






一、概述
1.1、什么是Vertica?
Vertica是一款基于列存儲的MPP (massively parallel processing)架構的數據庫。它可以支持存放多至PB(Petabyte)級別的結構化數據。Vertica是由關系數據庫大師Michael Stonebraker(2014 年圖靈獎獲得者)所創建,于2011年被惠普收購并成為其核心大數據平臺軟件。
1.2、功能特點
Vertica有如下特點
-
列式存儲和執行
在分析工作負載方面,列式存儲可顯著提高性能、I/O、存儲空間和效率。使用列式存儲,查詢僅讀取回答查詢所需的列。
-
實時加載和查詢
具有高查詢并發性和將新數據同時加載到系統中并進行查詢的能力。Vertica加載數據的速度比傳統的行存儲數據庫快 10 倍。
-
高級數據庫分析
一組高級數據庫內分析,包括機器學習、地理空間和時間序列分析,讓您可以更接近您的數據進行分析計算。這些內置功能可提供即時結果,而無需求助于其他分析工具。
-
數據庫設計器和管理工具
-
高級壓縮
積極的編碼和壓縮允許Vertica通過在處理時減少 CPU、內存和磁盤 I/O 來顯著提高分析性能。Vertica可以將原始數據大小減少多達 90%,低至其原始大小的 1/10,而不會丟失信息或精度。
-
結構化和半結構化數據
除了傳統的結構化數據庫表,Vertica還提供彈性表,讓您可以加載和分析半結構化數據,例如 JSON 格式的數據。
-
大規模并行處理
強大且可擴展的并行處理解決方案提供主動冗余、自動復制、故障轉移和恢復。
-
隨處部署
在位于您自己(或協同定位)數據中心的物理硬件上運行。或者在您自己的虛擬主機或主要云平臺(AWS、Azure 和 Google Cloud)上的虛擬硬件上運行。
-
數據湖連接
使用內置連接器分析來自 Apache Hadoop 和 Kafka 的數據。對于其他系統,Vertica提供了一套標準客戶端庫,例如 JDBC 和 ODBC。
-
管理和監控
基于瀏覽器的管理控制臺讓您可以通過用戶友好的 GUI 創建、導入和管理您的 Vertica 數據庫。
-
動態擴展集群以滿足工作負載
使用Eon 模式擴展您的數據庫集群以滿足增加的工作負載,或縮小它以節省資金。
1.3、架構基礎
了解Vertica架構核心的幾個關鍵概念
1.3.1、列存儲
Vertica以列格式存儲數據,以便查詢以獲得最佳性能。與基于行的存儲相比,列存儲減少了磁盤 I/O,使其成為讀取密集型工作負載的理想選擇。Vertica僅讀取回答查詢所需的列。例如:
SELECT avg(price) FROM tickstore WHERE symbol = 'AAPL' and date = '5/31/13';
對于此示例查詢,列存儲僅讀取三列,而行存儲讀取所有列:
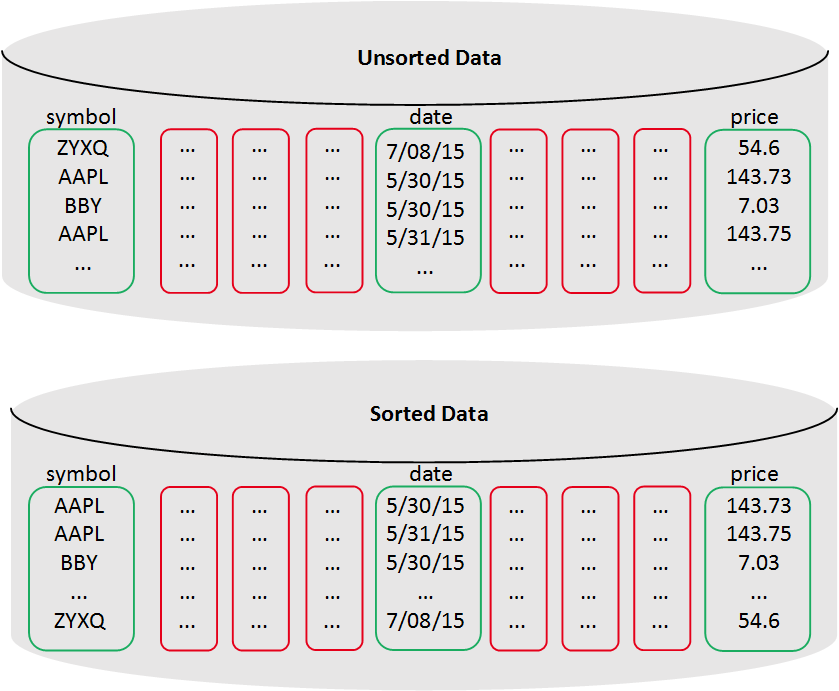
1.3.2、數據編碼和壓縮
Vertica使用編碼和壓縮來優化查詢性能并節省存儲空間。
-
編碼
編碼將數據轉換為標準格式。 Vertica 使用多種不同的編碼策略,具體取決于列數據類型、表基數和排序順序。編碼可提高性能,因為查詢執行期間磁盤 I/O 較少。此外,您可以在更少的空間中存儲更多的數據。
-
壓縮
與其他數據庫相比,Vertica 可以存儲更多數據、提供更多視圖并使用更少的硬件。Vertica使用多種不同的壓縮方法,并自動為被壓縮的數據選擇最好的一種。
