




大家好,這里是公眾號 DBA學習之路,分享一些學習數據庫路上的知識和經驗。

目錄
前言
下午有開發同事反饋,一條原本執行時間在 1 秒以內的 SQL 突然延長至 16 秒,嚴重影響了產線業務的正常運行。經過我分析和優化之后,SQL 恢復正常,數據庫性能提升 99.99%。

本文將詳細記錄整個問題的定位過程、優化方法及相關思考。
問題分析
數據庫環境為 Oracle 19C RAC CDB 架構(運行了 6 個 PDB),故障發生時間為 2025.11.27 13:11:09.227。
SQL 分析
初步溝通后得知,開發人員通過應用日志監控到某條 SQL 執行時間顯著增加,導致接口超時,進而影響業務流程。
首先,通過 SQLID 3jm7s0g3w2px0 獲取該 SQL 的 AWR SQL 報告(awrsqrpt)。當然,也可以使用 dbms_xplan.display_cursor 來獲取執行計劃:
SELECT * FROM TABLE(dbms_xplan.display_cursor('3jm7s0g3w2px0', NULL));
通過 AWR SQL 報告分析,可以發現該 SQL 存在兩個執行計劃:
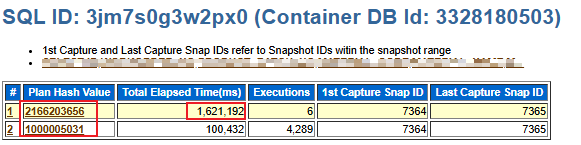
慢的執行計劃采用了全表掃描方式:

從等待可以看出,SQL 執行時間主要消耗在 I/O 等待上:
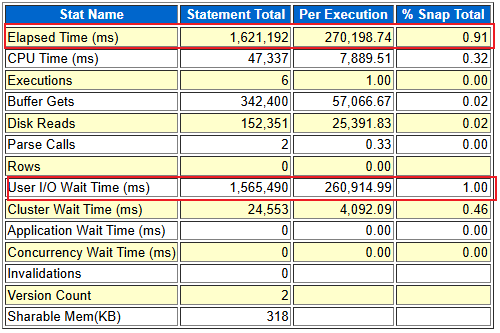
快的執行計劃則使用了索引訪問:

索引訪問的 I/O 等待明顯減少:
基于經驗判斷,這很可能是由于執行計劃選擇錯誤導致的性能問題,解決方向是固定最優執行計劃。
固定執行計劃
可以使用 coe_xfr_sql_profile 腳本來固定執行計劃:
-- 參數1:SQL_ID,參數2:需要綁定的執行計劃哈希值
SQL> @coe_xfr_sql_profile 3jm7s0g3w2px0 1000005031
執行后會在當前目錄生成 coe_xfr_sql_profile_3jm7s0g3w2px0_1000005031.sql 腳本,執行該腳本即可完成執行計劃綁定:
SQL> @coe_xfr_sql_profile_3jm7s0g3w2px0_1000005031
驗證綁定結果:
SQL> SET lines 222 PAGES 1000
COL name FOR a60
COL status FOR a10
COL type FOR a10
SELECT name, status, created, type FROM dba_sql_profiles;
NAME STATUS CREATED TYPE
------------------------------------------------------------ ---------- --------------------------------------------------------------------------- ----------
coe_3jm7s0g3w2px0_1000005031 ENABLED 27-NOV-25 03.08.33.103163 PM MANUAL
執行計劃綁定后,開發反饋 SQL 執行速度恢復正常,接口不再超時,產線業務得以恢復。
AWR 分析
雖然表面問題已解決,但我進一步采集了 AWR 報告進行深入分析,結果發現了更嚴重的性能問題。
報告采集時間范圍為 60 分鐘,DB Time 高達 1,592.57 分鐘,平均活動會話數(Avg Active Sessions)達到 23.6,表明數據庫在此期間承受了巨大的性能壓力:

