




原文鏈接:Table size in YugabyteDB, PostgreSQL and Oracle ??????
原文作者:Franck Pachot
PostgreSQL 和 YugabyteDB 的協(xié)議和 SQL 處理是一樣的,但是存儲(chǔ)是不同的。今天,磁盤上的大小并不是最昂貴的資源,而且由于高可用性和性能的原因,在向外擴(kuò)展的分布式數(shù)據(jù)庫中也不是一個(gè)大問題。 但是,當(dāng)跨數(shù)據(jù)庫遷移時(shí),最好了解存儲(chǔ)大小。特別是在遺留數(shù)據(jù)庫(堆表、B-Tree 索引、8k 塊頁面)和分布式數(shù)據(jù)庫(文檔存儲(chǔ)、LSM 樹、SST 文件)之間。
我正在以最小的部署進(jìn)行ybdemo實(shí)驗(yàn):
git clone https://github.com/FranckPachot/ybdemo.git
cd ybdemo/docker/yb-lab
# create a minimal RF=1 deployement
sh gen-yb-docker-compose.sh minimal
# stop the demo containers
docker-compose kill yb-demo-{read,write,connect}
在單節(jié)點(diǎn)集群上查看大小更容易。 當(dāng)分布到更多的節(jié)點(diǎn)時(shí),總大小不會(huì)改變。 當(dāng)添加高可用性與復(fù)制因子RF=3總大小乘以3。 但這里我感興趣的是磁盤上的原始大小。
我連接到 tserver 節(jié)點(diǎn):
docker exec -it yb-tserver-0 bash
生成 csv
我將使用以下函數(shù)來生成數(shù)據(jù)。
gen_random_csv生成大小為 $1 到 $2 列的隨機(jī)字母數(shù)字到 $3 行中以加載到 $4 表中gen_table_ddl生成 CREATE TABLEgen_pg調(diào)用這些函數(shù)來創(chuàng)建表并使用COPY插入行。 PostgreSQL很簡(jiǎn)單,而YugabyteDB受益于所有這些特性,可以擴(kuò)展到分布式存儲(chǔ)。
gen_random_csv(){
cat /dev/urandom | tr -dc '[:alpha:]' | fold -w $1 |
awk '
NR%m==1{if(NR>1)print "";d=""}
{printf d $0 ; d=","}
' m=$2 |
head -$3 | nl -s ","
}
gen_table_ddl(){
echo -n "create table $4 ( id bigint primary key check (id<=$3)"
for i in $(seq 1 $2)
do
echo -n ", col$i varchar($1)"
done
echo ");"
}
gen_pg(){
echo "drop table if exists $4;"
gen_table_ddl $1 $2 $3 "$4"
echo "copy $4 from stdin with csv;"
gen_random_csv $1 $2 $3 "$4"
echo "\\."
}
YugabyteDB
加載 1000 行
作為第一個(gè)測(cè)試,我加載了1000行60列的VARCHAR(100),看看它是如何工作的:
time gen_pg 100 60 1000 franck_varchar |
ysqlsh -h $(hostname) -e -v ON_ERROR_STOP=ON
指標(biāo)包括以下franck_varchar表:
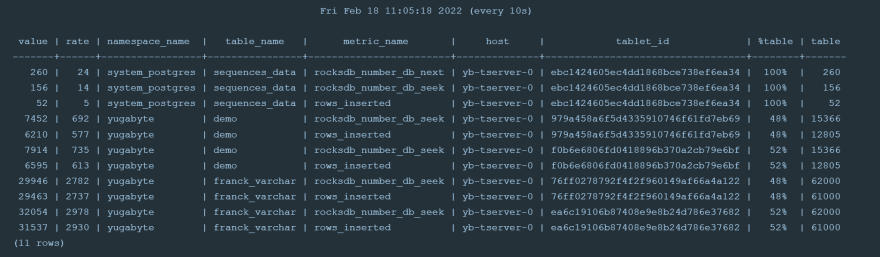
1000 行 60 列在 DocDB 中存儲(chǔ)為 61000 個(gè)子文檔:每行 1 個(gè),每列 1 個(gè)。這被分配到 2 個(gè)tablets中(我的默認(rèn)設(shè)置是每個(gè) tserver 2 個(gè)tablets)。每行都必須查找主鍵以檢查重復(fù)項(xiàng),這就是為什么 YSQL 接口比僅附加新版本的 YCQL 接口需要更長的加載時(shí)間。
如果你是YugabyteDB的新手,你可能會(huì)驚訝地發(fā)現(xiàn)這個(gè)表的大小為0:

默認(rèn)情況下,第一級(jí)存儲(chǔ)是128MB的MemTable。 我的1000行適合它,然后沒有任何內(nèi)容存儲(chǔ)到 SST 文件中。 當(dāng)然,這是受WAL保護(hù)的,我看到了加載的6MB數(shù)據(jù)。 在崩潰的情況下,可以從其中恢復(fù)MemTable。
現(xiàn)在讓我們插入更多數(shù)據(jù),以便將 MemTable 刷新到 SST 文件。
加載 600M
我生成這個(gè)來測(cè)量原始大小:
time gen_pg 100 60 100000 franck_varchar | wc -c | numfmt --to=si
結(jié)果:607M
我運(yùn)行它來創(chuàng)建和加載表:
time gen_pg 100 60 100000 franck_varchar |
ysqlsh -h $(hostname) -e -v ON_ERROR_STOP=ON
以下是來自http://tserver:9000/tables端點(diǎn)的存儲(chǔ)詳細(xì)信息。
文件系統(tǒng)中的數(shù)字顯示相同:

[root@yb-tserver-0 yugabyte]# du -h | grep 000030af00003000800000000000406a | sort -h
