





vertica 如何group by語句?想要知道數據庫語句的實際執行情況,都是需要先查看執行計劃的,Vertica也不例外。先對語句進行explain 操作查看預執行計劃,其中group by 分為 GROUPBY PIPELINED 和 GROUPBY HASH,通過執行計劃可以清楚的看到vertica到底采用的那種執行方式,優化一般就是吧GROUPBY HASH優化為GROUPBY PIPELINED。
CREATE TABLE sortopt (
a INT NOT NULL,
b INT NOT NULL,
c INT,
d INT
);
CREATE PROJECTION sortopt_p (
a_proj,
b_proj,
c_proj,
d_proj )
AS SELECT * FROM sortopt
ORDER BY a,b,c
UNSEGMENTED ALL NODES;
INSERT INTO sortopt VALUES(5,2,13,84);
INSERT INTO sortopt VALUES(14,22,8,115);
INSERT INTO sortopt VALUES(79,9,401,33);
1. 第一種情況
GROUP BY a GROUP BY a,b GROUP BY b,a GROUP BY a,b,c GROUP BY c,a,b

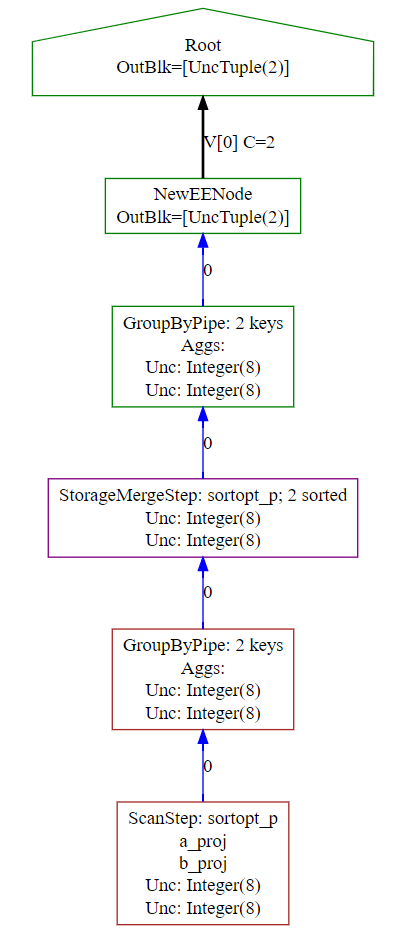
如果是按照上面的這種group by 則使用的是GROUPBY PIPELINED,因為group by 后的字段全部在projection中預排序
GROUP BY a,b,c,d

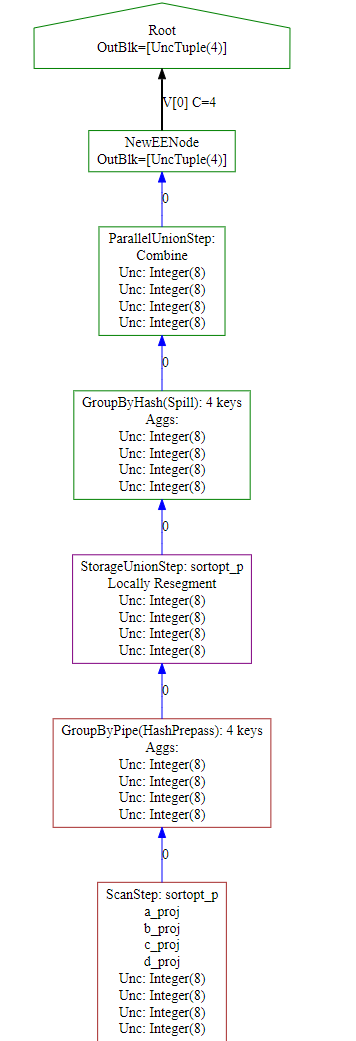
這種情況則是采用的GROUPBY HASH ,不建議!
2.第二種情況
GROUP BY a,c
執行 按照GROUPBY HASH 因為a,c字段沒有相鄰,如果是GROUP BY a,c或者GROUP BY b,c則會按照GROUPBY PIPELINED 執行。
3.第三種情況
group by 之前有 where條件時:
SELECT a FROM tab WHERE a = 10 GROUP BY b 此時按照 GROUPBY PIPELINED;
SELECT a FROM tab WHERE a = 10 GROUP BY c 此時按照 GROUPBY HASH 以為按照c排序的處理的所有的 Projectionn 列的列未出現在 where 子句等值條件中,如果上如改為SELECT a FROM tab WHERE a = 10 and b=10 GROUP BY c 則會按照GROUPBY PIPELINED 執行
通過以上3中情況的介紹,希望大家對vertica的group by有一定的理解,能夠在使用group 中更好的優化查詢性能。