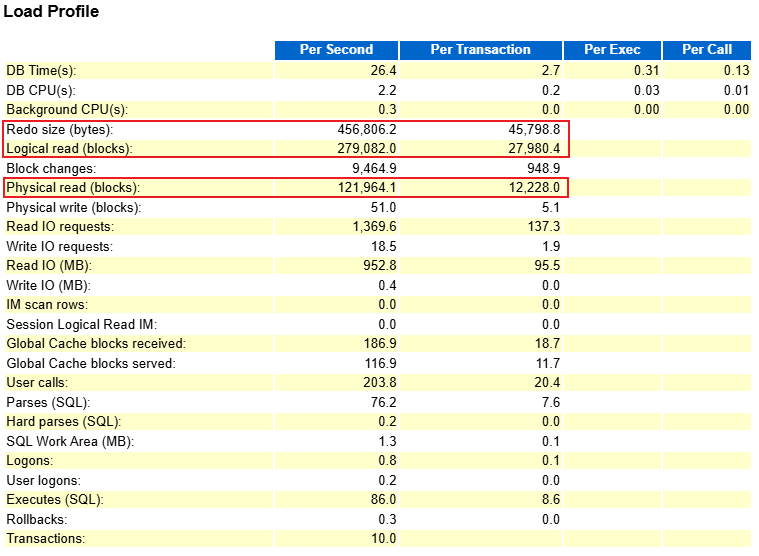
Load Profile 顯示每秒物理讀達到 121,964.1 個塊,Read I/O 吞吐量為 952.8MB/s,其中直接路徑讀(Direct Reads)占比超過 96%,達到 934.242M/s:
Top Event 中 direct path read 等待事件占比 63.5%,總等待時間 60,694 秒,平均每次等待 35.60 ms,遠超 10ms 的健康標準:
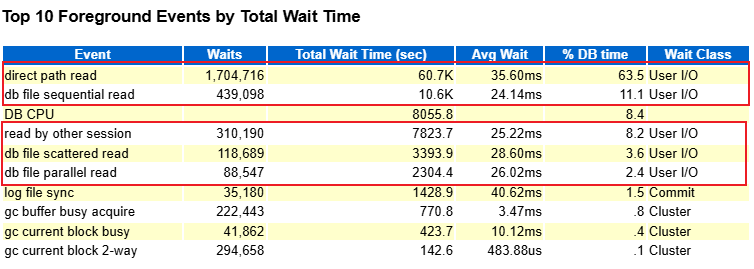
Time Model 分析顯示 sql execute elapsed time 占 DB Time 的 98.33%,而 DB CPU 僅占 8.43%,進一步證實性能瓶頸主要在 I/O 等待:
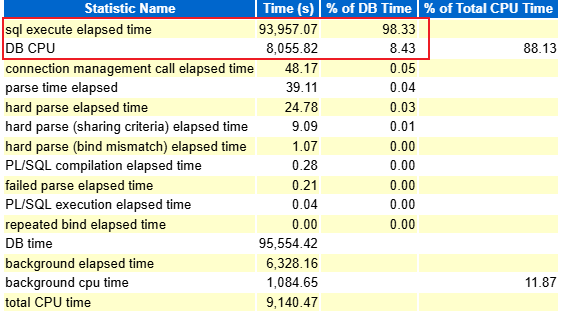
進一步分析發現,SQL ID 為 08n0j9b7uw4pv 的語句物理讀高達 4.32 億次,占總量的 98.12%,執行頻繁且主要等待事件為直接路徑讀,表明該 SQL 對大表進行了大量全表掃描操作,是系統最主要的性能瓶頸:

當 Oracle 在執行大表掃描時會自動啟用直接路徑讀機制,以避免污染 Buffer Cache。但當該等待事件占比過高且平均延時超標時,則說明數據庫中存在高頻執行的大表全表掃描 SQL。
這個庫的 SQL 得垃圾到什么程度啊,大量全表掃描直接讀取磁盤,造成嚴重 I/O 壓力。
該 SQL 的優化方案很簡單:為 WHERE 條件中的字段創建聯合索引。優化后的執行計劃顯示將使用索引范圍掃描:
------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 33 | 3 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 33 | | |
|* 2 | INDEX RANGE SCAN| IDX_XXXXXX_XXX | 1 | 33 | 3 (0)| 00:00:01 |
------------------------------------------------------------------------------------
這個問題也就立刻解決了。
sqlhc 分析
回到最初的問題 SQL,我們使用 sqlhc 工具進行深入分析:
$ sqlplus / as sysdba @sqlhc T '3jm7s0g3w2px0'
分析發現,慢的執行計劃平均執行時間為 7.3s,明顯比開發說的 16s 要低:

