知道該看哪個(gè)了,
問題太多,一下子不知道該看哪個(gè)了,
總的來說由commit和system I/O更顯眼一點(diǎn),這里注意到的是控制文件讀和log file sync排第一和第二,這個(gè)情況在DBA攻堅(jiān)指南看到過。屬于是引起log file sync的種類之一,因?yàn)榭刂莆募蠡蛘邭w檔操作太過頻繁引起的。
cluster等待事件的熱點(diǎn)塊也許是原因也許是結(jié)果,需要第二層關(guān)注
2.5、判斷等待類型的時(shí)間排序
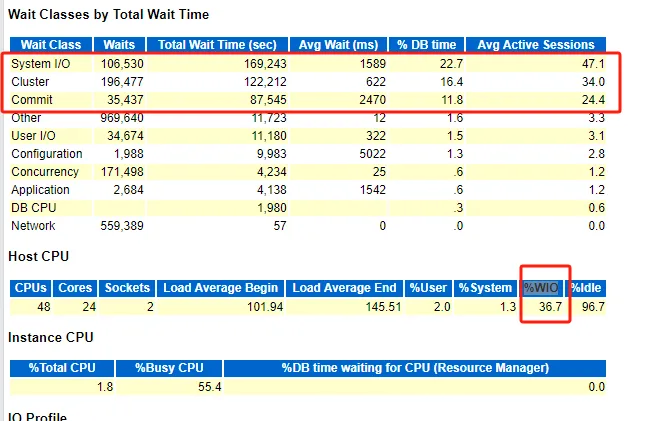 %DBTIME加起來沒到100%,大約只有50%,說明這臺(tái)服務(wù)器要么是CPU太老舊,要么是這臺(tái)服務(wù)器有其他的服務(wù)在使用,劃分走了機(jī)器的CPU
%DBTIME加起來沒到100%,大約只有50%,說明這臺(tái)服務(wù)器要么是CPU太老舊,要么是這臺(tái)服務(wù)器有其他的服務(wù)在使用,劃分走了機(jī)器的CPU
%WIO說是CPU因?yàn)榈却齀O計(jì)算的百分比,在CPU拉跨的情況下,IO等待百分比還是這么高,實(shí)在是太夸張了
尤其是log file sync等待事件的情況下,應(yīng)該現(xiàn)在優(yōu)先判斷一下磁盤的情況
看看io
of=/soft/testdisk/io_test.bin
指的是redo日志磁盤路徑生成的壓測(cè)文件
dd if=/dev/zero of=/soft/testdisk/io_test.bin bs=8192 count=1000 oflag=direct
注意:嚴(yán)重危險(xiǎn),不熟悉的情況下,建議云平臺(tái)或者存儲(chǔ)人員操作
2.6、零零碎碎的驗(yàn)證
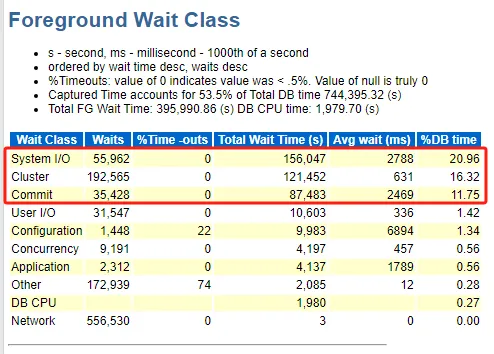
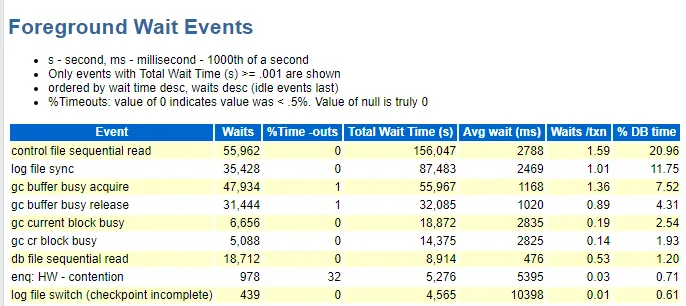
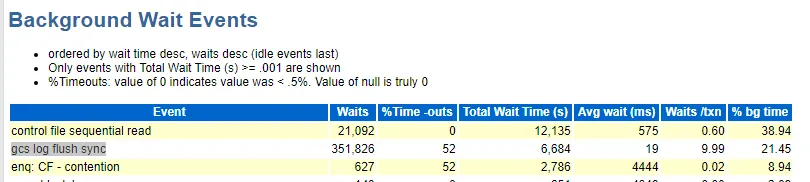
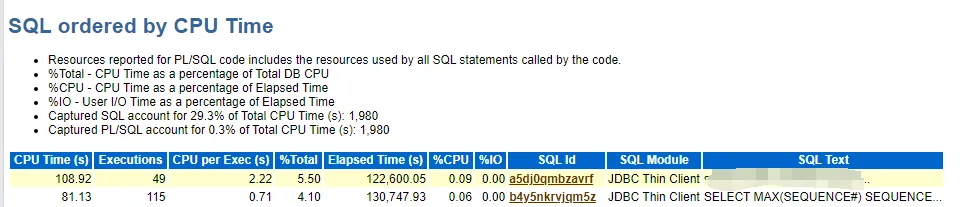
