




Nigel Bayliss | November 8, 2011
產(chǎn)品經(jīng)理
原文鏈接:https://blogs.oracle.com/optimizer/post/lies-damned-lies-and-statistics
理解和管理優(yōu)化器統(tǒng)計信息是優(yōu)化SQL執(zhí)行的關(guān)鍵。知道何時和如何及時收集統(tǒng)計信息對于保持可接受的性能是至關(guān)重要的。為了澄清與統(tǒng)計信息相關(guān)的所有信息,我們將兩篇有關(guān)優(yōu)化器統(tǒng)計信息的白皮書一并提供出來,他們是:
使用Oracle Database 12c Release 2收集優(yōu)化器統(tǒng)計信息的最佳實踐
理解Oracle Database 12c Release 2的優(yōu)化器統(tǒng)計信息
介紹
當(dāng)Oracle數(shù)據(jù)庫首次引入如何執(zhí)行SQL語句的決策時,是由基于規(guī)則的優(yōu)化器(RBO)決定的。顧名思義,基于規(guī)則的優(yōu)化器遵循一組規(guī)則來確定SQL語句的執(zhí)行計劃。這些規(guī)則是經(jīng)過排序的,因此,如果有兩個可能的規(guī)則可以應(yīng)用于SQL語句,則將使用排名最低的規(guī)則。
在Oracle Database 7中,為了處理當(dāng)時添加到數(shù)據(jù)庫中的增強功能,包括并行執(zhí)行和分區(qū),以及處理實際的數(shù)據(jù)內(nèi)容和分布,基于成本的優(yōu)化器(CBO)被引入了。基于成本的優(yōu)化器會檢查一條SQL可能的所有執(zhí)行計劃,并選取成本最低的一個。這里的成本表示對于給定的執(zhí)行計劃,資源使用量的評估。成本越低,執(zhí)行計劃的效率越高。為了使基于成本的優(yōu)化器可以精確地確定給定執(zhí)行計劃的成本,就必須擁有SQL中訪問的所有對象(表和索引)的信息,以及運行該SQL的系統(tǒng)的信息。
這些必須的信息通常統(tǒng)稱為優(yōu)化器統(tǒng)計信息。理解和管理優(yōu)化器統(tǒng)計信息是優(yōu)化SQL執(zhí)行的關(guān)鍵。知道何時和如何及時收集統(tǒng)計信息對保持可接受的性能是至關(guān)重要的。本白皮書是關(guān)于優(yōu)化器統(tǒng)計信息的兩部分系列文章中的第一篇,通過實例,詳細描述了優(yōu)化器統(tǒng)計信息的不同概念,包括:
- 統(tǒng)計信息是什么
- 統(tǒng)計信息收集
- 統(tǒng)計信息管理
- 統(tǒng)計信息的附加類型
統(tǒng)計信息是什么?
統(tǒng)計信息是描述數(shù)據(jù)庫及數(shù)據(jù)庫中對象的數(shù)據(jù)的集合。統(tǒng)計信息供優(yōu)化器為每條SQL選擇最優(yōu)的執(zhí)行計劃,它存儲在數(shù)據(jù)字典中,并可通過諸如USER_TAB_STATISTICS這類數(shù)據(jù)庫字典視圖來訪問。
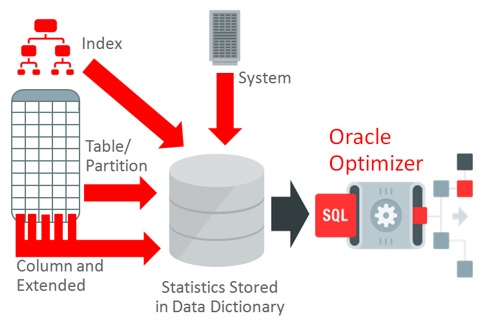
圖1:統(tǒng)計信息存儲在數(shù)據(jù)字典,供優(yōu)化器用于確定執(zhí)行計劃
表和列統(tǒng)計信息
表統(tǒng)計信息包括表中的行數(shù),表使用的數(shù)據(jù)塊數(shù),以及表中的平均行長等。優(yōu)化器使用這些信息,并結(jié)合其它統(tǒng)計信息,計算執(zhí)行計劃中各種操作的成本,并評估相關(guān)操作所產(chǎn)生的行數(shù)。例如,表的訪問成本是用數(shù)據(jù)塊數(shù),結(jié)合參數(shù)DB_FILE_MULTIBLOCK_READ_COUNT的值來計算的。可以在數(shù)據(jù)字典視圖USER_TAB_STATISTICS中查看表的統(tǒng)計信息。
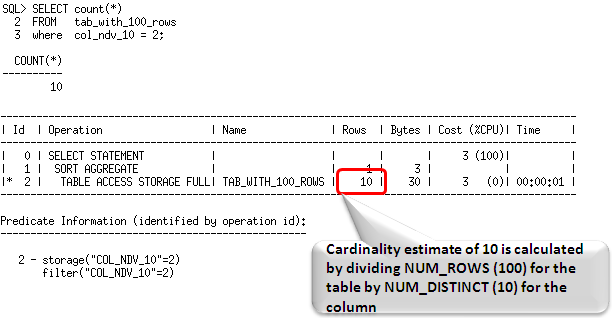
列統(tǒng)計信息包括一個列上的唯一值數(shù)據(jù)(NDV),以及在該列上找到的最小和最大值。可以在數(shù)據(jù)字典視圖USER_TAB_COL_STATISTICS中查看列的統(tǒng)計信息。優(yōu)化器使用列統(tǒng)計信息,并結(jié)合表統(tǒng)計信息(行數(shù))來評估SQL操作將會返回的行數(shù)。例如,如果一個表有100行記錄,并且對一個具有10個不同值的列上的相等謂詞來訪問表,那么優(yōu)化器在假設(shè)數(shù)據(jù)分布一致的情況下,將基數(shù)估計為表中的行數(shù)除以該列不同值的數(shù)量,即,100/10=10。
下一篇《謊言,該死的謊言與統(tǒng)計信息(二)》請點擊這里
原文鏈接:https://blogs.oracle.com/optimizer/post/lies-damned-lies-and-statistics
原文內(nèi)容:
Nigel Bayliss | November 8, 2011
Product Manager
Understanding and managing Optimizer statistics is key to optimal SQL execution. Knowing when and how to gather statistics in a timely manner is critical to maintaining acceptable performance. In order to clarify all of the information surrounding statistics we have put together two whitepapers on optimizer statistics. They are:
Best Practices for Gathering Optimizer Statistics with Oracle Database 12c Release 2
Understanding Optimizer Statistics With Oracle Database 12c Release 2
Introduction
When the Oracle database was first introduced the decision of how to execute a SQL statement was determined by a Rule Based Optimizer (RBO). The Rule Based Optimizer, as the name implies, followed a set of rules to determine the execution plan for a SQL statement. The rules were ranked so if there were two possible rules that could be applied to a SQL statement the rule with the lowest rank would be used.
