




目錄

查詢優(yōu)化存儲

列式存儲體系架構(gòu)是Vertica數(shù)據(jù)庫的核心,實際上Vertica是世界上第一個列式存儲數(shù)據(jù)庫,它是在2005年發(fā)表的學(xué)術(shù)論文C-Store的基礎(chǔ)上推出的適用于大規(guī)模并行處理場景的真正意義上的分布式數(shù)據(jù)庫。

上面是Vertica的SQL專家和Hadoop專家解釋列式存儲是如何工作的一個原理圖,左邊的表“sales”是表的邏輯結(jié)構(gòu)(按列存儲),包含三個列A,B和C。右邊的三個投影“sales_p1”,“sales_p2”和“sales_p3”分別對應(yīng)下面的三個投影示意圖,它們是實際的物理存儲結(jié)構(gòu)。
投影實際上是一組經(jīng)過排序和壓縮的存儲在磁盤上的一個文件集合,這個投影類似于聚集列索引(它和表的存儲有很大的不同),您可以認(rèn)為它是只存儲了索引結(jié)構(gòu)。投影的定義類似于帶有一個AS SELECT子句的物化視圖,正如您在上面的圖中所看到的三個投影,“CREATE PROJECTION AS SELECT A, B, C FROM sales ORDER BY A;”,“CREATE PROJECTION AS SELECT B, A, C FROM sales ORDER BY B, A;”,“CREATE PROJECTION AS SELECT C, A FROM sales ORDER BY C;”。
您可以指定更多選項,而不僅僅是列和排序順序,但是這些是最低需求。它和物化視圖不一樣的是您不必刷新視圖,當(dāng)您在表中插入數(shù)據(jù)時也沒有必要更新索引,表的數(shù)據(jù)在加載過程中會立刻轉(zhuǎn)換為投影。
如果您熟悉Hive,您很可能現(xiàn)在已經(jīng)意識到投影非常像Hive里的表,可以將其視為在虛擬表的背后有多個Hive表,以便您可以在不同類型查詢的流水線聚合中獲得合并聯(lián)接。

