1 初識Vertica
筆者早在2012年之前主要參與運營商網優信令類項目,通過從BTS、BSC、MSC等網絡設備側進行信令數據采用,采用ETL工具對數據進行清洗、轉換等,再將數據加載至數據庫進行分析,為網管網優提供數據支撐,以優化網絡性能、提升網絡通話質量等為目標。當時主要采用的架構是Oracle+小型機+高端SAN存儲,2G的信令數據相對來說還算比較小,通過在數十TB或百TB級規模,但數據庫的處理能力已經可以明顯看到瓶頸,如數據加載效率慢,多表關聯查詢效率低,特別是大表(單表數百億條記錄)的查詢效率很低。
隨著3、4G業務發展,需要對PS域進行數據分析,如GB,IUPS,GN,DPI等接口數據,每天有接近5TB數據需要入庫并進行匯總分析,一個月明細數據達到81TB。數據量的增爆炸式增長也給傳統事務型數據庫帶來了巨大的挑戰,已經無法支撐如此大規模的數據加載和分析任務,必須尋求一種新的技術架構來應對這一問題。在對市場開源和商業多個數據庫進行了比較后,我們選擇了Greenplum和Vertica進行內部測試,在經過模擬實際生產環境的測試后,最終選擇了Vertica數據庫做為我們系統的核心數據庫,于2012年上線了當時國內最大規模的Vertica集群(60節點),所帶來的體驗可以說是從一條擁堵的城市干道換到了高 速公路:-)。
2 遷移核心數倉