4.0K ./data/yb-data/tserver/data/rocksdb/table-000030af00003000800000000000406a/tablet-0d3e98af78354a43bcaef9fc2e37da17.snapshots
4.0K ./data/yb-data/tserver/data/rocksdb/table-000030af00003000800000000000406a/tablet-7bdf68bb1b324ff0baccfdb24e7d6ba0.snapshots
92K ./data/yb-data/tserver/data/rocksdb/table-000030af00003000800000000000406a/tablet-0d3e98af78354a43bcaef9fc2e37da17.intents
92K ./data/yb-data/tserver/data/rocksdb/table-000030af00003000800000000000406a/tablet-7bdf68bb1b324ff0baccfdb24e7d6ba0.intents
282M ./data/yb-data/tserver/data/rocksdb/table-000030af00003000800000000000406a/tablet-0d3e98af78354a43bcaef9fc2e37da17
283M ./data/yb-data/tserver/data/rocksdb/table-000030af00003000800000000000406a/tablet-7bdf68bb1b324ff0baccfdb24e7d6ba0
395M ./data/yb-data/tserver/wals/table-000030af00003000800000000000406a/tablet-0d3e98af78354a43bcaef9fc2e37da17
395M ./data/yb-data/tserver/wals/table-000030af00003000800000000000406a/tablet-7bdf68bb1b324ff0baccfdb24e7d6ba0
565M ./data/yb-data/tserver/data/rocksdb/table-000030af00003000800000000000406a
789M ./data/yb-data/tserver/wals/table-000030af00003000800000000000406a
不計(jì)算用于保護(hù)內(nèi)存結(jié)構(gòu)的臨時(shí)WALs,磁盤上的大小小于CSV大小。
加載 6.1 GB
現(xiàn)在加載一百萬行:
time gen_pg 100 60 1000000 franck_varchar |
ysqlsh -h $(hostname) -e -v ON_ERROR_STOP=ON
輸出顯示了DDL,我的筆記本電腦上的加載時(shí)間,以及生成和只計(jì)算大小的時(shí)間:
drop table if exists franck_varchar;
DROP TABLE
create table franck_varchar ( id bigint primary key check (id<=1000000), col1 text, col2 text, col3 text, col4 text, col5 text, col6 text, col7 text, col8 tex
t, col9 text, col10 text, col11 text, col12 text, col13 text, col14 text, col15 text, col16 text, col17 text, col18 text, col19 text, col20 text, col21 text,
col22 text, col23 text, col24 text, col25 text, col26 text, col27 text, col28 text, col29 text, col30 text, col31 text, col32 text, col33 text, col34 text, co
l35 text, col36 text, col37 text, col38 text, col39 text, col40 text, col41 text, col42 text, col43 text, col44 text, col45 text, col46 text, col47 text, col4
8 text, col49 text, col50 text, col51 text, col52 text, col53 text, col54 text, col55 text, col56 text, col57 text, col58 text, col59 text, col60 text);
CREATE TABLE
copy franck_varchar from stdin with csv;
COPY 1000000
real 19m0.471s
user 15m30.699s
sys 14m54.813s
[root@yb-tserver-0 yugabyte]# time gen_pg 100 60 1000000 franck_varchar | wc -c | numfmt --to=si
6.1G
real 7m18.488s
user 10m15.511s
sys 12m7.927s
我的表存儲(chǔ)在 6.4 GB 中:

我從文件系統(tǒng)中得到相同的圖片:
[root@yb-tserver-0 yugabyte]# du -h | grep 000030af000030008000000000004070 | sort -h
4.0K ./data/yb-data/tserver/data/rocksdb/table-000030af000030008000000000004070/tablet-9fea5fced0924eebb7a978be7cd83132.snapshots