壓縮允許列存儲占用比行存儲少得多的存儲空間。在列存儲中,存儲在投影列中的每個值都具有相同的數據類型。這極大地促進了壓縮,尤其是在已排序的列中。在行存儲中,行的每個值可以具有不同的數據類型,從而導致壓縮的使用效率低得多。
下面顯示了使用排序和基數的壓縮:
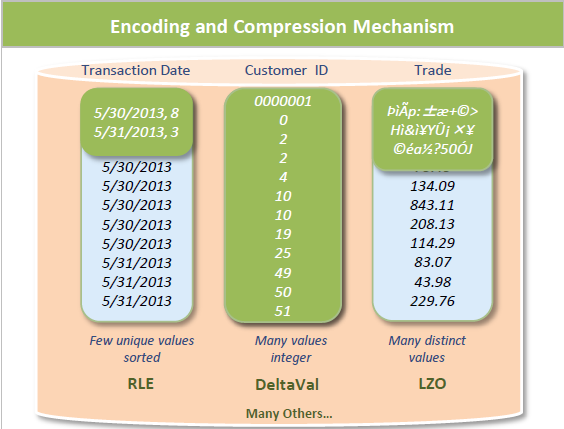
1.3.3、集群
集群支持擴展和冗余。可以通過添加更多節點來擴展數據庫集群,并且可以通過跨集群分發和復制數據來提高可靠性。
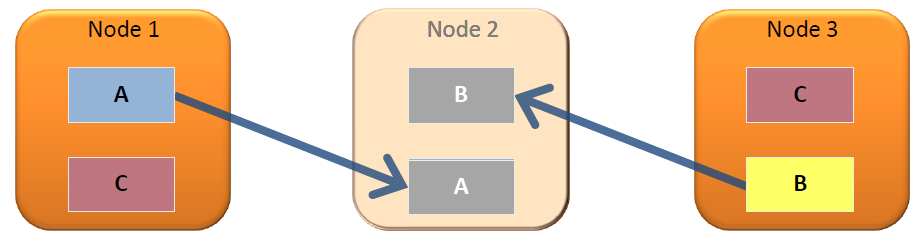
列數據分布在集群中的節點上,因此如果一個節點不可用,數據庫將繼續運行。當一個節點被添加到集群中,或者在不可用后重新上線時,它會自動查詢其他節點以更新其本地數據。
1.3.4、邏輯和物理Schema
Vertica將有關數據庫對象的信息存儲在邏輯架構和物理架構中。兩種架構之間的差異以及它們與數據存儲的關系是Vertica架構的一個重要且獨特的方面。
1.4、關鍵能力
性價比高,支持大規模擴展
HPE Vertica,可部署于廉價的x86服務器/私有云/公有云/Hadoop,軟件License費用可預期,支持大規模節點擴展。
高處理性能
決定一個大數據平臺綜合性能的主要因素包括:硬件處理性能和數據庫軟件性能。其中,磁盤速度從1956年至今僅僅增長了12.5倍,I/O是主要瓶頸。
而HPE Vertica,能夠勝任大規模批量計算、高并發查詢、以及極端復雜的自主分析和查詢。Vertica提高性能的秘訣在于:
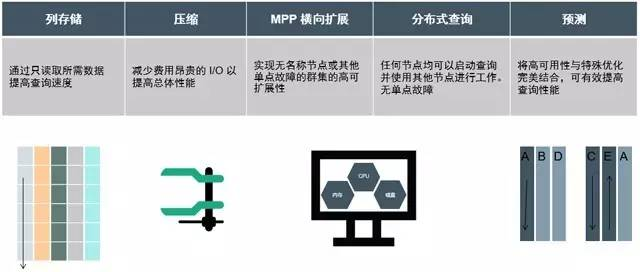
高頻數據加載和實時分析
Vertica調度程序(vertica-kafka-scheduler.jar)負責組織協調從Kafka持續加載數據流資源,Vertica KafkaExport插件負責將SQL查詢結果導出到Kafka等。
最終,HPE Vertica能夠支持秒級數據實時加載和秒級甚至亞秒級的數據查詢響應能力。
開放性和集成能力
Vertica可與Hadoop Hive/HDFS/Spark無縫集成,可與R無縫集成,支持各類BI產品和ETL工具,能解決各種數據挖掘算法的應用場景
具備企業級高可用和易管理特性
Vertica具備完善的部件失效和節點失效保護能力,和完善的全增量備份機制,以及基于MC的企業級易用性和管理能力。
1.5、vertica 11全新發布
今年,在「Vertica Unify 2021全球峰會」上,Vertica宣布正式推出全新版本Vertica 11
Vertica 11 將為多云和多區域部署提供統一分析、高級分析與機器學習能力,包含主要功能、增強功能與自助式容器工作流,從全新意義上滿足了數據分析驅動型企業的敏捷、效率和安全性要求,就此開啟「統一分析」的新篇章。
詳情參看:Vertica 11 高燃發布!開啟「統一分析」新篇章
二、docker安裝 vertica 11
2.1、docker安裝
# 拉取鏡像
docker pull vertica/vertica-ce:11.0.0-0
# 啟動
docker run -d -p 5433:5433 -p 5444:5444 \
--mount type=volume,source=vertica-data,target=/vertica_data \
--name vertica_ce \
-e VERTICA_PASSWORD=vertica \
vertica/vertica-ce:11.0.0-0
2.2、簡單使用