In Oracle Database 7, the Cost Based Optimizer (CBO) was introduced to deal with the enhanced functionality being added to the Oracle Database at this time, including parallel execution and partitioning, and to take the actual data content and distribution into account. The Cost Based Optimizer examines all of the possible plans for a SQL statement and picks the one with the lowest cost, where cost represents the estimated resource usage for a given plan. The lower the cost the more efficient an execution plan is expected to be. In order for the Cost Based Optimizer to accurately determine the cost for an execution plan it must have information about all of the objects (tables and indexes) accessed in the SQL statement, and information about the system on which the SQL statement will be run.
This necessary information is commonly referred to as optimizer statistics. Understanding and managing Optimizer statistics is key to optimal SQL execution. Knowing when and how to gather statistics in a timely manner is critical to maintaining acceptable performance. This whitepaper is the first in a two part series on Optimizer statistics, and describes in detail, with worked examples, the different concepts of Optimizer statistics including;
What are Optimizer statistics
Gathering statistics
Managing statistics
Additional types of statistics
What are Optimizer Statistics?
Optimizer statistics are a collection of data that describe the database, and the objects in the database. These statistics are used by
the optimizer to choose the best execution plan for each SQL statement. Statistics are stored in the data dictionary, and can be accessed using data dictionary views such as USER_TAB_STATISTICS.
Figure 1:Optimizer statistics stored in the data dictionary used by the Oracle Optimizer to determine execution plans
Table and Column Statistics
Table statistics include information on the number of rows in the table, the number of data blocks used for the table, as well as the average row length in the table. The optimizer uses this information, in conjunction with other statistics, to compute the cost of various operations in an execution plan, and to estimate the number of rows the operation will produce. For example, the cost of a table access is calculated using the number of data blocks combined with the value of the parameter DB_FILE_MULTIBLOCK_READ_COUNT. You can view table
statistics in the dictionary view USER_TAB_STATISTICS.
Column statistics include information on the number of distinct values in a column (NDV) as well as the minimum and maximum value found in the column. You can view column statistics in the dictionary view USER_TAB_COL_STATISTICS. The optimizer uses the column statistics information in conjunction with the table statistics (number of rows) to estimate the number of rows that will be returned by a SQL operation. For example, if a table has 100 records, and the table access evaluates an equality predicate on a column that has 10 distinct values, then the optimizer, assuming uniform data distribution, estimates the cardinality to be the number of rows in the table divided by the number of distinct values for the column or 100/10 = 10.