仔細觀察可以發現,從 10:00 開始,該執行計劃的執行時間從原來的 0.5s 左右激增至 198s 左右,且主要時間都消耗在 I/O 等待上,且 I/O 等待時間呈現逐漸增長趨勢:
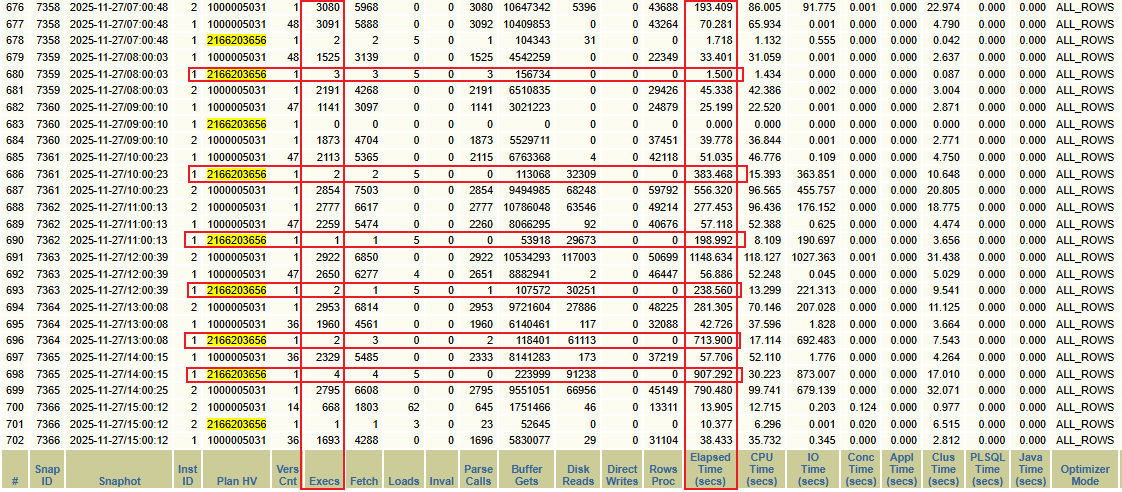
這表明最初 SQL 的性能下降并非單純由于多個執行計劃,而是受到了系統級 I/O 壓力的間接影響。雖然該 SQL 本身存在多個執行計劃也是一個問題,但根本原因在于系統中存在大量全表掃描操作導致的 I/O 資源競爭。
開發質疑
我將上述分析結果反饋給開發團隊后,我建議優化全表掃描的 SQL,并為其增加合適的聯合索引。然而,開發團隊對此提出了幾點質疑:
- SQL 已經創建了索引,為什么優化器選擇了全表掃描而非索引訪問?
- 應用日志明確提示是該 SQL 執行緩慢,應該就是該 SQL 本身的問題,與其他 SQL 無關。
- SPC 庫的 SQL 性能問題,為何會影響到 MES 庫的 SQL 執行?
經過半小時的友好深入溝通,我逐一解釋了這些問題:
- 對于第一點,說明了優化器選擇執行計劃是基于成本估算的,當統計信息不準確或索引選擇性不足時,優化器可能誤判成本而選擇全表掃描。
- 對于第二點,解釋了在共享資源的數據庫環境中,一條高消耗的 SQL 可能影響整個系統的 I/O 性能,進而間接影響其他 SQL 的執行。
- 對于第三點,闡明了在 RAC CDB 環境中,所有 PDB 庫共享存儲資源,任何一個數據庫的 SQL 導致的 I/O 壓力都會影響到整個數據庫。
最終,開發團隊接受了我的建議。
問題解決
隨后,我創建了聯合索引之后,晚上抓了一個 AWR 報告看了下數據庫性能:

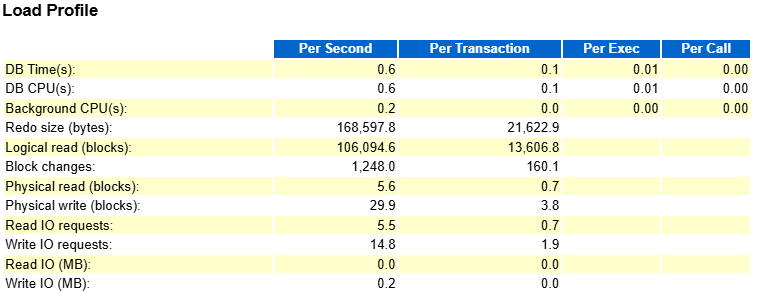
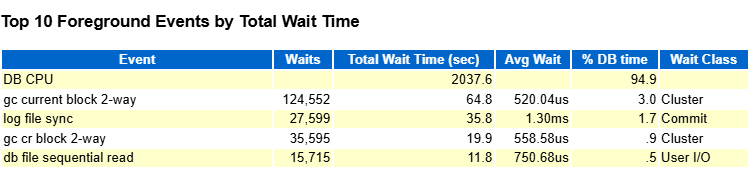
多么健康的數據庫,那條 SQL 也早已從 Top SQL 中消失。所以,回到我們最初的標題——“一條爛 SQL 也能拖垮一個數據庫!” 這絕不是危言聳聽。
寫在最后
說實話,這次問題排查給我上了挺生動的一課。剛開始我也以為就是個簡單的執行計劃跑偏的問題,綁個 profile 就完事了。誰知道越挖越深,最后發現是個“連環案”。
想想也挺有意思的——開發同事看到的是“我的 SQL 怎么突然慢了”,我一開始看到的是“這個 SQL 怎么走錯索引了”,但真正的問題卻是“整個數據庫的 IO 都被打滿了”。就像醫院里來了個病人說頭疼,結果一查是高血壓引起的,再一查發現是腎臟出了問題。
最后想說的是,這次問題雖然解決了,但我心里還是有點沒底——誰知道下一個“IO 殺手”會什么時候出現呢?或許我們應該趁這個機會,好好梳理一下整個數據庫的 SQL 質量了。畢竟,治標不如治本啊。
