




原文鏈接:https://postgrespro.com/blog/pgsql/5969262
原文作者:Egor Rogov
你好! 我將開(kāi)始另一個(gè)關(guān)于PostgreSQL內(nèi)部的系列文章。 本文將重點(diǎn)討論查詢計(jì)劃和執(zhí)行機(jī)制。
這個(gè)專題包含以下內(nèi)容:
- 查詢執(zhí)行階段(本文)
- 統(tǒng)計(jì)信息
- 順序掃描
- 索引掃描
- 嵌套連接
- 哈希連接
- 排序連接
簡(jiǎn)單查詢協(xié)議
PostgreSQL的CS架構(gòu)的基本目的有兩個(gè):
- 客戶端發(fā)送sql查詢到服務(wù)端,并且響應(yīng)接收整個(gè)執(zhí)行結(jié)果。
- 服務(wù)端接收到的查詢需要經(jīng)過(guò)幾個(gè)階段。
解析
首先,查詢文本會(huì)被解析,以便服務(wù)器準(zhǔn)確的理解需要做什么。
語(yǔ)法分析器和解析器
語(yǔ)法分析器負(fù)責(zé)識(shí)別查詢語(yǔ)句中的詞位,比如SQL關(guān)鍵字、字符串和數(shù)值等。解析器負(fù)責(zé)由語(yǔ)法分析器分出來(lái)的詞位組成的結(jié)果在語(yǔ)法上是有效的。語(yǔ)法分析器和解析器使用標(biāo)準(zhǔn)的工具Bison和Flex來(lái)執(zhí)行。
示例:
SELECT schemaname, tablename
FROM pg_tables
WHERE tableowner = 'postgres'
ORDER BY tablename;
在這個(gè)步驟,會(huì)在內(nèi)存中生成一個(gè)解析樹。如下圖是簡(jiǎn)化版的結(jié)構(gòu),樹的不同節(jié)點(diǎn)會(huì)標(biāo)記為查詢的不同部分。
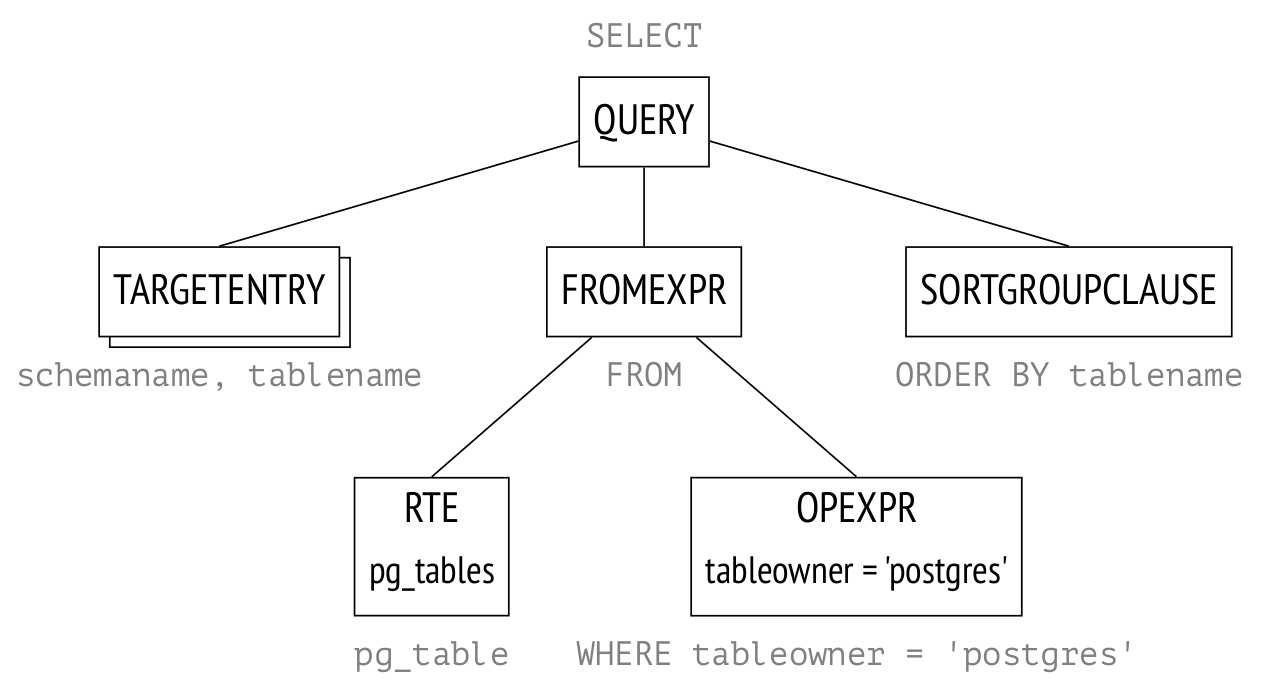
RTE是一個(gè)模糊的縮寫,表示“范圍表項(xiàng)”。在PostgreSQL源代碼中的名稱“范圍表”指的是表、子查詢、連接結(jié)果——換句話說(shuō),就是SQL語(yǔ)句操作的任何記錄集。
語(yǔ)義分析
語(yǔ)義分析器確認(rèn)查詢語(yǔ)句所涉及的表和其他對(duì)象在數(shù)據(jù)庫(kù)中是否存在和是否有權(quán)限去訪問(wèn)。語(yǔ)義分析器所需要的所有信息都存在系統(tǒng)目錄中。
語(yǔ)義分析器接收來(lái)自解析器生成的解析樹,并補(bǔ)充對(duì)特定數(shù)據(jù)庫(kù)對(duì)象、數(shù)據(jù)類型信息等的引用。