SELECT MAX(SEQUENCE#) SEQUENCE, THREAD# THREAD FROM GV$ARCHIVED_LOG WHERE RESETLOGS_CHANGE# = (SELECT RESETLOGS_CHANGE# FROM V$DATABASE) AND STATUS='A' AND STANDBY_DEST='NO' GROUP BY THREAD#
按理來說,查詢歸檔的sql成本不會(huì)這么大
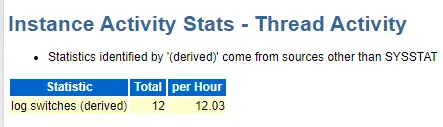 日志切換頻率,驗(yàn)證了和數(shù)據(jù)量沒有什么關(guān)系
日志切換頻率,驗(yàn)證了和數(shù)據(jù)量沒有什么關(guān)系
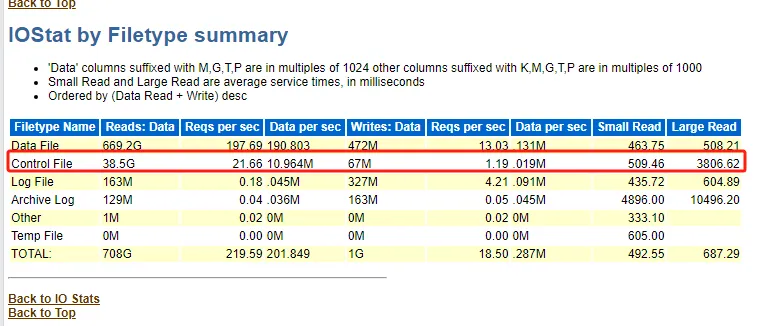 控制文件這么大的邏輯讀是不正常的。
控制文件這么大的邏輯讀是不正常的。
Part3問題解決
3.1、磁盤IO驗(yàn)證
看看io
of=/soft/testdisk/io_test.bin
指的是redo日志磁盤路徑生成的壓測(cè)文件
dd if=/dev/zero of=/soft/testdisk/io_test.bin bs=8192 count=1000 oflag=direct
3.2、控制文件定位
判斷步驟是
1、查詢控制文件大小
2、查詢歸檔大小和歸檔數(shù)量
3、查看這個(gè)時(shí)間段是否有歸檔的操作(尤其是刪除)
解決方案
設(shè)置歸檔保留時(shí)間(不要再業(yè)務(wù)高峰清理)
控制 控制文件大小,看是否能縮一下
監(jiān)控歸檔sql是否需要這么頻繁,設(shè)置執(zhí)行間隔
查看控制文件真實(shí)大小
select v.*,round(BLOCK_SIZE*FILE_SIZE_BLKS/1024/1024,2) from v$controlfile v;
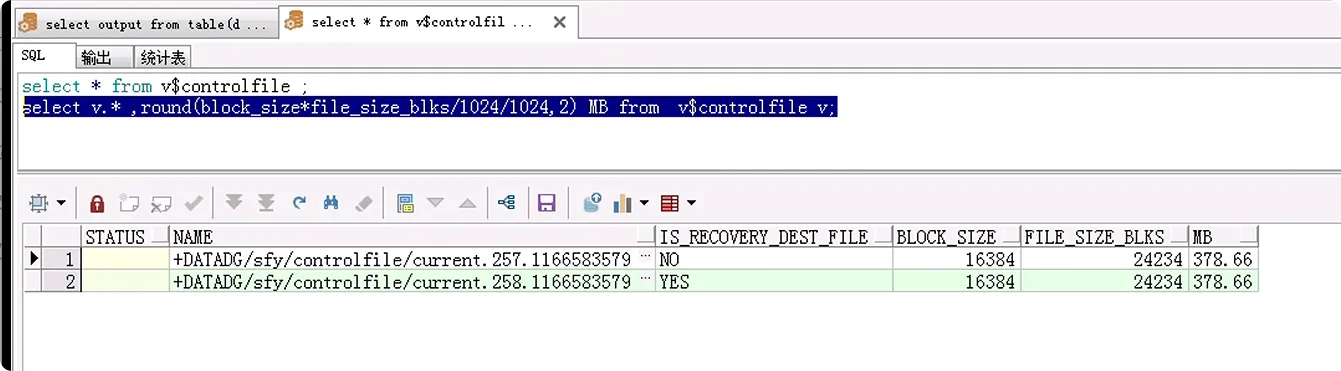
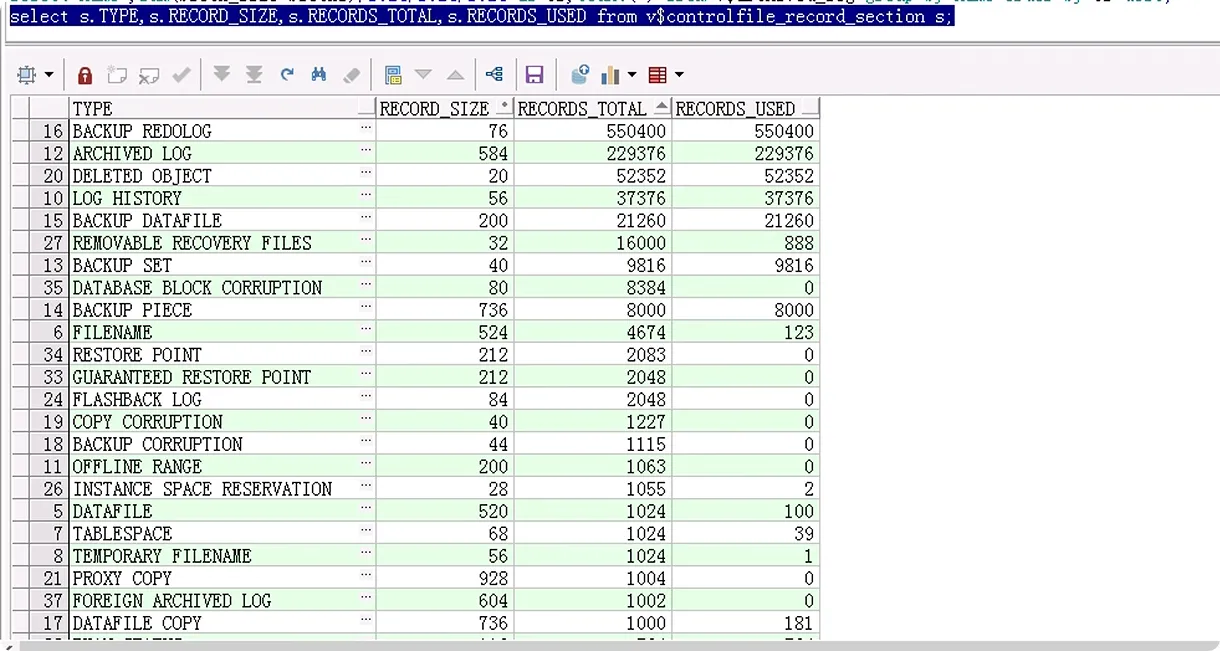
