




1 問題現(xiàn)象
簡單記錄下之前的一則故障,值班期間有應(yīng)用反饋說某個業(yè)務(wù)的中間實體臨時表無法讀寫和刪除,嚴(yán)重影響業(yè)務(wù)正常辦理。
2 問題分析
2.1 環(huán)境說明
這個業(yè)務(wù)系統(tǒng)所在的庫,是一套8節(jié)點的Oracle 19C版本集群環(huán)境,承載此業(yè)務(wù)的PDB主要跑在4節(jié)點上,其他節(jié)點承載另外的業(yè)務(wù)pdb。
2.2 查看會話數(shù)
按小時去查看活躍會話數(shù)。
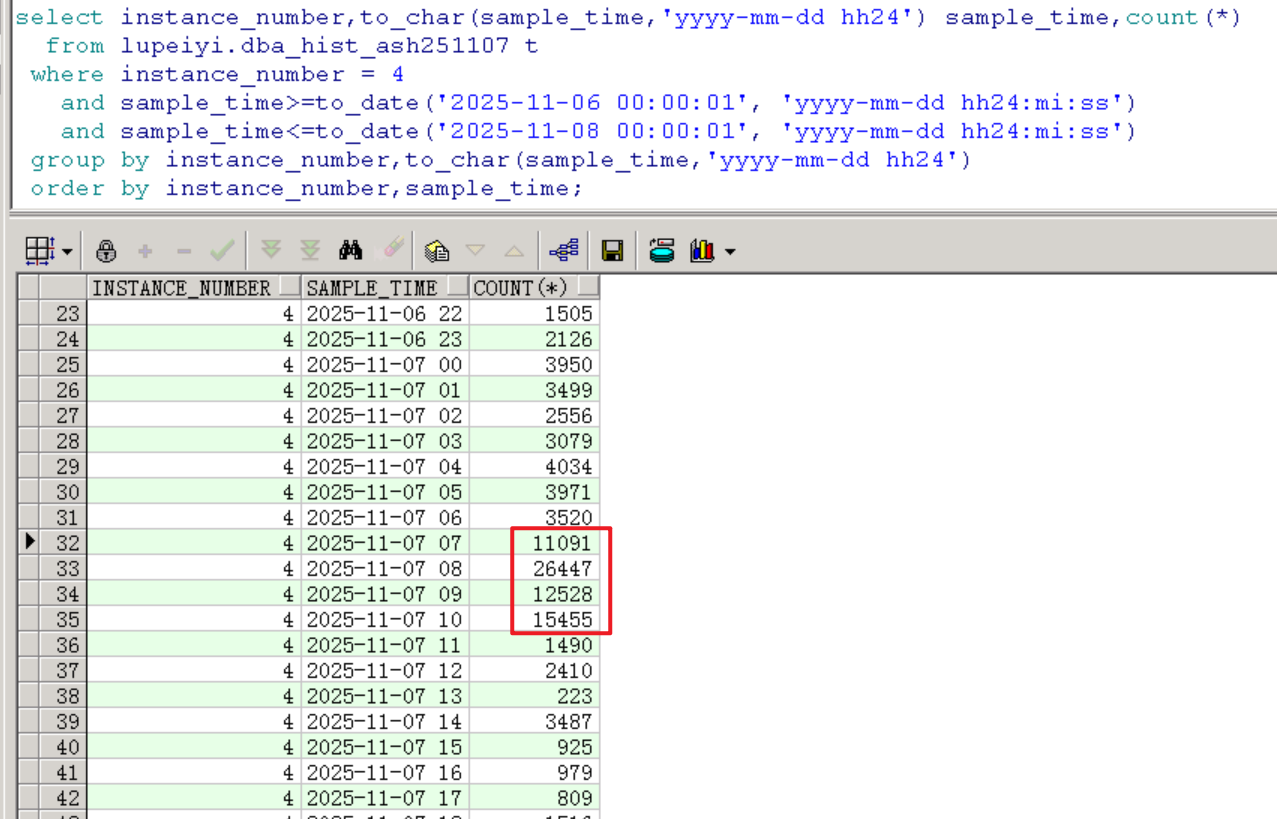
下圖可以看到活躍會話堆積情況,在7號的7點、8點、9點、10點這四個小時里活躍會話有積壓現(xiàn)象,并在8點的時候達到一個峰值26447個,是正常水平情況下峰值的7~8倍。
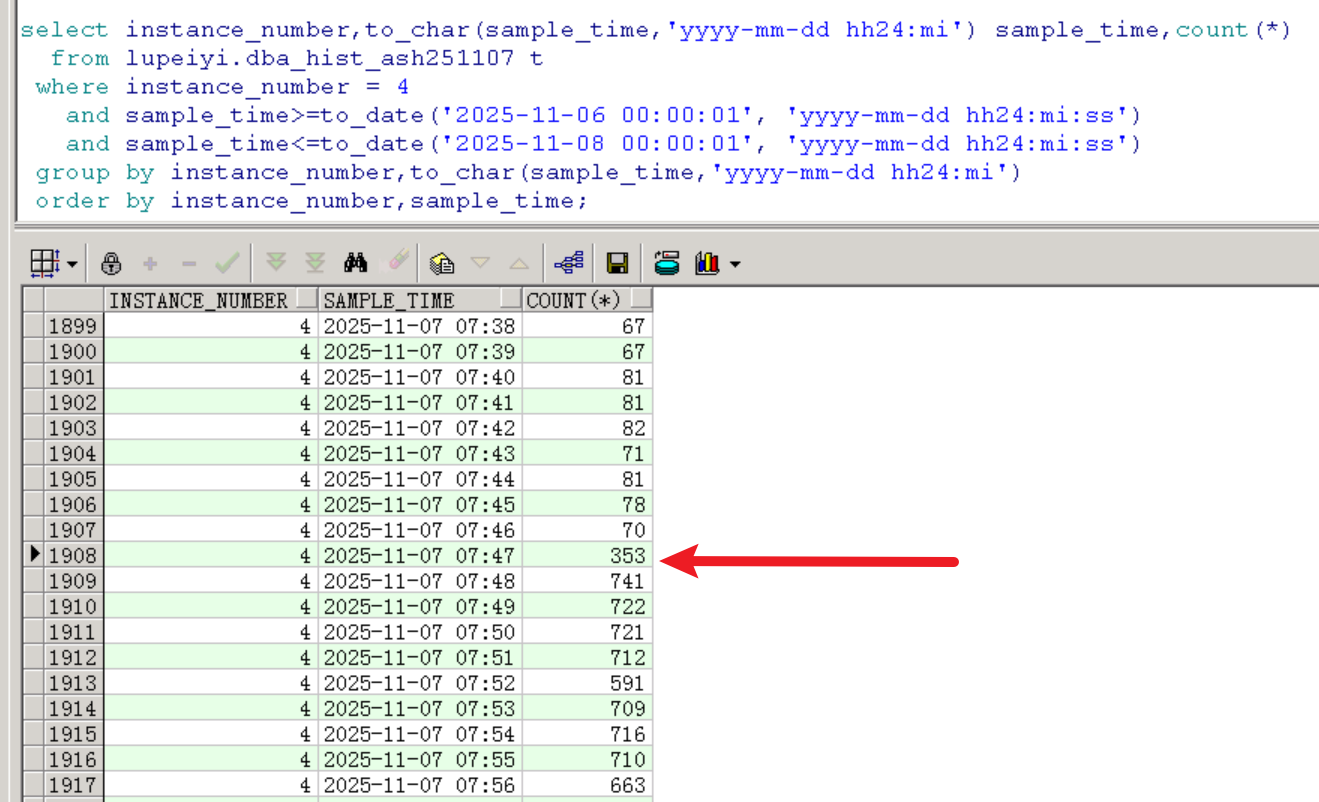
按分鐘查看,會話堆積從7點47分開始,從每分鐘70個突增到幾百個:
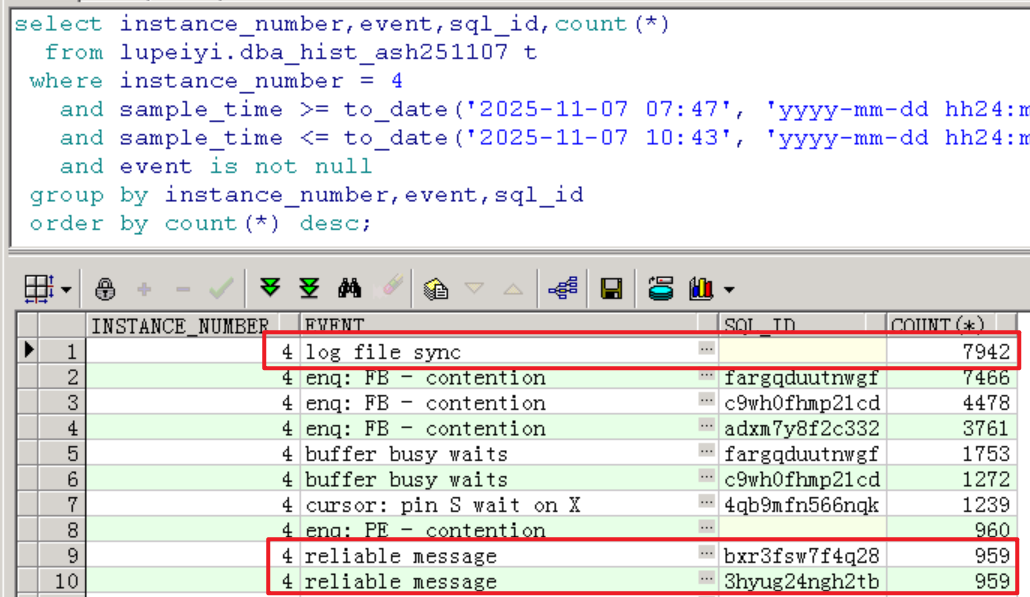