如果參數(shù)debug_print_parse設(shè)置為ON,完整的解析樹會(huì)在服務(wù)器的消息日志里,盡管這樣沒(méi)什么實(shí)際意義。
查詢重寫
接下來(lái),查詢可以被轉(zhuǎn)換(重寫)了。
查詢重寫有多個(gè)目的。其中一個(gè)是查詢中出現(xiàn)的視圖的查詢替換解析樹中的視圖為子樹。
示例中的pg_tables表是一個(gè)視圖,在經(jīng)過(guò)查詢重寫之后解析樹是如下形式:
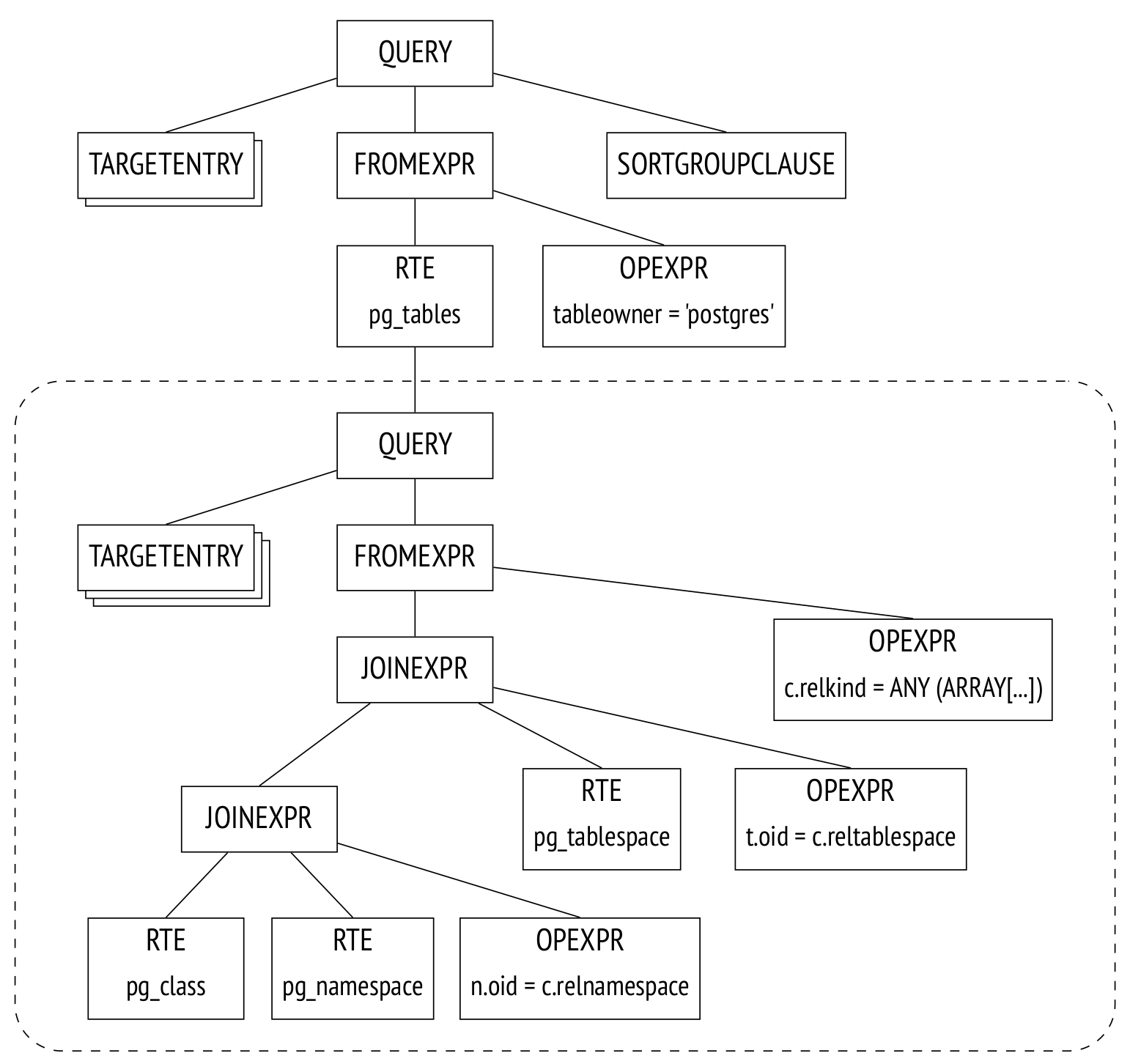
這個(gè)解析樹相當(dāng)于如下的查詢(盡管所有的操作都在樹上,而不是查詢文本):
SELECT schemaname, tablename
FROM (
-- pg_tables
SELECT n.nspname AS schemaname,
c.relname AS tablename,
pg_get_userbyid(c.relowner) AS tableowner,
...
FROM pg_class c
LEFT JOIN pg_namespace n ON n.oid = c.relnamespace
LEFT JOIN pg_tablespace t ON t.oid = c.reltablespace
WHERE c.relkind = ANY (ARRAY['r'::char, 'p'::char])
)
WHERE tableowner = 'postgres'
ORDER BY tablename;
解析樹反映了查詢的語(yǔ)法結(jié)構(gòu),但不代表執(zhí)行的順序。
行級(jí)別的安全在轉(zhuǎn)換階段實(shí)施。
查詢轉(zhuǎn)換的另一個(gè)例子是版本14中用于遞歸查詢的SEARCH和CYCLE子句的實(shí)現(xiàn)。
PostgreSQL支持自定義轉(zhuǎn)換,用戶可以使用重寫系統(tǒng)規(guī)則來(lái)實(shí)現(xiàn)。
該規(guī)則系統(tǒng)是Postgres的主要特征之一 這些規(guī)則得到了項(xiàng)目基礎(chǔ)的支持,并在早期開(kāi)發(fā)期間被反復(fù)重新設(shè)計(jì)。 這是一個(gè)功能強(qiáng)大的機(jī)制,但是難于理解和調(diào)試。 甚至有人提議將這些規(guī)則從PostgreSQL中完全刪除,但是沒(méi)有得到普遍的支持。 在大多數(shù)情況下,使用觸發(fā)器比使用規(guī)則更安全、更方便。
如果參數(shù)debug_print_rewrite是打開(kāi)的,則轉(zhuǎn)換后的完整解析樹將顯示在服務(wù)器消息日志中。
確定執(zhí)行計(jì)劃