查看控制文件構(gòu)成及其每部分大小
record_size的單位是字節(jié)(bytes),
select type,record_size from v$controlfile_record_section order by record_size desc;
SELECT
type AS "區(qū)域類型",
records_total AS "預(yù)分配記錄數(shù)",
record_size AS "單條記錄大小(字節(jié))",
-- 核心計(jì)算:區(qū)域總大小 = 記錄數(shù) × 每條大小
ROUND((records_total * record_size) / 1024 /1024, 2) AS "總大小(MB)"
FROM v$controlfile_record_section
ORDER BY (records_total * record_size) DESC;
BACKUP_REDOLOG 40M
ARCHIVED_LOG 127.75M
DELETED_OBJECT 1M
LOG_HISTORY 2M
查詢現(xiàn)存的數(shù)據(jù)庫歸檔,deleted表示歸檔是否刪除,name一定要指定對(duì),因?yàn)榭赡軙?huì)有ADG,所以只需要看本地實(shí)際存在的就行。
SELECT
COUNT(1) AS "現(xiàn)存歸檔條數(shù)",
ROUND(SUM(BLOCKS * BLOCK_SIZE) / 1024 / 1024,2) AS "總大小(MB)",
MIN(FIRST_TIME) AS "最早歸檔時(shí)間",
MAX(COMPLETION_TIME) AS "最新歸檔時(shí)間"
FROM v$archived_log
WHERE
name IS NOT NULL -- 確保是有效歸檔
AND deleted = 'NO' -- 未被刪除
AND standby_dest = 'NO' -- 排除備用庫歸檔;
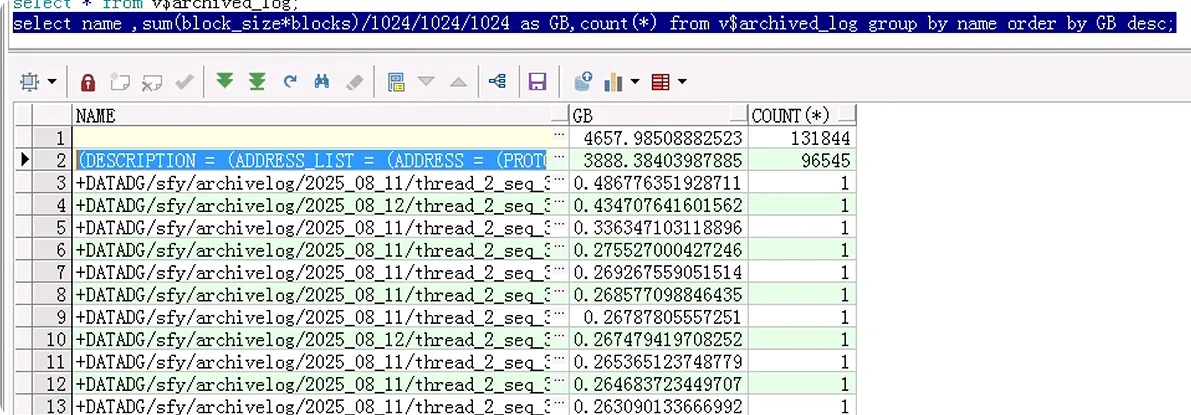
后續(xù)發(fā)個(gè)截圖發(fā)現(xiàn)是備庫歸檔滿了,導(dǎo)致數(shù)據(jù)庫同步失敗。