4.0K ./data/yb-data/tserver/data/rocksdb/table-000030af000030008000000000004070/tablet-f6dffe42f77044deadd217ea3aeb7222.snapshots
92K ./data/yb-data/tserver/data/rocksdb/table-000030af000030008000000000004070/tablet-9fea5fced0924eebb7a978be7cd83132.intents
92K ./data/yb-data/tserver/data/rocksdb/table-000030af000030008000000000004070/tablet-f6dffe42f77044deadd217ea3aeb7222.intents
1.6G ./data/yb-data/tserver/wals/table-000030af000030008000000000004070/tablet-9fea5fced0924eebb7a978be7cd83132
1.6G ./data/yb-data/tserver/wals/table-000030af000030008000000000004070/tablet-f6dffe42f77044deadd217ea3aeb7222
3.2G ./data/yb-data/tserver/wals/table-000030af000030008000000000004070
3.3G ./data/yb-data/tserver/data/rocksdb/table-000030af000030008000000000004070/tablet-9fea5fced0924eebb7a978be7cd83132
3.3G ./data/yb-data/tserver/data/rocksdb/table-000030af000030008000000000004070/tablet-f6dffe42f77044deadd217ea3aeb7222
6.5G ./data/yb-data/tserver/data/rocksdb/table-000030af000030008000000000004070
基本上,我在數(shù)據(jù)庫中的數(shù)據(jù)大小和我輸入的CSV文本大致相同。
WAL 大小
WAL的作用是保護(hù)在內(nèi)存中所做的更改(LSM樹的第一級(jí)是一個(gè)MemTable)。 它具有由以下參數(shù)定義的保留,我使用默認(rèn)設(shè)置:
--log_min_seconds_to_retain=900
--log_min_segments_to_retain=2
--log_segment_size_mb=64
這意味著在這個(gè)表上15分鐘沒有活動(dòng)之后,它應(yīng)該會(huì)被tablets縮小到2x64MB的段,而我有兩個(gè)tablets。 這是我午休后的照片:

壓縮
我這里有5個(gè)SST文件,因?yàn)槟J(rèn)的,所以不會(huì)觸發(fā)進(jìn)一步的自動(dòng)壓縮
rocksdb_level0_file_num_compaction_trigger=5
我可以手動(dòng)運(yùn)行一個(gè):
time yb-admin --master_addresses $(echo yb-master-{0..2}:7100|tr ' ' ,)\
compact_table_by_id 000030af000030008000000000004070 300
這將減少到每片一個(gè)文件:

在我的示例中,總大小沒有改變,因?yàn)槲抑患虞d了沒有進(jìn)一步更改的行,所以沒有舊版本可以壓縮。
PostgreSQL
我啟動(dòng)一個(gè) PostgreSQL 容器來比較相同的負(fù)載
docker pull postgres
docker run --name pg14 -e POSTGRES_PASSWORD=franck -d postgres
docker exec -it pg14 bash
我運(yùn)行與(上面定義的gen_random_csv和gen_table_ddl)相同的方法gen_pg來加載 600MB數(shù)據(jù)
time gen_pg 100 60 100000 franck_varchar |
psql -U postgres -e -v ON_ERROR_STOP=ON
這很快:
drop table if exists franck_varchar;
DROP TABLE
create table franck_varchar ( id bigint primary key check (id<=100000), col1 varchar(100), col2 varchar(100), col3 varchar(100), col4 varchar(100), col5 varch
ar(100), col6 varchar(100), col7 varchar(100), col8 varchar(100), col9 varchar(100), col10 varchar(100), col11 varchar(100), col12 varchar(100), col13 varchar
(100), col14 varchar(100), col15 varchar(100), col16 varchar(100), col17 varchar(100), col18 varchar(100), col19 varchar(100), col20 varchar(100), col21 varch
ar(100), col22 varchar(100), col23 varchar(100), col24 varchar(100), col25 varchar(100), col26 varchar(100), col27 varchar(100), col28 varchar(100), col29 var