SQL是一種聲明性語(yǔ)言:查詢指定檢索什么,而不是如何檢索。
任何查詢都可以以多種方式執(zhí)行。 解析樹中的每個(gè)操作都有多個(gè)執(zhí)行選項(xiàng)。 例如,您可以通過(guò)讀取整個(gè)表并丟棄不需要的行來(lái)從表中檢索特定的記錄,或者您可以使用索引來(lái)查找與查詢匹配的行。 數(shù)據(jù)集總是成對(duì)連接的。 連接順序的變化會(huì)導(dǎo)致許多執(zhí)行選項(xiàng)。 然后有各種方法將兩組行連接在一起。 例如,您可以逐個(gè)檢查第一個(gè)集合中的行,并在另一個(gè)集合中查找匹配的行,或者您可以先對(duì)兩個(gè)集合排序,然后將它們合并在一起。 不同的方法在某些情況下性能更好,而在另一些情況下性能更差。
最優(yōu)方案的執(zhí)行速度可能比非最優(yōu)方案快幾個(gè)數(shù)量級(jí)。 這就是為什么優(yōu)化已解析查詢的計(jì)劃器是系統(tǒng)中最復(fù)雜的元素之一。
計(jì)劃樹
執(zhí)行計(jì)劃也可以表示為樹,但其節(jié)點(diǎn)是數(shù)據(jù)上的物理操作,而不是邏輯操作。
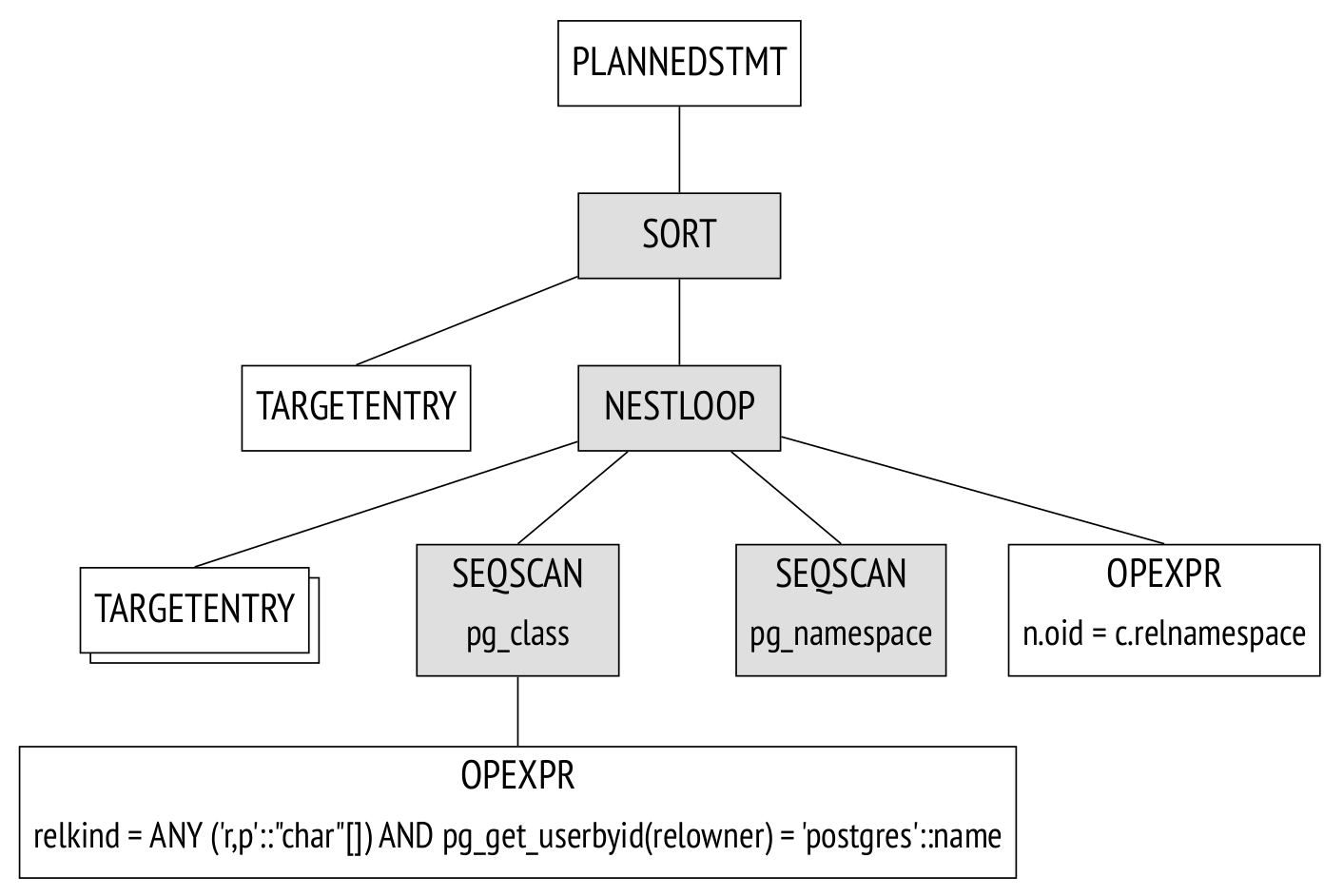
如果參數(shù)debug_print_plan是打開(kāi)的,則完整的計(jì)劃樹將顯示在服務(wù)器消息日志中。 通過(guò)這種方式查看是非常不實(shí)際的,因?yàn)槿罩痉浅;靵y。 一個(gè)更方便的選擇是使用EXPLAIN命令:
EXPLAIN
SELECT schemaname, tablename
FROM pg_tables
WHERE tableowner = 'postgres'
ORDER BY tablename;
QUERY PLAN
?????????????????????????????????????????????????????????????????????
Sort (cost=21.03..21.04 rows=1 width=128)
Sort Key: c.relname
?> Nested Loop Left Join (cost=0.00..21.02 rows=1 width=128)
Join Filter: (n.oid = c.relnamespace)
?> Seq Scan on pg_class c (cost=0.00..19.93 rows=1 width=72)
Filter: ((relkind = ANY ('{r,p}'::"char"[])) AND (pg_g...
?> Seq Scan on pg_namespace n (cost=0.00..1.04 rows=4 wid...