隨著業務量及不同維度分析匯總數據的增加,并且隨著分析深度、精度要求的進一步提高,中國移動對經分和互聯網的大數據分析和處理能力就要求更高。以前基于小型機和高端存儲的傳統架構在大數據處理方面處理能力不足、橫向擴展性差的問題越來越突出,已經無法滿足數據分析及快速查詢的新要求了。
2.1 背景
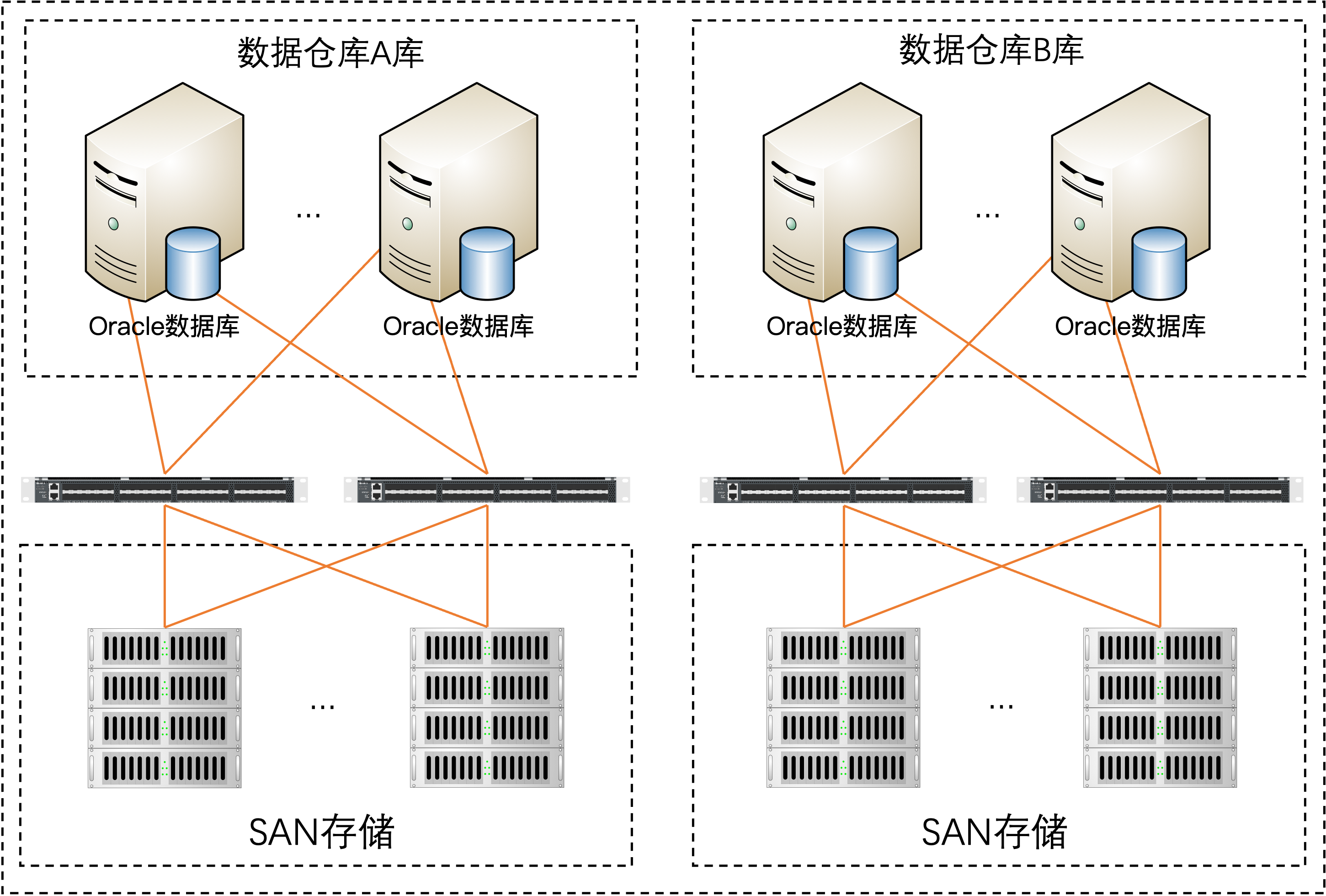
目前經分數據倉庫共有小機12臺部署Oracle RAC數據庫,其中IBM Power780有4臺,ia64 HP superdome SD32B有8臺,峰時CPU使用率長時間100%。存儲方面使用3臺HP XP24000和2臺HP P9500,經分數據倉庫存儲在高峰時期性能已經接入存儲的理論最大值,常期處在高壓力的運行狀況下。
系統整體存在以下問題:
1、數據存儲周期不夠
現有的在線數據存儲能力落后于市場精細化經營分析需求。分析歷史數據需要采用磁帶庫恢復到數據庫的模式, 在恢復時需要事先清理其他周期的數據,恢復一個歷史周期的數據需要約一周時間,影響支撐效率。另外隨著4G業務開展,用戶業務使用量增長迅速,其中數據業務清單數據增速為36%。現有數據倉庫的存儲模式無法支撐快速增長的業務數據存儲要求。
2、系統資源高位運行
現有系統CPU資源消耗忙時長時間接近100%,磁盤IO長時間100%,硬件資源的潛力已經挖盡。
3、現有架構無法擴容
目前數據倉庫架構采用多臺小型機RAC加共享存儲模式,橫向擴展能力不足,小型機相關端口已處于滿配狀態,無法擴容新存儲;共享的RAC模式下主機節點間通訊流量隨主機數量增多成指數上升,已經達到當前技術能力支持的上限而無法繼續擴容主機。