2.2.1、連接數據庫
-
進入容器
docker exec -it vertica_ce /bin/bash -
連接數據庫
vsql
-
遇到問題
如果剛進去報如下錯,原因是數據庫還沒完全啟動,等待幾秒鐘,重新vsql即可。

2.2.2、操作數據庫
2.2.2.1、創建用戶和schema
-
創建用戶
create user test_user identified by 'test'; -
創建schema
-- 基于某用戶創建schema create schema if not exists test_schema authorization test_user; -- 測試刪除schema create schema if not exists test2_schema authorization test_user; drop schema test2_schema cascade; -
查詢用戶和schema
SELECT u.user_name, s.schema_name FROM users u LEFT OUTER JOIN schemata s ON u.user_name = s.schema_owner;
2.2.2.2、序列
-
查看所有序列
select * from sequences; -
創建序列
CREATE SEQUENCE test_seq MAXVALUE 2147483647 START 1;
-
使用序列
-- 一個新創建還沒有使用過的序列,必須首先執行NEXTVAL,然后才能執行CURRVAL。 SELECT NEXTVAL('test_seq'); SELECT CURRVAL('test_seq'); -- 創建一個id是序列的表 CREATE TABLE test_table(id INTEGER DEFAULT NEXTVAL('test_seq'), name varchar(16), age Integer ); -- insert語句使用 INSERT INTO test_table VALUES (NEXTVAL('test_seq'), 'Tom', 18); -- 默認序列 INSERT INTO test_table VALUES (default, 'Jack', 28);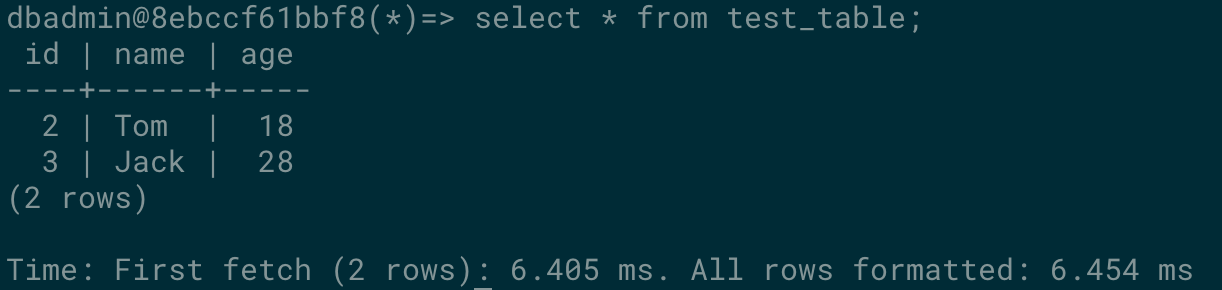
-
刪除序列
DROP SEQUENCE test_seq;
2.2.2.3、操作表
-
創建表
CREATE TABLE test_table(id INTEGER DEFAULT NEXTVAL('test_seq'), name varchar(16), age Integer ); -
修改表
-- 新增字段 alter table test_table add column email varchar(8); -- 修改字段類型 ALTER TABLE test_table ALTER email SET DATA TYPE VARCHAR(32); ALTER TABLE test_table ALTER name SET not null; -- 修改字段名 ALTER TABLE test_table RENAME name TO name2; -- 刪除字段 ALTER TABLE test_table DROP COLUMN email; -- 修改表名 ALTER TABLE test_table RENAME TO test_table2; -- 修改表所屬用戶 ALTER TABLE XXXX OWNER TO xxx; -