(7 rows)
圖中顯示了樹的主要節(jié)點(diǎn)。 在EXPLAIN輸出中,同樣的節(jié)點(diǎn)用箭頭標(biāo)記。
Seq Scan節(jié)點(diǎn)表示表讀取操作,而Nested Loop節(jié)點(diǎn)表示連接操作。 這里有兩點(diǎn)值得注意:
- 其中一個(gè)初始表從計(jì)劃樹中刪除了,因?yàn)橐?guī)劃器發(fā)現(xiàn)它不需要處理查詢,因此刪除了它。
- 每個(gè)節(jié)點(diǎn)旁邊都有一個(gè)估計(jì)的要處理的行數(shù)和處理的成本。
搜索計(jì)劃
為了找到最優(yōu)的計(jì)劃,PostgreSQL使用了基于成本的查詢優(yōu)化器。 優(yōu)化器執(zhí)行各種可用的執(zhí)行計(jì)劃,并估計(jì)所需的資源數(shù)量,如I/O操作和CPU周期。 這個(gè)計(jì)算出來(lái)的估計(jì),轉(zhuǎn)換成任意的單位,被稱為計(jì)劃成本。 選擇結(jié)果成本最低的計(jì)劃執(zhí)行。
問(wèn)題是,隨著連接數(shù)量的增加,可能計(jì)劃的數(shù)量呈指數(shù)級(jí)增長(zhǎng),即使是相對(duì)簡(jiǎn)單的查詢,也不可能逐個(gè)篩選所有計(jì)劃。 因此,使用動(dòng)態(tài)規(guī)劃和啟發(fā)式算法來(lái)限制搜索范圍。 這允許在合理的時(shí)間內(nèi)精確地解決查詢中更多表的問(wèn)題,但所選擇的計(jì)劃不能保證是真正最優(yōu)的,因?yàn)橐?guī)劃器使用簡(jiǎn)化的數(shù)學(xué)模型,可能使用不精確的初始數(shù)據(jù)。
順序連接
查詢可以以特定的方式進(jìn)行結(jié)構(gòu)化,以顯著減少搜索范圍(冒著失去找到最佳計(jì)劃的機(jī)會(huì)的風(fēng)險(xiǎn)):
- 通用表達(dá)式通常與主查詢分開(kāi)優(yōu)化。 從版本12開(kāi)始,這可以通過(guò)MATERIALIZE子句強(qiáng)制實(shí)現(xiàn)。
- 非sql函數(shù)的查詢與主查詢是分開(kāi)優(yōu)化的。 (SQL函數(shù)在某些情況下可以內(nèi)聯(lián)到主查詢中。)
- join_collapse_limit參數(shù)與顯式JOIN子句一起使用,以及from_collapse_limit參數(shù)與子查詢一起使用,可以定義某些連接的順序,具體取決于查詢語(yǔ)法。
最后還需要說(shuō)一下的事,對(duì)于下面這種沒(méi)有顯示連接的FROM中的表:
SELECT ...
FROM a, b, c, d, e
WHERE ...
這個(gè)查詢的解析樹是這樣的:
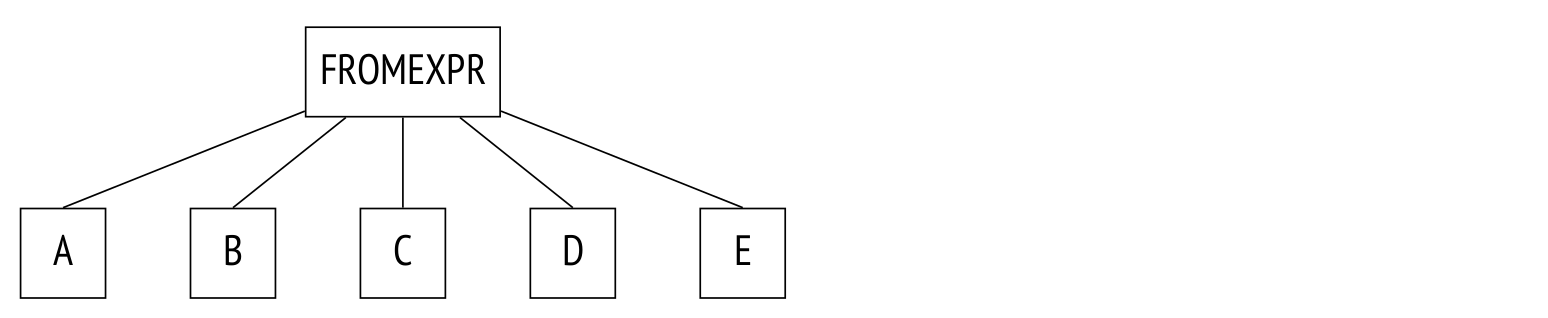
在這個(gè)查詢中,規(guī)劃器將考慮所有的連接順序。
在下一個(gè)示例中,一些連接是由JOIN子句顯式定義的:
SELECT ...
FROM a, b JOIN c ON ..., d, e
WHERE ...
解析樹反映了這一點(diǎn):
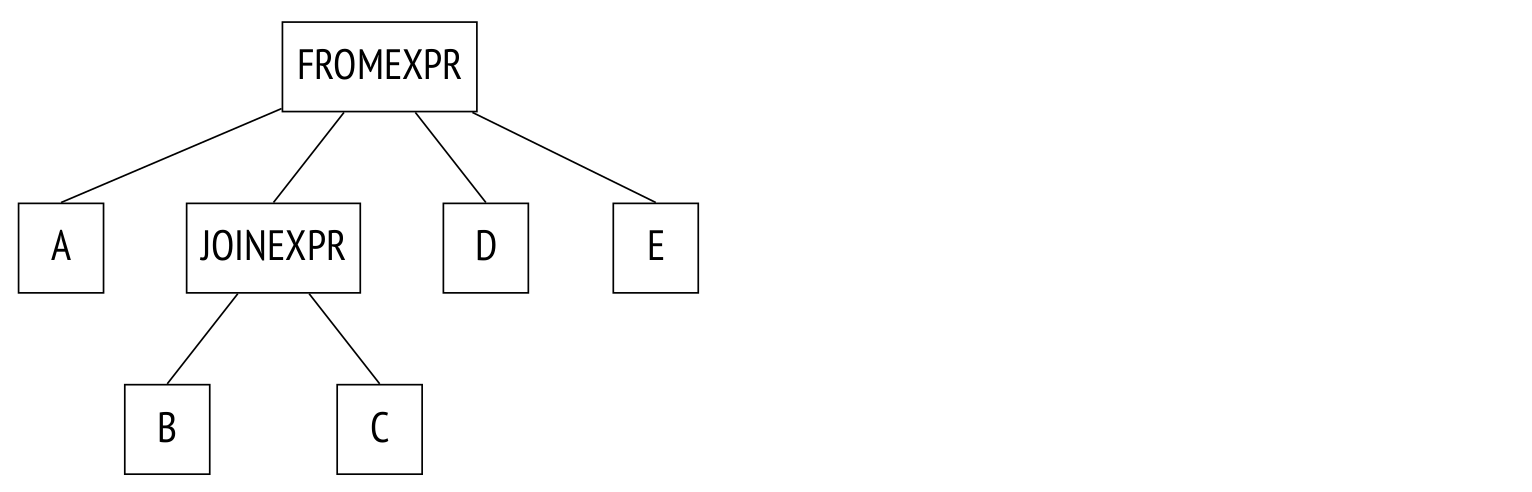
規(guī)劃器折疊連接樹,有效地將其轉(zhuǎn)換為前面示例中的樹。 該算法遞歸地遍歷樹,并用其組件的平面列表替換每個(gè)JOINEXPR節(jié)點(diǎn)。
但是,只有當(dāng)生成的扁平列表包含的元素不超過(guò)join_collapse_limit(默認(rèn)為8)時(shí),才會(huì)出現(xiàn)這種“扁平化”。 在上面的示例中,如果join_collapse_limit設(shè)置為5或更少,JOINEXPR節(jié)點(diǎn)將不會(huì)被折疊。 對(duì)計(jì)劃者來(lái)說(shuō),這意味著兩件事:
- 表B必須與表C連接(反之亦然,對(duì)中的連接順序不受限制)。
- 表A、D、E和B到C的連接可以以任何順序連接。
如果join_collapse_limit設(shè)置為1,則將保留任何顯式的JOIN順序。
注意,無(wú)論join_collapse_limit如何,F(xiàn)ULL OUTER JOIN操作永遠(yuǎn)不會(huì)折疊。
參數(shù)from_collapse_limit(默認(rèn)也是8)以類似的方式限制子查詢的扁平化。 子查詢與連接似乎沒(méi)有太多的共同點(diǎn),但當(dāng)涉及到解析樹級(jí)別時(shí),相似性就很明顯了。
示例如下:
SELECT ...