4、現有架構維保費用高
數據倉庫主機和存儲均已過保,維保費用非常高
2.2 方案實現
Vertica數據庫基于無共享的MPP架構,節點完全對等,所有節點均可響應查詢和數據加載請求,支持在線添加數量X86工業標準服務器,可根據需求任意擴展解決方案;通過列式計算和強大的主動數據壓縮,大幅降低磁盤I/O;支持關系數據庫事務處理和ACID規范,支持SQL-92和SQL-99標準,提供ODBC、JDBC、ADO.NET接口規范驅動,完全兼容傳統關系數據庫的開發、使用和管理習慣;在查詢性能方面,速度比傳統數據庫快50~1000倍,同時消耗的成本和占用的硬件僅有原來的幾分之一;Vertica采用K-safety機制來保障集群的高可用,類似RAID功能,且具有數據復制、故障轉移和恢復功能。針對大規模集群,Vertica原生支持容錯組和機架感知,數據跨容錯組分布,即使一個容錯組發生故障,也可保證整個數據庫的數據完整性,從而可以有效避免機柜掉電等大規模硬件故障對整個集群的可用性影響(雖然這種概率極低,但筆記在2017年一個銀行項目中也碰到過,這也充分驗證了Vertica的高可用性)。
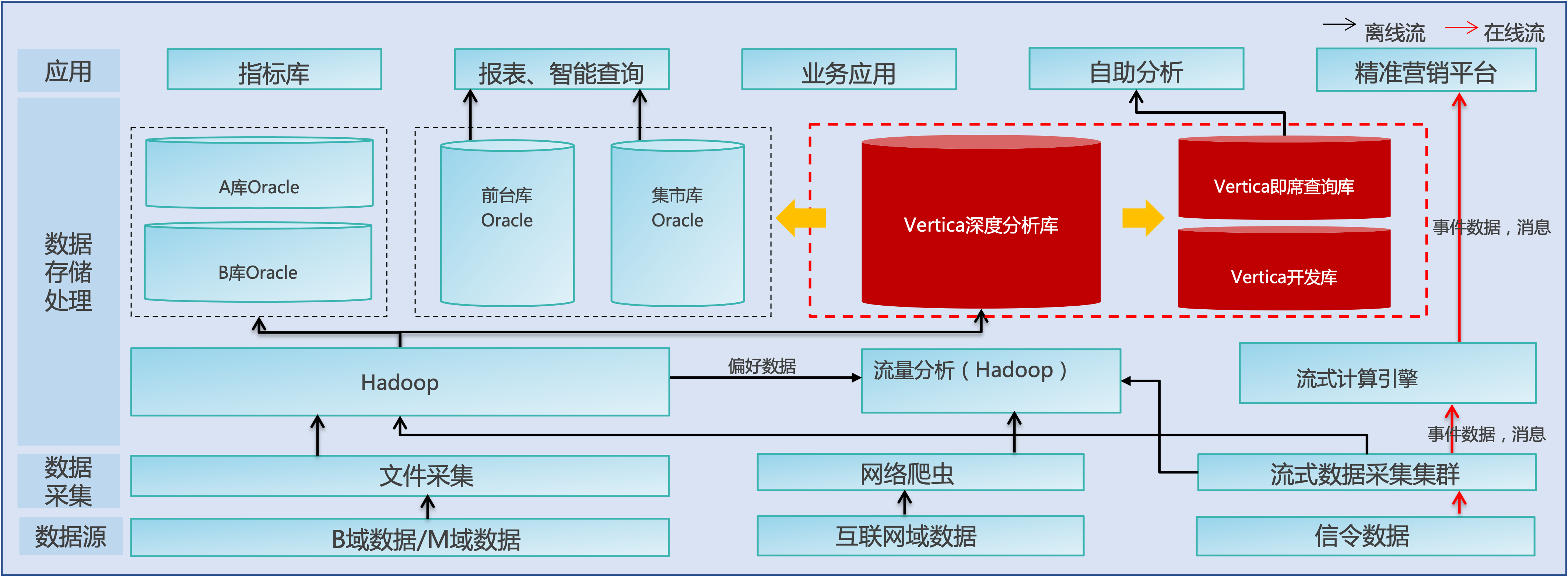
