




引入 | 圖解那些分布式數據庫中的DBMS
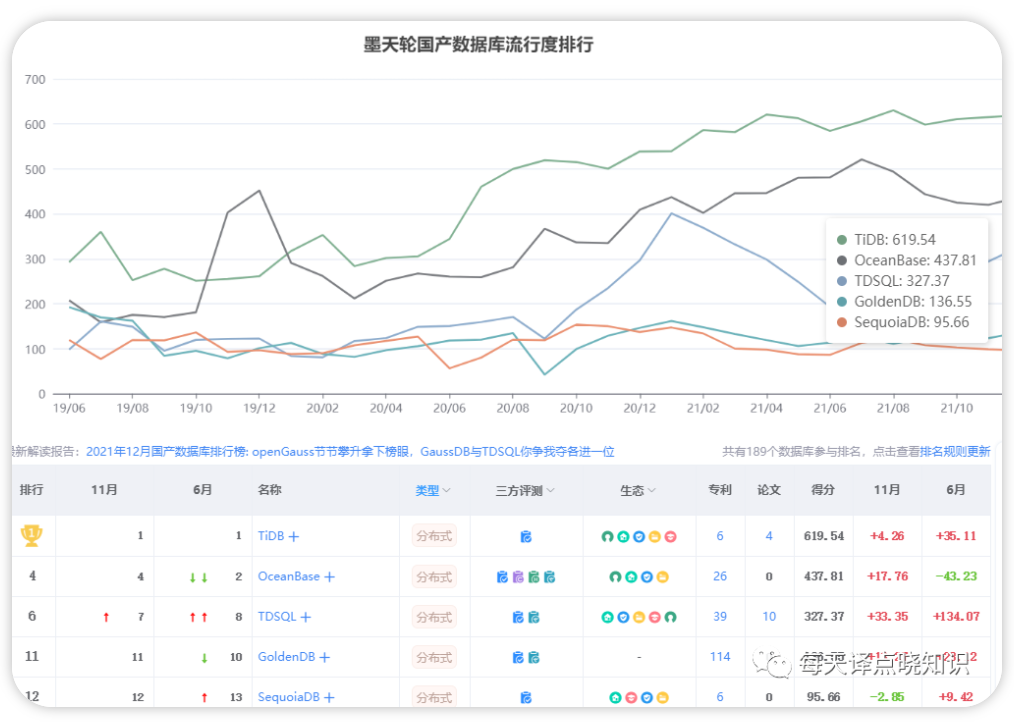
開篇:想必大家都有一個疑問?何為分布式數據庫?OLTP,OLAP,HTAP?它又能夠給我們帶來什么?
背景:在數據庫技術DBMS領域,尤其是針對其中很多核心技術組成部分攻關的突破,國產化數據庫一直都起著模范帶頭作用。許多國內互聯網公司,包括現在很多成熟的技術框架,數據庫都來自于國外。早期,依賴于核心技術的引進,在引進的基礎上做上層應用,進而不斷迭代。而現在核心技術自研,數據庫自研等成了技術攻關的新浪潮。阿里曾一直提出“去IOE”的概念-其中IBM是服務器提供商,Oracle是數據庫軟件提供商,EMC則是存儲設備提供商。
思考:
1、當使用K8、Docker容器化編排技術受到限制,假若Oracle、MySql數據存儲等數據庫軟件不再向我們提供正常的服務?
2、在我們的項目工程中,若是沒有了這些數據庫技術去提供正常的服務,如何能夠去及時地采取補救的措施,使得業務能夠平滑過渡,做到讓用戶無感知體驗?
3、從傳統關系型數據庫到非關系型數據庫,NOSQL,NewSQL再到數據湖,以及兼顧OLAP跟OLTP的各種分布式數據庫-HTAP(混合事務/分析處理),在擁有自己的數據存儲解決方案基礎之上,現有技術框架體系是否能夠較好適配,能否做到更好地兼容?
場景:在現有渠道產品上的適配,推進國產化數據庫進程,包括信創自主可控等領域,都值得作為技術人的我們去深思......
誠然,技術多元化是一個趨勢,多語言并存,多數據庫適配,多環境兼容......
現狀:Oracle,ElasticSearch,MySQL架構
目前,在Oracle中多個業務庫中,數據規模已經非常龐大,MySQL中多個業務庫,其單表數據量都已超過千萬級別,數據每天在不斷的增長......