FROM a, b JOIN c ON ..., d, e
WHERE ...
這是樹:
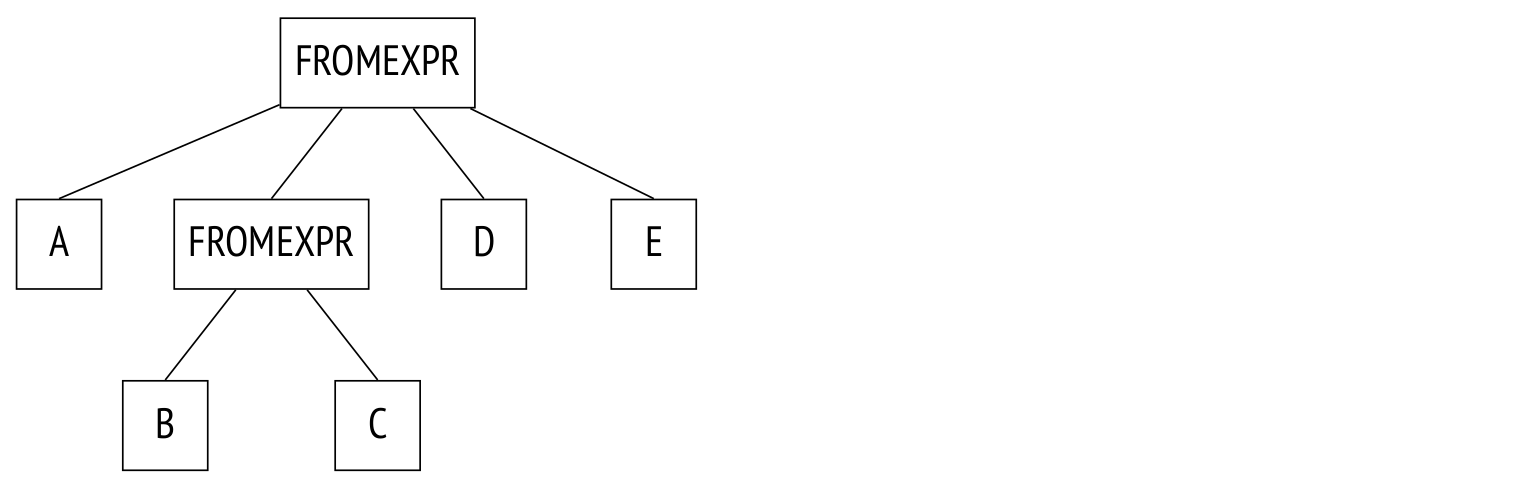
這里唯一的區(qū)別是,JOINEXPR節(jié)點(diǎn)被FROMEXPR替換(因此參數(shù)名稱為FROM)。
遺傳搜索
當(dāng)扁平化的樹最終擁有太多的同級(jí)節(jié)點(diǎn)(表或連接結(jié)果)時(shí),規(guī)劃時(shí)間可能會(huì)飆升,因?yàn)槊總€(gè)節(jié)點(diǎn)都需要單獨(dú)的優(yōu)化。 如果參數(shù)geqo是開(kāi)啟的(默認(rèn)為開(kāi)啟),當(dāng)同級(jí)節(jié)點(diǎn)數(shù)達(dá)到geqo_threshold(默認(rèn)為12)時(shí),PostgreSQL將切換到遺傳搜索。
遺傳搜索比動(dòng)態(tài)規(guī)劃方法快得多,但它不能保證找到最佳的可能計(jì)劃。 這個(gè)算法有許多可調(diào)整的選項(xiàng),但這是另一篇文章的主題。
選擇最好的計(jì)劃
最佳計(jì)劃的定義因預(yù)期用途而異。 當(dāng)需要一個(gè)完整的輸出時(shí)(例如,生成一個(gè)報(bào)告),計(jì)劃必須優(yōu)化匹配查詢的所有行的檢索。 另一方面,如果您只想要前幾個(gè)匹配的行(例如顯示在屏幕上),那么最佳計(jì)劃可能完全不同。
PostgreSQL通過(guò)計(jì)算兩個(gè)成本組件來(lái)解決這個(gè)問(wèn)題。 在執(zhí)行計(jì)劃的輸出中,它們會(huì)顯示在“cost”后面:
Sort (cost=21.03..21.04 rows=1 width=128)
第一個(gè)組成部分,啟動(dòng)成本,是為節(jié)點(diǎn)執(zhí)行做準(zhǔn)備的成本; 第二個(gè)部分,總成本,表示節(jié)點(diǎn)執(zhí)行的總成本。
在選擇計(jì)劃時(shí),規(guī)劃器首先檢查游標(biāo)是否正在使用(可以使用DECLARE命令設(shè)置游標(biāo),也可以在PL/pgSQL中顯式聲明游標(biāo))。 如果不是,規(guī)劃器假設(shè)需要全部輸出,并選擇總成本最小的計(jì)劃。
否則,如果使用游標(biāo),規(guī)劃器將選擇一個(gè)最優(yōu)檢索行數(shù)等于匹配行的總數(shù)cursor_tuple_fraction(默認(rèn)為0.1)的計(jì)劃。 或者,更具體地說(shuō),一個(gè)cost最低的計(jì)劃
啟動(dòng)成本+ cursor_tuple_fraction ×(總成本?啟動(dòng)成本
成本核算過(guò)程
為了估計(jì)一個(gè)計(jì)劃成本,它的每個(gè)節(jié)點(diǎn)都必須單獨(dú)估計(jì)。 節(jié)點(diǎn)成本取決于節(jié)點(diǎn)類型(從表中讀取數(shù)據(jù)的成本遠(yuǎn)低于對(duì)表進(jìn)行排序的成本)和處理的數(shù)據(jù)量(通常,數(shù)據(jù)越多,成本越高)。 雖然節(jié)點(diǎn)類型馬上就知道了,但要評(píng)估數(shù)據(jù)量,我們首先需要估計(jì)節(jié)點(diǎn)的基數(shù)(輸入行數(shù))和選擇性(剩余用于輸出的行數(shù))。 為此,我們需要數(shù)據(jù)統(tǒng)計(jì):表大小、跨列的數(shù)據(jù)分布。
因此,優(yōu)化依賴于準(zhǔn)確的統(tǒng)計(jì)數(shù)據(jù),這些數(shù)據(jù)由自動(dòng)分析過(guò)程收集并保持最新。
如果準(zhǔn)確估計(jì)了每個(gè)計(jì)劃節(jié)點(diǎn)的基數(shù),則計(jì)算出的總成本通常與實(shí)際成本相匹配。 常見(jiàn)的規(guī)劃器偏差通常是基數(shù)和選擇性估計(jì)錯(cuò)誤的結(jié)果。 這些錯(cuò)誤是由不準(zhǔn)確的、過(guò)時(shí)的或不可用的統(tǒng)計(jì)數(shù)據(jù),以及(在較小程度上)計(jì)劃者所基于的內(nèi)在不完善的模型造成的。
基數(shù)評(píng)估
基數(shù)評(píng)估遞歸執(zhí)行。 節(jié)點(diǎn)基數(shù)使用兩個(gè)值計(jì)算:
- 節(jié)點(diǎn)子節(jié)點(diǎn)的基數(shù),或輸入行數(shù)。
- 節(jié)點(diǎn)的選擇性,或輸出行與輸入行的比例。
基數(shù)是這兩個(gè)值的乘積。
選擇性是0到1之間的數(shù)字。 接近0的選擇性值稱為高選擇性,接近1的值稱為低選擇性。 這是因?yàn)楦哌x擇性會(huì)消除較高比例的行,而低選擇性值會(huì)降低閾值,因此會(huì)丟棄更少的行。
首先處理具有數(shù)據(jù)訪問(wèn)方法的葉節(jié)點(diǎn)。 這就是表大小等統(tǒng)計(jì)信息發(fā)揮作用的地方。