自動數(shù)據(jù)庫設(shè)計
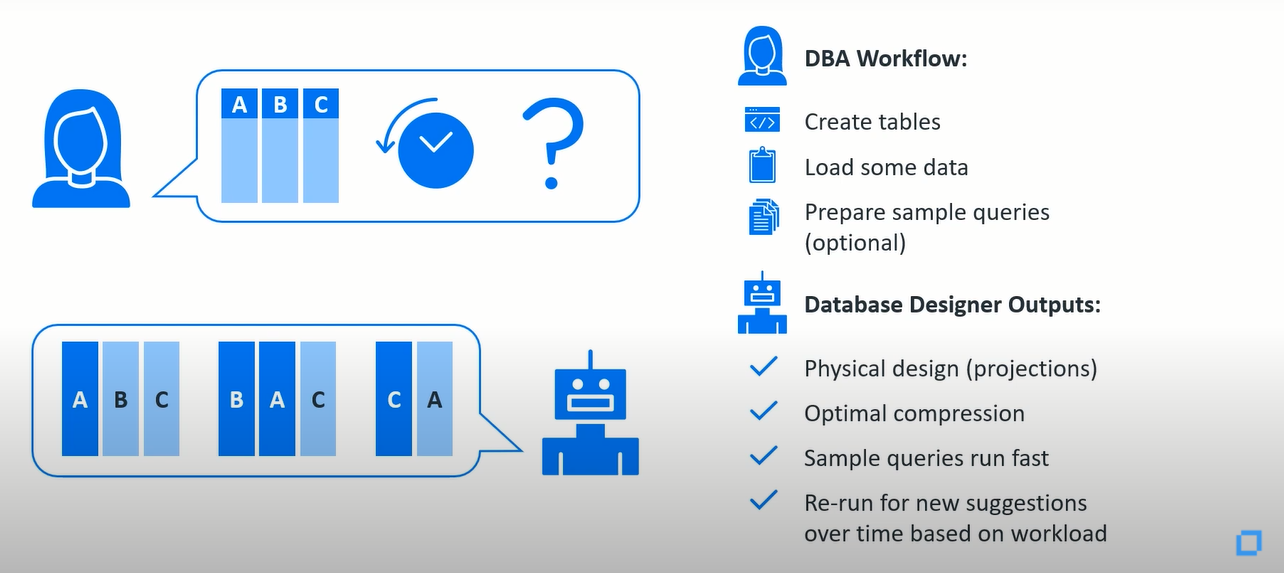
在大多數(shù)情況下,最佳壓縮排序和分布式投影的規(guī)則很簡單,它可以直接從查詢中導(dǎo)出。所以我們?yōu)槭裁匆ㄙM時間手動處理它呢?通過一種稱為數(shù)據(jù)庫設(shè)計器的特殊工具能夠自動創(chuàng)建投影,這種工具根據(jù)您的工作負(fù)載自動為您建議行存儲中的索引。
例如,我作為銷售工程師做POC測試的典型工作流程是接收我們的Oracle或Microsoft數(shù)據(jù)庫的備份以及一些查詢,我需要對它們的表現(xiàn)進(jìn)行基準(zhǔn)測試,而且我通常必須在一周內(nèi)完成所有工作。為了防止積壓工作的增加,所以我要做的是將Oracle或Microsoft的創(chuàng)建表的語句轉(zhuǎn)換為Vertica數(shù)據(jù)庫的SQL語句。
首先,使用自動轉(zhuǎn)換器從源數(shù)據(jù)庫加載一些數(shù)據(jù)到Vertica數(shù)據(jù)庫,然后準(zhǔn)備我需要的示例查詢優(yōu)化,最后我將所有這些都輸入到數(shù)據(jù)庫設(shè)計器中。這通常是一個物理設(shè)計,它設(shè)計所有的創(chuàng)建投影語句。數(shù)據(jù)被優(yōu)化壓縮以后,示例查詢會運行得很快,當(dāng)工作負(fù)載發(fā)生變化時,稍后它可以增量運行。
現(xiàn)在,數(shù)據(jù)庫設(shè)計器從一開始就做了一個很好的工作。很明顯地,在大多數(shù)情況下,我給它一個B+或 a-,如果您知道了編碼壓縮的來龍去脈和交叉執(zhí)行計劃等,您總是可以手動地進(jìn)一步優(yōu)化。

在列存儲中準(zhǔn)實時分析

列式存儲是存儲格式,例如,Hadoop中使用的Parquet文件格式非常適合批量讀取數(shù)據(jù)和處理數(shù)據(jù)。事實上,作為原生列式存儲的Vertica字面意思叫做ROS或者讀優(yōu)化存儲,但是如果你需要寫數(shù)據(jù)(插入一些行或更新某些內(nèi)容或?qū)崟r地流數(shù)據(jù))并立即查詢,這對于行存儲(例如,Oracle或PostgreSQL)來說從來都不是問題,它們是最初針對寫入更新進(jìn)行了優(yōu)化,但是當(dāng)您按行存儲時被迫使用諸如索引之類的依賴來解決讀取性能問題。所以讀取最好的選擇是列存儲,而寫入最好的選擇是行存儲或內(nèi)存存儲,這就是Vertica數(shù)據(jù)庫具有混合存儲體系架構(gòu)的原因所在。
我們有一個基于磁盤的列式讀取優(yōu)化存儲,我們有一個內(nèi)存寫入優(yōu)化存儲,這是任何插入和更新的默認(rèn)選項。這讓Vertica能夠支持實時查詢這個核心功能,因為它的唯一缺點是能夠接受幾行數(shù)據(jù)的插入或更新,并在事務(wù)完成以后,內(nèi)存中的數(shù)據(jù)只需幾毫秒即可用于讀取到磁盤,然后在查詢時進(jìn)行合并,通常在幾分鐘后的某個時間點它通過后臺進(jìn)程刷新到磁盤,形成一個新的排序和壓縮的存儲容器,然后在通過后臺進(jìn)程再次合并存儲容器。如果您批量加載并且不想浪費內(nèi)存,則可以將數(shù)據(jù)直接寫入磁盤。因為在這種規(guī)模上進(jìn)行實時分析的任何其他選擇將涉及多種產(chǎn)品的臨時混合架構(gòu)。
有很多博客文章解釋到,我們?nèi)绾翁幚鞨ive的變化量文件,然后將其與Hive查詢結(jié)合起來,這些方法都非常復(fù)雜,就是插入、更新和提交。讓更少的人做更少的工作是明智的,這一切都是開箱即用的,更重要的是開箱即用,有一流的企業(yè)支持。

