




近日在一客戶那碰到了一個性能問題,關于行鏈接和行遷移導致的全表掃描性能差勁,后來詳細查看了一些資料,特此做個筆記。
一、行鏈接
如果在首次insert數據的時候,這行數據,它的長度超過了這個塊的大小,那么,1、oracle會將該整行重新放到一個新的塊里面,然后在原來的位置留下一個指向已遷移行的指針。
2、如果該行的數據列超過了255列,那么超過255列的其他的列會被存放在其他的塊或者不屬于該片rowid的片。
3、表壓縮或者表空間壓縮也會導致出現行鏈接

如上圖所示,數據插入左邊的一個塊中,太大了放不下,所以將它放到了另外一個塊里面,而在原塊的部分留下了鏈接指針可以指向新塊
二、行遷移
在發生update的時候,該行數據被增大,超出了該塊剩余的ptcfree,那么它會將整行遷移到新的塊上(前提是該行能夠被新塊存下),被遷移的原本的段上會保留指向新塊的指針,這個時候數據的rowid是不會發生改變的。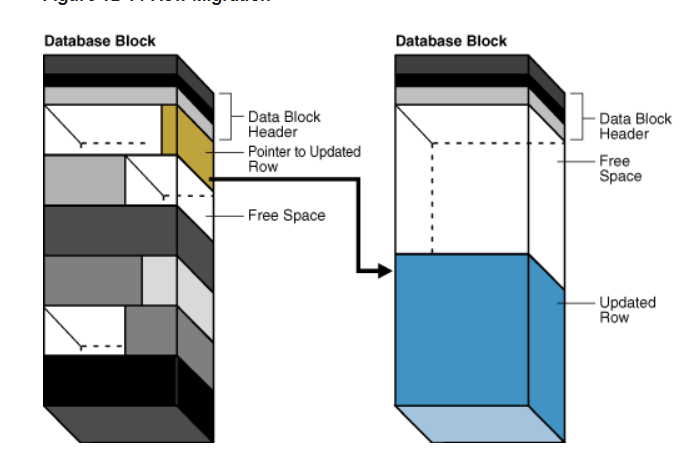
如上圖所示,更新的行對于當前塊中空閑的空間來說太大了,放不下這行數據了,所以將這行數據放到了新的塊中,而原行的位置放了一個指針指向新塊,這個時候rowid是不會發生改變的。
上面是一些概念性的知識
總的來說,當一行被鏈接或遷移時,檢索數據所需的I/O會增加。這種情況是因為Oracle數據庫必須掃描多個塊才能檢索行的信息。例如,如果數據庫執行一次I/O來讀取索引,執行一次I/O來讀取未遷移的表行,則需要額外的I/O來獲取遷移行的數據。
這個時候就會發現,原本很應該很快執行結束的SQL,在過了一段時間以后執行計劃未改變,系統負載不高的時候執行的異常緩慢,這個時候我們就需要檢查一下是不是因為行鏈接或者行遷移的問題而導致的SQL性能不佳。
檢查方法如下:
使用analyze來進行檢測,常用的DBMS_STATS這個是檢測不出來的(可能是我對這個包認識不足)
首先我們要去執行rdbms/admin下的utlchain.sql
然后執行
ANALYZE TABLE <USER_NAME>.<TABLE_NAME> LIST CHAINED ROWS;
這個時候該表發生的遷移數據就會存放在了CHAINED_ROWS,我們可以查看。
select * from CHAINED_ROWS;
也可以查看v$sysstat
SELECT name, value FROM v$sysstat WHERE name = 'table fetch continued row';
如果想只看當前session的,也可以
select b.name,a.* from v$mystat a,v$statname b where a.statistic#=b.statistic# and b.name like 'table fetch%';
雖然行遷移和行鏈接是兩個不同的問題,但是oracle內部將這倆問題看作是同一個事請。當我們檢測行遷移或者行鏈接的時候需要認真的檢查。
在大多數情況下,鏈接是不可避免的,尤其是當這涉及到具有大型列(如long,lob)的表。在不同的表中有很多鏈接行,并且這些表的平均行長度為不那么大,那么你可以考慮用更大的塊大小重建數據庫。
比如:你有一個2K塊大小的數據庫。不同的表有多個平均行長超過2K的大型varchar列。這意味著您將有很多鏈接行,因為您的塊大小是太小了。用更大的塊大小重建數據庫可以給你帶來更顯著的性能優勢。
遷移是因為PCTFREE設置得太低,塊中沒有足夠的空間進行更新。避免在遷移過程中,所有更新的表都應該設置其PCTFREE,以便塊內有足夠的空間更新。需要增加PCTFREE以避免行遷移。
說一千道一萬來點實際的:
1、如果你想暴力解決,直接可以alter table XXXX move
2、溫柔的辦法解決,先找出來發生的行遷移數據然后將其提取出來,從原表刪除以后將數據重新插入進去。
先刪除定義的表,防止以前有人做過。(chained_rows表是analyze的時候生成的存放行遷移的數據的,migrated_rows表是chained_rows表與被analyze的表利用rowid關聯后提取出來的行遷移的數據存放的表)
set echo off
DROP TABLE migrated_rows;
DROP TABLE chained_rows;
執行下面腳本找出來遷移行
@$ORACLE_HOME/rdbms/admin/utlchain.sql
set echo on
spool fix_mig
-- List the chained and migrated rows
ANALYZE TABLE &table_name LIST CHAINED ROWS;
-- Copy the chained/migrated rows to another table
create table migrated_rows as
SELECT orig.*
FROM &table_name orig, chained_rows cr
WHERE orig.rowid = cr.head_rowid
AND cr.table_name = upper('&table_name');
-- Delete the chained/migrated rows from the original table
DELETE FROM &table_name WHERE rowid IN (SELECT head_rowid FROM chained_rows);
-- Copy the chained/migrated rows back into the original table
INSERT INTO &table_name SELECT * FROM migrated_rows;
spool off
以上就是關于行遷移與行鏈接的產生原因以及解決方案。