應(yīng)用于表的條件的選擇性取決于條件類型。 在其最簡(jiǎn)單的形式中,選擇性可以是一個(gè)恒定的值,但是規(guī)劃器試圖使用所有可用的信息來(lái)產(chǎn)生最準(zhǔn)確的估計(jì)。 以最簡(jiǎn)單條件的選擇性估計(jì)為基礎(chǔ),用布爾運(yùn)算構(gòu)建的復(fù)雜條件可以通過(guò)以下簡(jiǎn)單的公式進(jìn)一步計(jì)算:
selx and y = selx sely selx or y = 1?(1?selx)(1?sely) = selx + sely ? selx sely.
在這些公式中,x和y被認(rèn)為是獨(dú)立的。 如果它們相互關(guān)聯(lián),公式仍在使用,但估計(jì)將不那么準(zhǔn)確。
對(duì)于連接的基數(shù)估計(jì),計(jì)算兩個(gè)值:笛卡爾乘積的基數(shù)(兩個(gè)數(shù)據(jù)集的基數(shù)的乘積)和連接條件的選擇性,后者又取決于條件類型。
其他節(jié)點(diǎn)類型(如排序或聚合節(jié)點(diǎn))的基數(shù)也是類似計(jì)算的。
請(qǐng)注意,在較低節(jié)點(diǎn)中的基數(shù)計(jì)算錯(cuò)誤將向上傳播,導(dǎo)致不準(zhǔn)確的成本估計(jì),最終導(dǎo)致次優(yōu)計(jì)劃。 更糟糕的是,規(guī)劃器只有表上的統(tǒng)計(jì)數(shù)據(jù),而沒(méi)有連接結(jié)果上的統(tǒng)計(jì)數(shù)據(jù)。
成本評(píng)估
成本估算過(guò)程也是遞歸的。 子樹的開(kāi)銷由子節(jié)點(diǎn)的開(kāi)銷加上父節(jié)點(diǎn)的開(kāi)銷組成。
節(jié)點(diǎn)成本計(jì)算是基于它所執(zhí)行操作的數(shù)學(xué)模型,已經(jīng)評(píng)估的基數(shù)作為輸入,該過(guò)程計(jì)算啟動(dòng)成本和總成本。
有些操作不需要任何準(zhǔn)備,可以立即開(kāi)始執(zhí)行。 對(duì)于這些操作,啟動(dòng)成本為零。
其他操作可能有前提條件。 例如,排序節(jié)點(diǎn)通常需要其子節(jié)點(diǎn)的所有數(shù)據(jù)才能開(kāi)始操作。 這些節(jié)點(diǎn)的啟動(dòng)成本是非零的。 必須支付此成本,即使下一個(gè)節(jié)點(diǎn)(或客戶機(jī))只需要輸出一行。
成本是策劃者的最佳評(píng)估,任何計(jì)劃上的錯(cuò)誤都會(huì)影響成本與實(shí)際執(zhí)行時(shí)間的相關(guān)性。 成本評(píng)估的主要目的是允許規(guī)劃者在相同的條件下比較相同查詢的不同執(zhí)行計(jì)劃。 在其他情況下,通過(guò)成本來(lái)比較查詢(更糟糕的是,不同的查詢)是毫無(wú)意義的,也是錯(cuò)誤的。 例如,考慮一個(gè)由于統(tǒng)計(jì)數(shù)據(jù)不準(zhǔn)確而被低估的成本。 更新統(tǒng)計(jì)數(shù)據(jù)——成本可能會(huì)改變,但估算會(huì)更準(zhǔn)確,計(jì)劃最終也會(huì)完善。
執(zhí)行
根據(jù)計(jì)劃執(zhí)行優(yōu)化的查詢。
在后端內(nèi)存中創(chuàng)建一個(gè)名為portal的對(duì)象。 portal在執(zhí)行查詢時(shí)存儲(chǔ)查詢的狀態(tài)。 這個(gè)狀態(tài)表示為樹,在結(jié)構(gòu)上與計(jì)劃樹相同。
樹的節(jié)點(diǎn)充當(dāng)裝配線,彼此請(qǐng)求和傳遞。

從根節(jié)點(diǎn)開(kāi)始執(zhí)行,根節(jié)點(diǎn)(示例中的排序節(jié)點(diǎn)SORT)從子節(jié)點(diǎn)請(qǐng)求數(shù)據(jù),當(dāng)它接收到所有請(qǐng)求的數(shù)據(jù)時(shí),它執(zhí)行排序操作,然后將數(shù)據(jù)向上傳遞給客戶端。
一些節(jié)點(diǎn)(如NESTLOOP節(jié)點(diǎn))連接來(lái)自不同來(lái)源的數(shù)據(jù),該節(jié)點(diǎn)從兩個(gè)子節(jié)點(diǎn)請(qǐng)求數(shù)據(jù)。 在接收到符合聯(lián)接條件的兩行后,節(jié)點(diǎn)立即將結(jié)果行傳遞給父節(jié)點(diǎn)(與排序不同,后者必須在處理之前接收所有行)。 然后,該節(jié)點(diǎn)停止,直到其父節(jié)點(diǎn)請(qǐng)求另一行。 因此,如果只需要部分結(jié)果(例如,由LIMIT設(shè)置),則不會(huì)完全執(zhí)行操作。
兩個(gè)SEQSCAN頁(yè)是表掃描。 根據(jù)父節(jié)點(diǎn)的請(qǐng)求,葉節(jié)點(diǎn)從表中讀取下一行并返回它。
這個(gè)節(jié)點(diǎn)和其他一些節(jié)點(diǎn)根本不存儲(chǔ)行,而是直接交付并立即忘記它們。 其他節(jié)點(diǎn),比如排序,可能需要一次存儲(chǔ)大量的數(shù)據(jù)。 為了處理這個(gè)問(wèn)題,在后端內(nèi)存中分配了一個(gè)work_mem內(nèi)存塊。 它的默認(rèn)大小是保守的4MB限制; 當(dāng)內(nèi)存耗盡時(shí),多余的數(shù)據(jù)被發(fā)送到磁盤上的臨時(shí)文件。