刪除表
DROP TABLE test_table; -
查看表
-- 查看表的信息(所有者、創建時間等) SELECT * FROM TABLES WHERE TABLE_NAME = 'test_table'; -- 查看表結構 \d test_table;
2.2.2.4、操作數據
-
增
INSERT INTO test_table VALUES (NEXTVAL('test_seq'), 'Jarry', 38); -
刪
DELETE FROM test_table WHERE name like '%Jar%'; -
改
UPDATE test_table SET age = 19 WHERE name = 'Tom'; -
查
SELECT * FROM test_table ORDER BY id;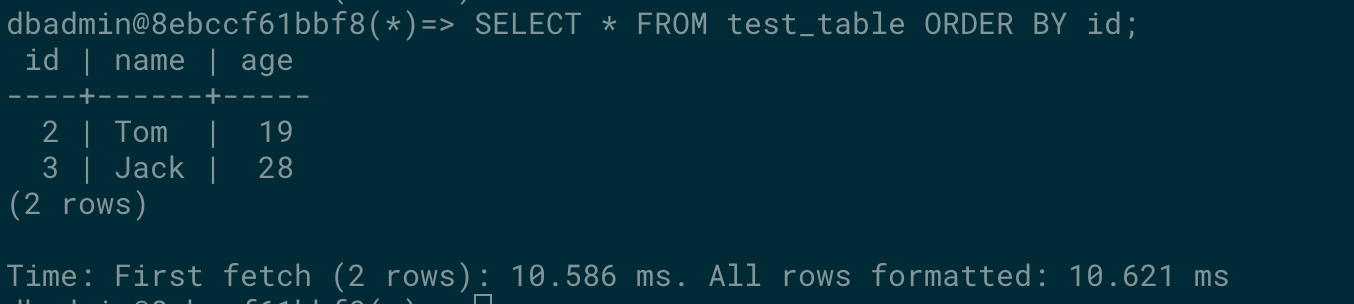
四、java連接測試
4.1、JDBC連接
public static void main(String[] args) {
Properties prop = new Properties();
prop.put("user", "dbadmin");
prop.put("password", "vertica");
prop.put("loginTimeout", "35");
prop.put("binaryBatchInsert", "true");
try {
Connection conn = DriverManager.getConnection(
"jdbc:vertica://xxx:5433/VMart", prop);
System.out.println("連接成功!");
conn.close();
} catch (SQLTransientConnectionException e) {
System.out.print("Network connection issue: " + e.getMessage());
return;
} catch (SQLInvalidAuthorizationSpecException e) {
System.out.print("Could not log into database: " + e.getMessage());
return;
} catch (SQLException e) {
System.out.print(e.printStackTrace());
}
}
4.2、SpringBoot項目
spring:
datasource:
url: jdbc:vertica://xxx:5433/VMart
driver-class-name: com.vertica.jdbc.Driver
username: xxx
password: xxx
hikari:
login-timeout: 30
connection-timeout: 10000
idle-timeout: 600000
max-lifetime: 1800000
五、python連接測試
在使用Vertica時,python可能會用的比較多,因為Vertica ML 將機器學習與數據倉庫相結合,這不僅使核心機器學習功能的訪問民主化,而且大大簡化了將這些模型投入生產的過程。可以使用 Vertica 的 Python 界面來執行整個機器學習周期——從數據準備到跨集群中多個節點的超大型數據集的模型部署。