自動數(shù)據(jù)集市

多表聯(lián)接是一個性能殺手,請確保您有合并連接和列式存儲之類的功能,讓事情變得更好。但是在白天的工作時間之內(nèi)到了快要下班的時候,你仍然在獲取來自多個不同地方的數(shù)據(jù),并且很好地將它們連接在一起,這顯然需要時間,而且每個查詢都需要這樣做。這就是為什么數(shù)據(jù)集市長期以來一直是轉(zhuǎn)到“需要頻繁查詢數(shù)據(jù)的選項”以查看數(shù)據(jù)。當(dāng)數(shù)據(jù)發(fā)生變化時,需要刷新到數(shù)據(jù)集市,這可能會造成大量耗時的計算,除非您只刷新已經(jīng)被更改的那一部分,但是也存在其他問題。
考慮到這一點,多表聯(lián)接已經(jīng)不是一個微不足道的殺手了,這項功能已經(jīng)使用了幾年。為了讓大多數(shù)的數(shù)據(jù)使用場景更加簡單,是否可以將計算列添加到可以從另一個表中查找值的表中,或者是您可以使用任何其他表達(dá)式來合并一些表,這些表包括或不包括每行返回任何一個值。如果數(shù)據(jù)集市只是簡單地從維度表中查找具有列的實際表,您可以添加從該維度表中選擇的值,然后將新數(shù)據(jù)插入到實際表中,然后單擊“新建”自動填充值,更新維度表并刷新單個列。它真得是非常快,因為您知道列存儲更新實際表中的兩個鍵僅在最后一天刷新一列,或者以更快的速度對數(shù)據(jù)進(jìn)行分區(qū)。
另外,由于數(shù)據(jù)和計算列不是獨立的,所以它是免費的不計入許可容量,您只需為此類數(shù)據(jù)集市的已使用部分付費。

多維數(shù)據(jù)集的預(yù)聚合

當(dāng)我們在上一個特性中討論數(shù)據(jù)集市的主題時,請考慮一下,您正在獲取的數(shù)據(jù)容量每天都在TB級以上。您會怎么做?
- 從磁盤讀取千兆字節(jié)的數(shù)據(jù)并為每個查詢?nèi)哂嗑酆希?/span>
- 您是否使用聚合數(shù)據(jù)創(chuàng)建單獨的表并使用復(fù)雜的邏輯對其進(jìn)行更新?
- 您是否在數(shù)據(jù)庫前放置了一個OLAP引擎來聚合您的數(shù)據(jù)從而增加了硬件的成本和復(fù)雜性?
不,您可以向表中添加投影(PROJECTION)功能。它按您需要的所有產(chǎn)品分組并匯總您需要的所有指標(biāo),這就是所謂的實時聚合投影,然后與所有其他投影一起刷新,每次提交。
現(xiàn)在您不需要增加邏輯的復(fù)雜性或硬件成本和附加軟件,將為您進(jìn)行內(nèi)存聚合,現(xiàn)在一切都來了!開箱即用,更重要的是開箱即用!!!
以上就是這篇文章的所有內(nèi)容,歡迎您在文章底部的評論區(qū)留下反饋意見。在下一篇文章中我將介紹Vertica數(shù)據(jù)庫脫穎而出的另外5個特性,敬請期待!!!