一個(gè)計(jì)劃可能包含有存儲(chǔ)需求的多個(gè)節(jié)點(diǎn),因此它可能分配幾個(gè)內(nèi)存塊,每個(gè)塊的大小為work_mem。 查詢進(jìn)程可能占用的總內(nèi)存大小沒(méi)有限制。
擴(kuò)展查詢協(xié)議
使用簡(jiǎn)單的查詢協(xié)議,任何命令,即使是一次又一次地重復(fù),也要經(jīng)歷上述所有階段:
- 解析
- 轉(zhuǎn)換
- 規(guī)劃
- 執(zhí)行
但是沒(méi)有理由一遍又一遍地解析同一個(gè)查詢。 如果查詢只是常量不同,也沒(méi)有理由重新解析它們:解析樹將是相同的。
簡(jiǎn)單查詢協(xié)議的另一個(gè)麻煩是,客戶端接收完整的輸出,不管輸出有多長(zhǎng)。
使用SQL命令可以解決這兩個(gè)問(wèn)題:對(duì)于第一個(gè)問(wèn)題準(zhǔn)備一個(gè)查詢并執(zhí)行它,對(duì)于第二個(gè)問(wèn)題聲明一個(gè)游標(biāo)并FETCH所需的行。 但是,客戶機(jī)將不得不處理新對(duì)象的命名,而服務(wù)器將需要解析額外的命令。
擴(kuò)展的查詢協(xié)議允許在協(xié)議命令級(jí)別對(duì)單獨(dú)的執(zhí)行階段進(jìn)行精確控制
準(zhǔn)備
在準(zhǔn)備期間,像往常一樣解析和轉(zhuǎn)換查詢,但解析樹存儲(chǔ)在后端內(nèi)存中。
PostgreSQL沒(méi)有一個(gè)全局緩存用于解析查詢。 即使一個(gè)進(jìn)程之前已經(jīng)解析過(guò)該查詢,其他進(jìn)程也必須再次解析它。 然而,這種設(shè)計(jì)也有好處。 在高負(fù)載下,全局內(nèi)存緩存很容易因?yàn)殒i而成為瓶頸。 一個(gè)客戶端發(fā)送多個(gè)小命令可能會(huì)影響整個(gè)實(shí)例的性能。 在PostgreSQL中,查詢解析很便宜,并且與其他進(jìn)程隔離開(kāi)來(lái)。
可以用附加參數(shù)準(zhǔn)備查詢,下面是一個(gè)使用SQL命令的示例(同樣,這與協(xié)議命令級(jí)別的準(zhǔn)備是不同的,但最終效果是相同的):
PREPARE plane(text) AS
SELECT * FROM aircrafts WHERE aircraft_code = $1;
本系列文章中的大多數(shù)示例將使用演示數(shù)據(jù)庫(kù)“Airlines”。
該視圖顯示所有已命名的預(yù)處理語(yǔ)句:
SELECT name, statement, parameter_types
FROM pg_prepared_statements \gx
?[ RECORD 1 ]???+??????????????????????????????????????????????????
name | plane
statement | PREPARE plane(text) AS +
| SELECT * FROM aircrafts WHERE aircraft_code = $1;
parameter_types | {text}
視圖沒(méi)有列出任何未命名的語(yǔ)句(使用擴(kuò)展協(xié)議或PL/pgSQL的語(yǔ)句)。 它也沒(méi)有列出來(lái)自其他會(huì)話的準(zhǔn)備語(yǔ)句:訪問(wèn)另一個(gè)會(huì)話的內(nèi)存是不可能的。
參數(shù)綁定
在執(zhí)行準(zhǔn)備好的查詢之前,將綁定當(dāng)前參數(shù)值。
EXECUTE plane('733');
aircraft_code | model | range
???????????????+???????????????+???????
733 | Boeing 737?300 | 4200
(1 row)
與字面值表達(dá)式的連接相比,預(yù)處理語(yǔ)句的一個(gè)優(yōu)點(diǎn)是防止任何類型的SQL注入,因?yàn)閰?shù)值不會(huì)影響已經(jīng)構(gòu)建的解析樹。 預(yù)處理的語(yǔ)句在沒(méi)有達(dá)到相同的安全級(jí)別的情況下將會(huì)對(duì)來(lái)自不可信來(lái)源的所有值進(jìn)行大量的溢出。
計(jì)劃和執(zhí)行
當(dāng)執(zhí)行準(zhǔn)備好的語(yǔ)句時(shí),首先使用提供的參數(shù)規(guī)劃查詢,然后將選擇的計(jì)劃發(fā)送執(zhí)行。
實(shí)際參數(shù)值對(duì)規(guī)劃器很重要,因?yàn)椴煌瑓?shù)集的最優(yōu)方案也可能不同。 例如,當(dāng)尋找高級(jí)航班預(yù)訂時(shí),使用索引掃描(index scan),因?yàn)橐?guī)劃器期望匹配的行不多:
CREATE INDEX ON bookings(total_amount);
EXPLAIN SELECT * FROM bookings WHERE total_amount > 1000000;
QUERY PLAN
?????????????????????????????????????????????????????????????????????