5.1、安裝依賴
編寫腳本的時候我結合了pandas使用,沒有安裝pandas的裝一下吧,非常必須得一個庫。
pip3 install vertica_python pip3 install pandas
5.2、操作數據庫腳本
根據我平時對別的數據庫的操作方法,改編的腳本,親測好使。
from vertica_python import connect
import pandas as pd
# 連接數據庫
def con_db():
conn_info = {'host': 'ip',
'port': 5433,
'user': 'dbadmin',
'password': 'vertica',
'database': 'VMart',
'read_timeout': 600,
'unicode_error': 'strict',
'ssl': False}
db = connect(**conn_info)
cur = db.cursor()
return db, cur
# 查詢數據
def read_db(sql):
db, cur = con_db()
try:
df_db_data = pd.read_sql(sql, con=db)
except Exception as e:
print('從數據庫獲取數據失敗:' + e)
return df_db_data
# 增刪改數據
def update_db(update_sql):
db, cur = con_db()
try:
cur.execute(update_sql)
db.commit()
except Exception as e:
print('數據更新失敗:' + e)
db.rollback()
cur.close()
db.close()
# 批量插入數據庫
def many_insert_db(insert_sql, list_tuple):
db, cur = con_db()
try:
cur.executemany(insert_sql, list_tuple)
db.commit()
except Exception as e:
print(e)
db.rollback()
cur.close()
db.close()
if __name__ == '__main__':
# 插入數據
insert_sql = "INSERT INTO test_table VALUES (1, 'Jarry', 38);"
update_db(insert_sql)
# 更新數據
update_sql = "UPDATE test_table SET age = 19 WHERE name = 'Jarry';"
update_db(update_sql)
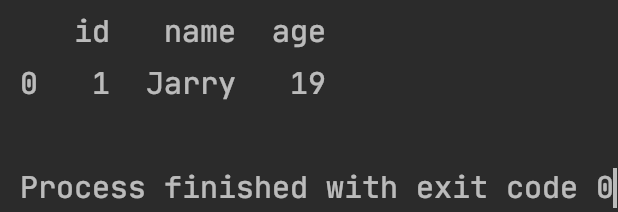
# 查詢數據
select_sql = 'SELECT * FROM test_table;'
df_db_data = read_db(select_sql)
print(df_db_data)
# 刪除數據
delete_sql = "DELETE FROM test_table WHERE name = 'Jarry';"
update_db(delete_sql)
以上是入門了解教程,Vertica還有超多“黑科技”等待大家去探索......