crosscheck backup;
crosscheck archivelog all;
delete noprompt archivelog all completed before 'sysdate-1';
Part4問題回溯
1、看到log file sync的時(shí)候,又看到控制文件,當(dāng)時(shí)想的就是控制文件出現(xiàn)了問題,攻堅(jiān)指南里但是寫著enq: CF - contention是形影不離的關(guān)系,可是在top 10沒看到,在后續(xù)的后臺(tái)等待日志看到了,可惜是事后梳理發(fā)現(xiàn)的,說明等待事件之間的綁定關(guān)系還是記得不清
2、雖然直覺性直接去判斷控制文件的大小,再去查歸檔的大小,而且在top 10的sql語句里發(fā)現(xiàn)了歸檔的查詢,消耗占比排第二,當(dāng)時(shí)是篤定就是他的問題,但是事后反思還是應(yīng)該看看磁盤的IO,進(jìn)行一下壓測(cè),可以更好地判斷,到底是磁盤性能異常還是控制文件過大引起的。
3、后續(xù)群友更發(fā)了一個(gè)關(guān)于數(shù)據(jù)庫歸檔無法傳輸,導(dǎo)致數(shù)據(jù)庫歸檔積攢的報(bào)錯(cuò),但是當(dāng)時(shí)好多查詢sql寫的并不是那么準(zhǔn)確,也給我的判斷帶來了誤判,比如說現(xiàn)存歸檔的數(shù)量和大小,他給我的是所有的,而不是現(xiàn)存的。
4、最重要的是,還沒進(jìn)行歸檔刪除,數(shù)據(jù)庫負(fù)載自己降下來了,很奇怪,到底做了什么操作也沒說。到底是業(yè)務(wù)下來了(因?yàn)橐呀?jīng)是快下午六點(diǎn)了)還是磁盤異常恢復(fù)還是數(shù)據(jù)庫監(jiān)控歸檔sql停止,都沒說,所以很難判斷真正的原因。
Part5問題原理
控制文件的原理、作用、判斷方式建議看看 《Oracle DBA實(shí)戰(zhàn)攻略:運(yùn)維管理、診斷優(yōu)化、高可用與最佳實(shí)踐》.(周亮)
到時(shí)候跟寫一篇具體的吧