Bitmap Heap Scan on bookings (cost=86.38..9227.74 rows=4380 wid...
Recheck Cond: (total_amount > '1000000'::numeric)
?> Bitmap Index Scan on bookings_total_amount_idx (cost=0.00....
Index Cond: (total_amount > '1000000'::numeric)
(4 rows)
然而,下一個(gè)條件完全符合所有的預(yù)訂。 索引掃描在這里是沒(méi)用的,而是執(zhí)行順序掃描(Seq scan):
EXPLAIN SELECT * FROM bookings WHERE total_amount > 100;
QUERY PLAN
???????????????????????????????????????????????????????????????????
Seq Scan on bookings (cost=0.00..39835.88 rows=2111110 width=21)
Filter: (total_amount > '100'::numeric)
(2 rows)
在某些情況下,規(guī)劃器除了存儲(chǔ)解析樹之外還存儲(chǔ)查詢計(jì)劃,以避免在解析樹出現(xiàn)時(shí)再次進(jìn)行規(guī)劃。 這種沒(méi)有參數(shù)值的計(jì)劃被稱為通用計(jì)劃,與使用給定參數(shù)值生成的自定義計(jì)劃相反。 通用計(jì)劃的一個(gè)明顯的用例是沒(méi)有參數(shù)的語(yǔ)句。
對(duì)于前4次運(yùn)行,帶參數(shù)的預(yù)處理語(yǔ)句總是根據(jù)實(shí)際參數(shù)值進(jìn)行優(yōu)化。 然后計(jì)算平均計(jì)劃成本。 在第五次及以后的運(yùn)行中,如果通用計(jì)劃比定制計(jì)劃(每次都必須重新構(gòu)建)的平均成本更低,規(guī)劃器將從此存儲(chǔ)并使用通用計(jì)劃,然后再進(jìn)行進(jìn)一步的優(yōu)化。
plane預(yù)處理語(yǔ)句已經(jīng)執(zhí)行過(guò)一次了。 在接下來(lái)的兩次執(zhí)行中,仍然使用定制計(jì)劃,如查詢計(jì)劃中的參數(shù)值所示:
EXECUTE plane('763');
EXECUTE plane('773');
EXPLAIN EXECUTE plane('319');
QUERY PLAN
??????????????????????????????????????????????????????????????????
Seq Scan on aircrafts_data ml (cost=0.00..1.39 rows=1 width=52)
Filter: ((aircraft_code)::text = '319'::text)
(2 rows)
執(zhí)行四次之后,計(jì)劃者將切換到通用計(jì)劃。 在這種情況下,通用計(jì)劃與自定義計(jì)劃相同,具有相同的成本,因此是可取的。 現(xiàn)在EXPLAIN命令顯示了參數(shù)號(hào),而不是實(shí)際值:
EXECUTE plane('320');
EXPLAIN EXECUTE plane('321');
QUERY PLAN
??????????????????????????????????????????????????????????????????
Seq Scan on aircrafts_data ml (cost=0.00..1.39 rows=1 width=52)
Filter: ((aircraft_code)::text = '$1'::text)
(2 rows)
有個(gè)令人遺憾但是不是不可能發(fā)生的情況是,只有第四次執(zhí)行計(jì)劃比通過(guò)執(zhí)行計(jì)劃的成本更高,其他任何一次都是更低的,這時(shí)候,規(guī)劃器將會(huì)忽略其他所有的計(jì)劃。
另外一個(gè)問(wèn)題是規(guī)劃器比較評(píng)估成本,而不是真正需要花費(fèi)的成本。(并不是真實(shí)的,而是估算的)
這就是為什么在版本12及以上中,如果用戶不喜歡自動(dòng)結(jié)果,他們可以強(qiáng)制系統(tǒng)使用通用計(jì)劃或自定義計(jì)劃。 這是通過(guò)參數(shù)plan_cache_mode完成的:
SET plan_cache_mode = 'force_custom_plan';
EXPLAIN EXECUTE plane('CN1');
QUERY PLAN
??????????????????????????????????????????????????????????????????
Seq Scan on aircrafts_data ml (cost=0.00..1.39 rows=1 width=52)
Filter: ((aircraft_code)::text = 'CN1'::text)
(2 rows)
在14及以上版本中,pg_prepared_statements視圖也顯示計(jì)劃選擇統(tǒng)計(jì)信息:
SELECT name, generic_plans, custom_plans
FROM pg_prepared_statements;
name | generic_plans | custom_plans
???????+???????????????+??????????????
plane | 1 | 6
(1 row)
輸出檢索
擴(kuò)展查詢協(xié)議允許客戶端分批獲取輸出,一次獲取幾行,而不是一次獲取所有行。 使用SQL游標(biāo)也可以實(shí)現(xiàn)同樣的效果,但成本更高,規(guī)劃師將優(yōu)化cursor_tuple_fraction第一行的檢索:
BEGIN;
DECLARE cur CURSOR FOR
SELECT * FROM aircrafts ORDER BY aircraft_code;
FETCH 3 FROM cur;
aircraft_code | model | range
???????????????+??????????????????+???????
319 | Airbus A319?100 | 6700
320 | Airbus A320?200 | 5700
321 | Airbus A321?200 | 5600
(3 rows)
FETCH 2 FROM cur;
aircraft_code | model | range
???????????????+???????????????+???????
733 | Boeing 737?300 | 4200
763 | Boeing 767?300 | 7900
(2 rows)
COMMIT;
每當(dāng)查詢返回大量行,而客戶端需要它們時(shí),每次檢索的行數(shù)對(duì)整體數(shù)據(jù)傳輸速度來(lái)說(shuō)就變得至關(guān)重要。 單個(gè)批處理的行越多,在往返延遲上損失的時(shí)間就越少。 但是,隨著批大小的增加,效率方面的節(jié)省就會(huì)減少。 例如,批量大小從1切換到10將大大節(jié)省時(shí)間,但從10切換到100幾乎不會(huì)有任何不同。
請(qǐng)繼續(xù)關(guān)注下一篇文章,其中我們將討論成本優(yōu)化的基礎(chǔ):統(tǒng)計(jì)信息。