于2016年采用93臺x86服務器搭 建Vertica數據庫集群對經分核心數據倉庫進行遷移,將6萬+模型、1.8萬+個程序、1.7萬+存儲過程、11萬+應用程序適配至Vertica數據庫,遷移過程中以HDFS為數據交互中轉站,將外部系統數據先上傳至HDFS,再通過調度工具將HDFS中的文件并行加載至Vertica數據庫,在Vertica庫進行匯總和分析生成基礎匯總層數據,再進行高度匯總,生成相關報表數據。另分別采用32臺x86服務器搭建Vertica即席查詢庫和開發庫。
針對Oracle數據庫中存在大量存儲過程,通過將存儲過程“翻譯”成perl腳本,調度工具通過ODBC連接Vertica數據庫進行作業調度。遷移后各數據源統一經過Hadoop,再通過并行加載方式直接寫入Vertica數據庫。
注:Vertica 11.0版本支持存儲過程(PL/vSQL),在很大程度上與PostgreSQL PL/pgSQL 兼容,只有細微的語義差異。
2.3 遷移后收益
遷移后Vertica做為該省大數據平臺B域數據計算中心,承擔B域輕度匯總、高度匯總計算任務,按周期存儲B域的匯總模型,并對其他各庫進行數據分發。
- 投資降低
通過x86化部署Vertica數據庫,逐步將Oracle小機+高端陣列的數據倉庫給予下線,降低系統整體采購及維護成本約60%。
- 性能提升
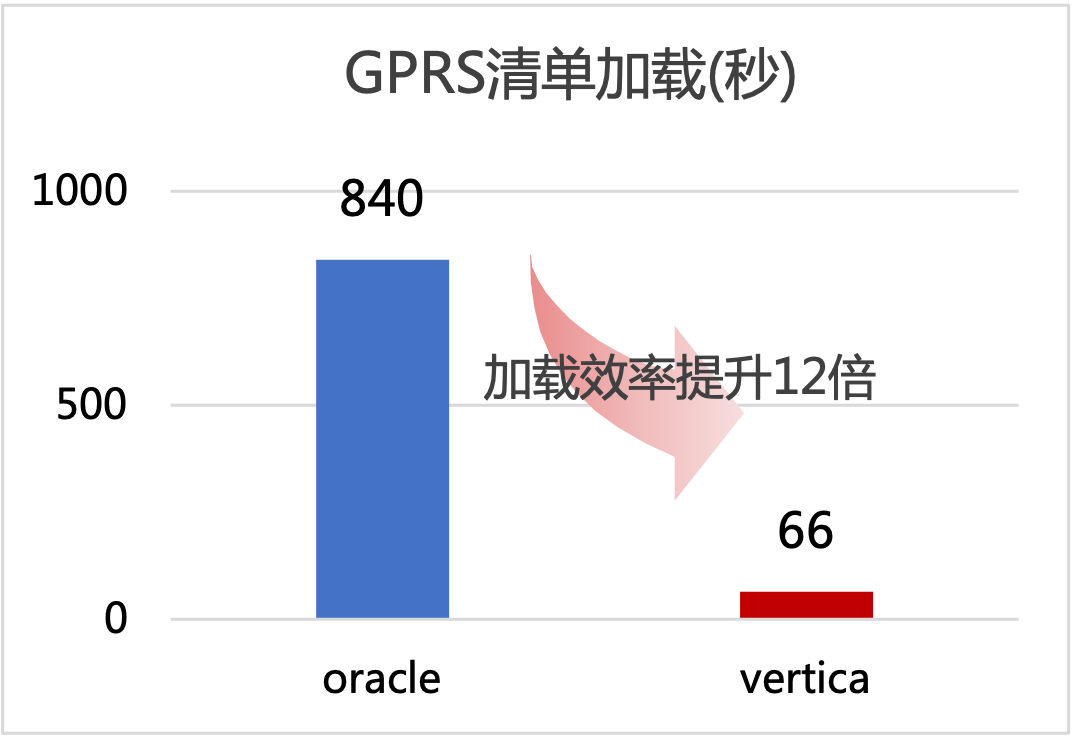
以加載某地市GPRS清單接口為例:加載到Oracle數據庫,用時840秒;加載到Vertica數據庫,用時66秒。數據加載效率提升12倍,大數據平臺接口數據加載效率顯著提升。