2.3 查看TOP EVENT
如下, Commit類的log file sync等待事件出現(xiàn)大量堆積,存在大量insert會話堆積。Concurrency并發(fā)類型library cache lock等待事件也出現(xiàn)了大量堆積,平均延遲在9點和10點業(yè)務(wù)高峰期間達到1854ms。
reliable message等待事件是跨實例消息傳遞相關(guān),有點類似消息隊列,MOS解釋如下:
- When a process sends a message using the ‘KSR’ intra-instance broadcast service, the message publisher waits onthis wait-event until all subscribers have consumed the ‘reliable message’ just sent. The publisher waits on this wait-event for up to one second and then re-tests if all subscribers have consumed the message, or until posted. If themessage is not fully consumed the wait recurs, repeating until either the message is consumed or until the waiter isinterrupted.
buffer busy waits、enq: FB - contention、enq: HW - contention這些等待事件可以忽略(并發(fā)insert產(chǎn)生的寫寫爭用及維護索引爭用)。
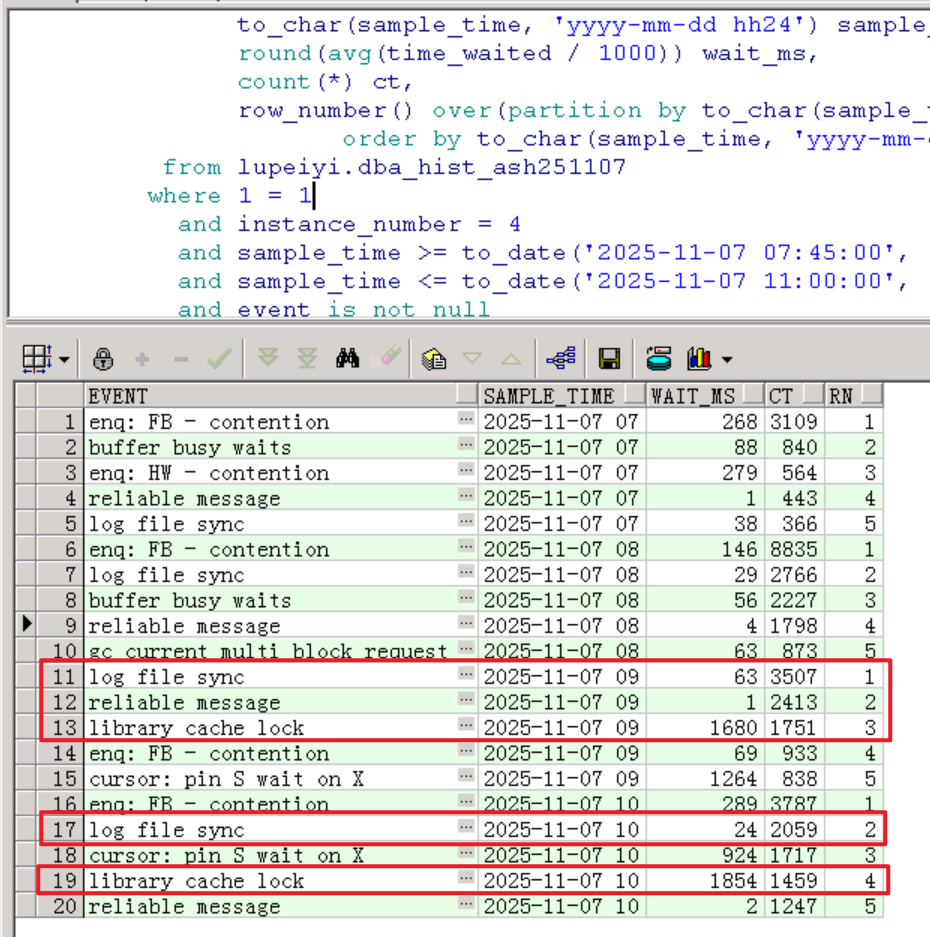
總的Top 10 Event主要是Commit類的log file sync,以及reliable message:
2.4 查看TOP SQL
根據(jù)上面查到的TOP等待事件情況,已知log file sync是由于大量寫操作引起的,下面主要看library cache lock和reliable message相關(guān)的TOP SQL。