尤其,在許多老舊的項目中,Oracle視圖數據量非常大,DMP文件數百G,數據存儲成本極其昂貴,這里也提供下大數據量的一些數據庫導入導出方式(相比較工具導入導出或許速度更快一個數量級)
MySQL:
備份數據庫命令:
mysqldump -u root -p 數據庫名 > /home/user/2021.12.26.sql;只需導出表結構:
mysqldump -u applyun -p -d bi > /home/applyun/bi.sql;數據庫遷移導入:
mysql -u root -p 數據庫名 < /home/user/2021.12.26.sql;Oracle:
數據庫遷移導入:
imp yd_dev_tmp/user@ip/orcl file=/home/oracle/xxx.dmp ignore=y full=y;
成功導入數據泵.dmp文件。(其中,可通過su - oracle進入oracle目錄,dmp文件可上傳到/home/oracle路徑)
猜想:
當下的數據庫技術體系,正如春秋時期百家爭鳴的局面,已然無法像傳統關系型數據庫那樣三足鼎立,各個大廠,尤其是互聯網,根據其自身業務需求體系定制化了很多產品,像OceanBase,TiDB,Vertica,ClickHouse,Greenplum......
那么,擁有這么多的選擇權,是不是意味著學習的成本會不斷抬高,我們需要了解擴充的知識面更多?上述僅列舉了正在項目中移植預研的幾款DBMS,更多詳情請回顧->數倉進階 | 記一次OLAP分析引擎演進思考過程
構思:
當我們的業務系統發展到一定規模,不論是累計數據量,亦或用戶并發量。早期,通過單體架構進行設計,應付自如,再大就是分庫分表,解決數據庫單點瓶頸(I/O)。
隨著業務持續發展,單機有著明顯的單點效應,并且單機的容量跟性能都是極其局限的。
進一步,對某些應用進行水平擴容,漸漸的,雖然各個應用服務器CPU都正常,但是你會發現還是有很多慢請求依然存在,究其緣由-單點數據庫性能瓶頸?
更進一步,數據庫集群-主從架構,大部分讀操作可直接訪問從庫,減輕主庫的負擔,但依舊還是無法解決主庫寫的瓶頸?
接下來,就是上述提到的分庫分表,分庫分表可作水平拆分-對表進行進一步拆分,垂直拆分-不同功能表放置不同的庫,按業務功能進行拆分。
然而,當相同的應用擴展越多,每個數據庫的鏈接數,長久以往必會讓數據庫本身的資源再度成為瓶頸,簡言之,資源隔離性依然不徹底->未形成單元化的雛形。

再談經典,
Google三駕馬車,在分布式系統工程實踐領域:
《Google File System》、《Google MapReduce》、
《Google BigTable》在很大程度上奠定了業界大規模分布式存儲系統的理論基礎.
回到CAP理論,想必在分布式領域中這個著名的定理都有所耳聞,即C為數據一致性,A 為服務可用性,P為服務對網絡分區故障的容錯性。
談及CAP,這里暫不詳贅,各有各自不同深度層次的見解,但這里需要說明下的就是選擇CP的分布式系統,并不代表可用性就完全沒有了,比如像我們常用的中間件,為了增加可用性保障,往往提供了分片集群-復制的一些方案。
包括常說的BASE理論-對CAP理論的延伸,核心思想-即使無法做到強一致性(Strong Consistency),但我們的應用可以采用適合的方式達能夠到最終一致性(Eventual Consitency)。
從上述提到由單點現狀->分布式架構演進構思的過程中,出現諸多不同階段性痛點,想必這也是為什么那么多分布式數據庫產品如雨后春筍般不斷涌出?
OceanBase-中國第一款自主研發的分布式數據庫(簡稱OB)
企業級分布式關系數據庫
a)數據強一致
b)高可靠
分區-副本機制
c)高性能
Paxos協議,在數據強一致的情況下,具有極高的可用性及性能
d)在線擴展
當集群存儲容量或是處理能力不足時,可以加入新的OBServer
e)高度兼容SQL標準和主流關系數據庫
f)低成本
CPU、操作系統、數據庫
如何既兼顧處理TP場景的能力,又具備AP場景的分析能力?
想必HTAP架構希望打破TP和AP的邊界,雖然存在很多技術難關需要攻克,一直在路上,期待OceanBase(OB)一直會有新的突破......
延伸思考:HTAP(混合事務/分析處理),相比OLTP、OLAP能夠給我們帶來?OceanBase又是如何支持HTAP?
在高并發海量數據場景下,是否能讓系統中諸多計算節點同時運行OLTP類型的應用和復雜的OLAP類型的應用......
「 往期文章 」
Elasticsearch讀寫數據工作原理 | MySQL的重復數據插入處理
Elasticsearch進階篇 | 記kibana執行dsl腳本實戰過程
Kafka | 記一次修復Kafka分區所在broker宕機故障-引發當前分區不可用的思考過程
開源數據庫 | 記一次基于鯤鵬歐拉操作系統openGauss實踐過程
序列化 | Google的Gson與Alibaba的FastJson機制