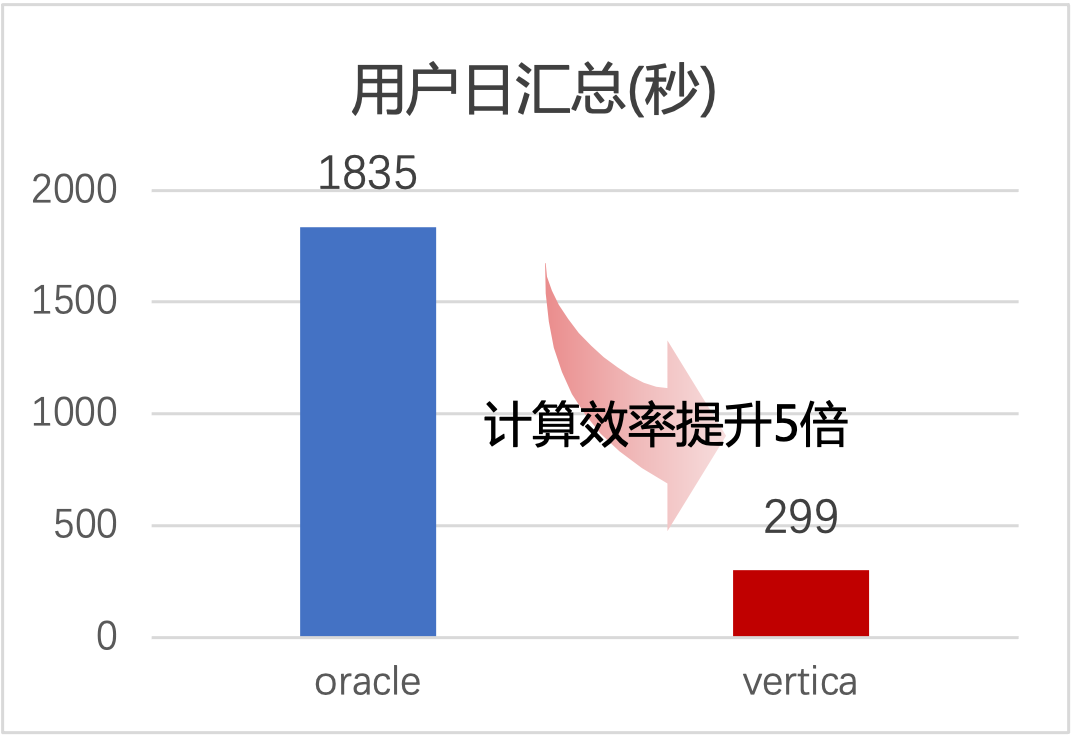
以用戶日數據匯總分析為例:Oracle匯總分析用時1835秒;Vertica匯總分析用時299秒。匯總分析效率提升5倍,大數據平臺數據分析能力得到很大提升。
3 展望:構建統一大數據分析平臺
筆者在所參與過的項目中,經分核心數據倉庫軟件一般采用Oracle、DB2、Teradata,大多采用小型機+高端存儲架構,也有部分采用一 體機案例,由于計算存儲能力不足、橫向擴展性差、維保費用高、跨代擴容兼容性等問題,各運營商正逐步開始往MPP數據庫進行遷移。在對經分核心數倉等系統遷移至MPP數據庫后,各業務場景需求不斷增加、對多域數據融合計算的需求,以及系統擴容、故障恢復、高并發等需求,大數據平臺的一些問題在逐漸突顯出來:
-
多個系統采用多個數據庫平臺,如B域倉庫、集市、自助分析,O域倉庫等,如果需要跨域進行數據分析,則需要在不同庫之間進行同步數據,同步所消耗的時間也帶來數據分析時效性的降低。
-
各系統之間存在較多數據冗余,如B域集市、自助分析、標簽庫等數據均來源于B域數據倉庫,一般冗余量約為30%左右。
-
需要接入更多的使用場景(如自助分析、模型探索、機器學習等),對高并發、資源隔離提出更高的要求。
-
傳統MPP架構下硬件故障需要較長時間進行節點恢復,也帶來了用戶體驗降低,特別是節點磁盤故障導致單節點數據丟失的情況。