可以看到,truncate/drop table有卡住的情況,明顯是不正常的。
更為嚴(yán)重的是,有幾個library cahce lock等待事件相關(guān)的查詢語句的平均延遲達到了1685ms、6023ms、7931ms和10104ms,這是非常嚴(yán)重的性能問題。
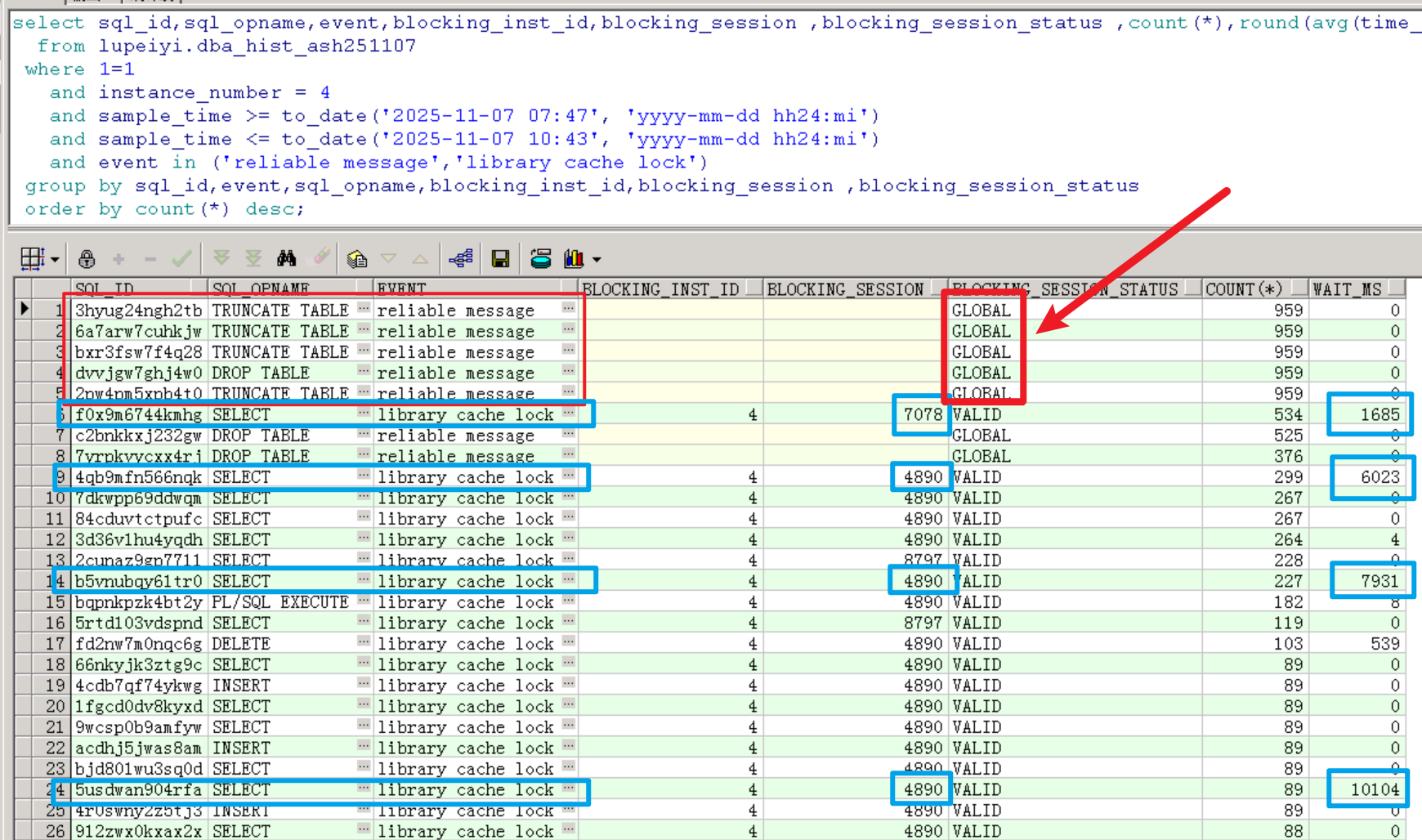
業(yè)務(wù)反饋接口超時報錯的語句正是這些library cahce lock等待事件阻塞而嚴(yán)重延遲的查詢語句,因此為了盡快恢復(fù)業(yè)務(wù),需要優(yōu)先解決這部分的阻塞。
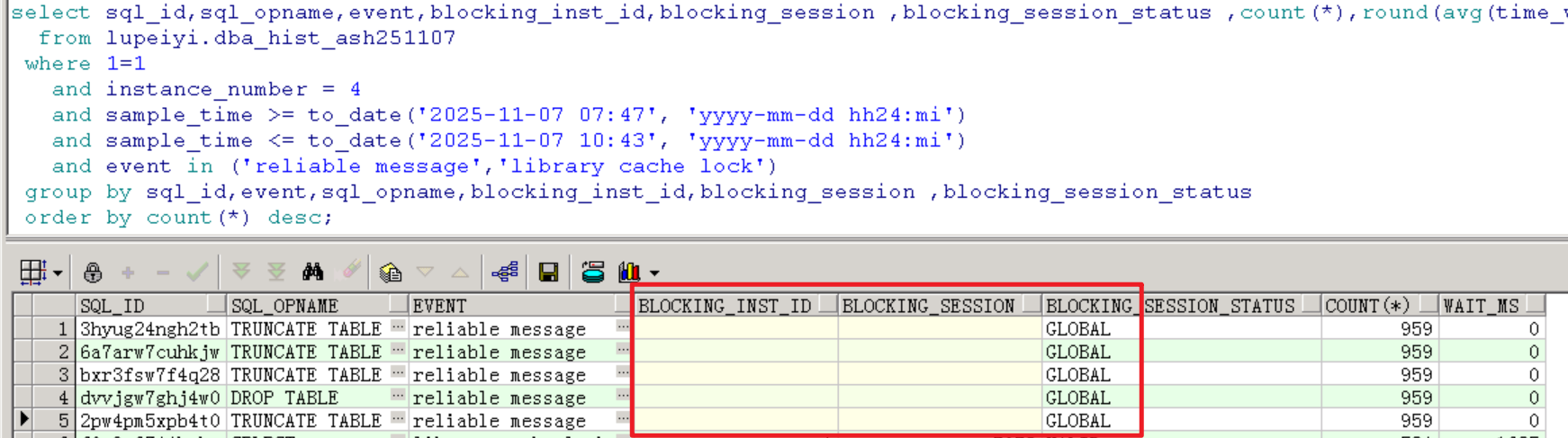
代入相關(guān)sql_id,查看阻塞鏈條,從阻塞鏈條來看,阻塞源都是reliable message等待事件。
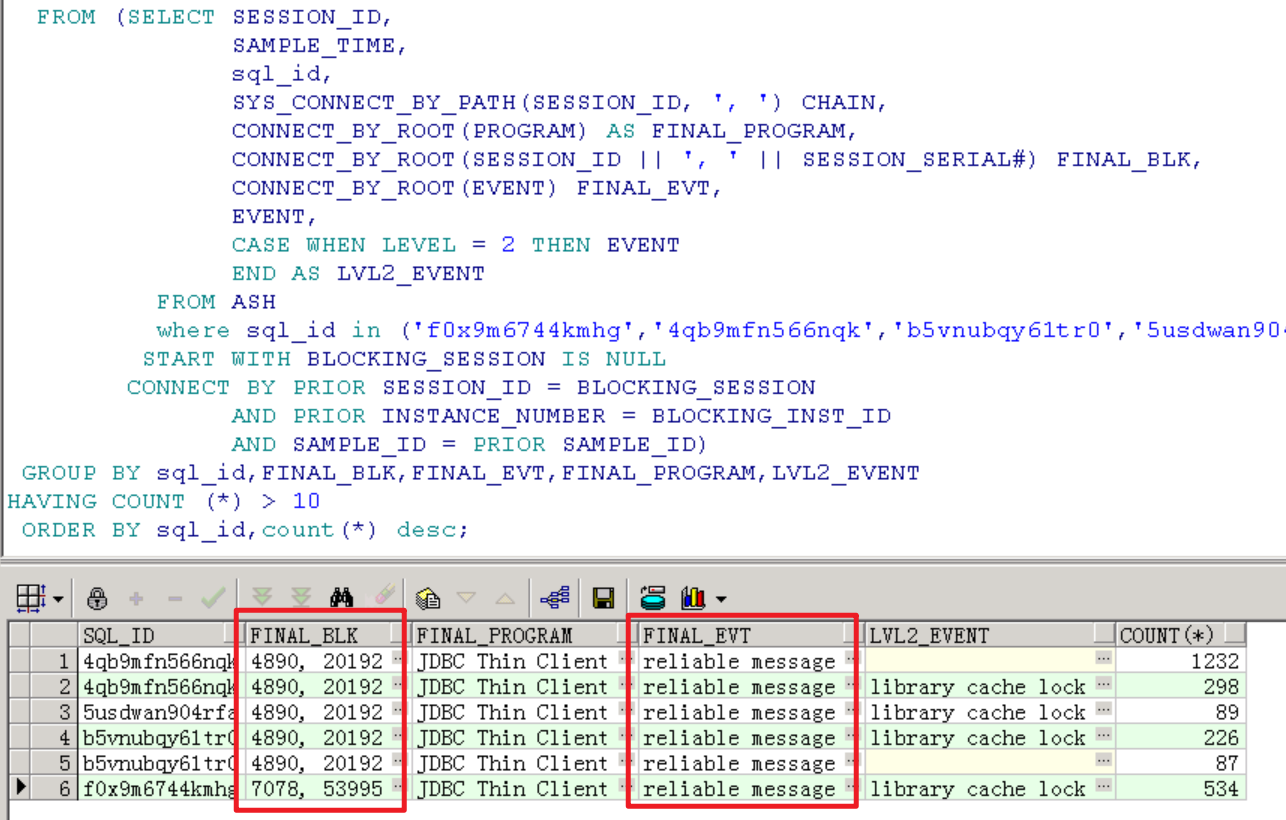
而reliable message等待事件堆積是因為全局性的阻塞,可以看到blk_sess_stat為global,不知道是否因為阻塞源是非活躍會話的緣故,hist_ash這里已經(jīng)看不到blk_sess和blk_inst了。