-
數據、業務不斷的增長將需要更多的計算和存儲能力,系統需要更高的彈性伸縮能力。
-
計算能力、存儲能力滿足不了業務需求需要擴容,擴容設備配置往往會高于初期配置,導致新擴容設備存在一定資源浪費。
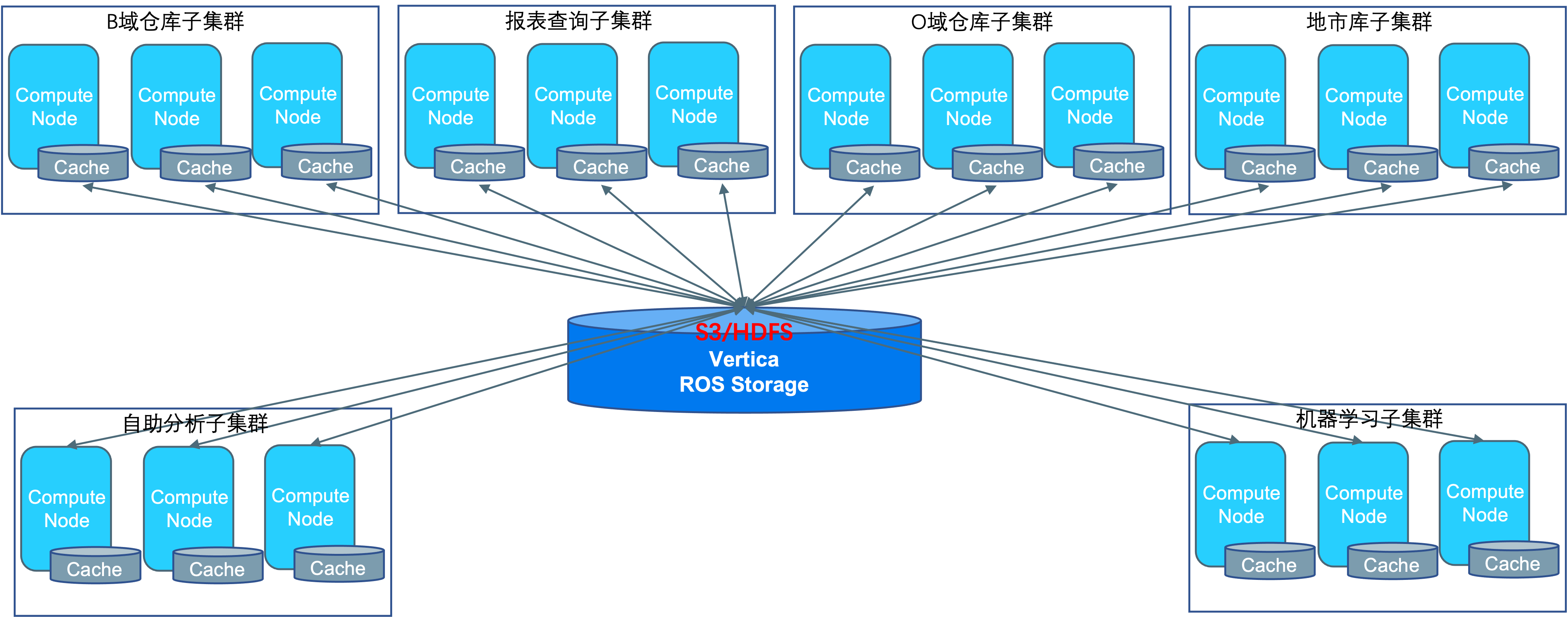
在Vertica 9.0版本之后,Vertica發布了新一代MPP存儲計算分離架構(Eon),計算節點只緩存最近需要使用的數據,底層存儲采用S3對象存儲或HDFS,這將可以很好解決以上問題。
-
不同業務系統采用不同的計算子集群、數據集中存儲在公共存儲中,既可解決計算資源快速擴容、資源隔離、快速恢復等問題,在數據融合存儲后也可以解決數據冗余冗余問題,
-
數據集中存儲后,各業務系統可使用使用同一份數據,不需要進行數據同步。
-
對于O域這類高存儲容量、相對較低計算需求的場景,可以采用高壓縮算法,進一步壓縮存儲空間,節省硬件成本。
-
對于跨域融合數據分析需求,數據集中存儲在公共存儲后,不同業務系統訪問跨域數據時,只需要對相應表進行賦權即可,同時Vertica的行列訪問策略可以更精細的控制數據的訪問權限。
-
通過對跨代硬件使用不同的子集群為不同業務場景提供計算服務,來提升硬件使用周期。
通過采用Vertica 新一代存儲計算分離架構(Eon)對多域數據融合建設,軟、硬件投資或將進一步降低,并為用戶提供一個統一大數據分析平臺。