而在故障當(dāng)天,從gv$session中可以看到阻塞源是節(jié)點8的gen0進程,而節(jié)點8的gen0進程又在等待resource manager。

GEN0 (Generic Background Process)進程是oracle 10g 引入的通用后臺進程,用于處理數(shù)據(jù)庫實例中的各種系統(tǒng)任務(wù)和管理操作,這個進程也是不可以隨便殺的,殺掉會導(dǎo)致實例crash。gen0進程阻塞ddl操作應(yīng)該是因為ddl會涉及對數(shù)據(jù)字典基表(如seg$, obj$, tab$, uet$等)的修改,這些修改需要獲取數(shù)據(jù)字典對象上的鎖(TM鎖)。在RAC環(huán)境中,為了確保所有節(jié)點對數(shù)據(jù)字典有一致的視圖,對這些核心數(shù)據(jù)字典基表的修改需要進行全局協(xié)調(diào),這個協(xié)調(diào)工作可能有GEN0進程參與。
3 處理過程
根據(jù)上面分析過程查到的阻塞鏈條來說,如果我們將resource manager關(guān)閉了,節(jié)點4堆積的會話應(yīng)該就會得到釋放。

去節(jié)點8上執(zhí)行調(diào)整如下參數(shù),作用是關(guān)閉resmgr:
alter system set resource_manager_plan='force:';
但是執(zhí)行上述操作時HANG住了,應(yīng)該是在禁用資源管理器時,Oracle 需要清理資源管理器的內(nèi)部結(jié)構(gòu)、統(tǒng)計信息,并通知所有相關(guān)進程(包括 gen0)資源管理策略已改變,這個過程本身需要資源管理器參與執(zhí)行,這時就和gen0進程相互阻塞了,導(dǎo)致hang住。
節(jié)點8上沒有承載業(yè)務(wù),反饋客戶得到允許去強制關(guān)閉節(jié)點8去釋放gen0進程,數(shù)據(jù)庫重新拉起后再關(guān)閉resmgr:
shutdown abort;
alter system set resource_manager_plan='force:';
強宕節(jié)點8后,節(jié)點4的堆積會話得到了釋放:
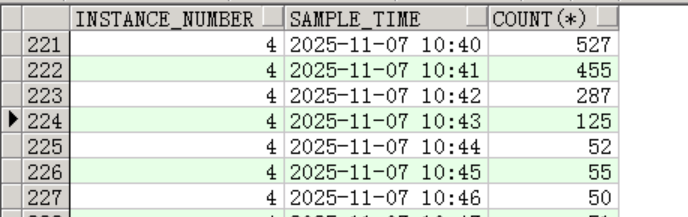
4 總結(jié)
本案例是一個典型的 Oracle RAC 集群中因 Resource Manager 配置不當(dāng)引發(fā)全局性阻塞 的性能故障。故障表現(xiàn)為業(yè)務(wù)接口超時,根本原因是節(jié)點8的 gen0 后臺進程因 Resource Manager 資源爭用被阻塞,進而引發(fā)跨節(jié)點的 reliable message 等待事件堆積,最終導(dǎo)致業(yè)務(wù)節(jié)點(節(jié)點4)出現(xiàn)大量 library cache lock 和 log file sync 等待,會話數(shù)飆升至正常值的7~8倍。
處理過程通過定位阻塞鏈條,最終采取強制關(guān)閉節(jié)點8并禁用 Resource Manager 的方式釋放阻塞,使會話數(shù)在幾分鐘內(nèi)恢復(fù)正常。該方法雖有效,但屬于緊急恢復(fù)手段,存在業(yè)務(wù)中斷風(fēng)險。