char(100), col30 varchar(100), col31 varchar(100), col32 varchar(100), col33 varchar(100), col34 varchar(100), col35 varchar(100), col36 varchar(100), col37 v
archar(100), col38 varchar(100), col39 varchar(100), col40 varchar(100), col41 varchar(100), col42 varchar(100), col43 varchar(100), col44 varchar(100), col45
varchar(100), col46 varchar(100), col47 varchar(100), col48 varchar(100), col49 varchar(100), col50 varchar(100), col51 varchar(100), col52 varchar(100), col
53 varchar(100), col54 varchar(100), col55 varchar(100), col56 varchar(100), col57 varchar(100), col58 varchar(100), col59 varchar(100), col60 varchar(100));
CREATE TABLE
copy franck_varchar from stdin with csv;
COPY 100000
real 1m29.669s
user 0m32.372s
sys 1m14.037s
查看pg_relation_size時(shí)要小心:
postgres=#
select
pg_size_pretty(pg_relation_size('franck_varchar')),
current_setting('data_directory')
||'/'||pg_relation_filepath('franck_varchar');
pg_size_pretty | ?column?
----------------+-------------------------------------------
195 MB | /var/lib/postgresql/data/base/13757/16384
如何用195MB存儲(chǔ)600MB?這是因?yàn)槲业男斜纫粋€(gè)頁面可以容納的要大(PostgreSQL以塊的形式存儲(chǔ)元組)。TOAST用于存儲(chǔ)溢出。讓我們看看我的數(shù)據(jù)庫文件:
postgres=# \! du -ah /var/lib/postgresql/data/base/13757 | sort -h | tail -5
2.2M /var/lib/postgresql/data/base/13757/16390
105M /var/lib/postgresql/data/base/13757/16389
196M /var/lib/postgresql/data/base/13757/16384
661M /var/lib/postgresql/data/base/13757/16388
972M /var/lib/postgresql/data/base/13757
以下是目錄中的相關(guān)元數(shù)據(jù):
postgres=#
select pg_size_pretty(pg_relation_size(oid))
, oid, relname, relkind, relpages, reltuples, reltoastrelid
from pg_class
where oid in (16390,16389,16384,16388)
order by pg_relation_size(oid);
pg_size_pretty | oid | relname | relkind | relpages | reltuples | reltoastrelid
----------------+-------+----------------------+---------+----------+-----------+---------------
2208 kB | 16390 | franck_varchar_pkey | i | 276 | 100000 | 0
105 MB | 16389 | pg_toast_16384_index | i | 1 | 0 | 0
195 MB | 16384 | franck_varchar | r | 25000 | 100000 | 16388
660 MB | 16388 | pg_toast_16384 | t | 84483 | 4.9e+06 | 0
600MB在TOAST中,實(shí)際上是660 + 105MB用于索引。 我在表中有額外的195MB,用于non-toasted的列和行內(nèi)部屬性。 而且,由于 PostgreSQL 將表存儲(chǔ)在堆表中,所以主鍵與索引有一個(gè)額外的關(guān)系,但是這個(gè)關(guān)系很小:只有2MB。總共需要 972MB 來存儲(chǔ) 600MB 的原始數(shù)據(jù)。 當(dāng)然,這會(huì)對(duì)查詢性能產(chǎn)生影響,但這是另一個(gè)話題。
從這一點(diǎn)來看,由于堆表、頁面和元組的原因,PostgreSQL 中的存儲(chǔ)似乎不如使用 LSM 樹和 SSTables 的 YugabyteDB 化。PostgreSQL 有一些優(yōu)化,但基本上這種情況(我從我們slack channel的用戶那里得到)不能從壓縮中受益(閾值是 2KB 文本)。當(dāng)然,您可能想知道在任何數(shù)據(jù)庫中存儲(chǔ) 60 列 100 個(gè)字符是否有意義。JSON 可能更適合它,因?yàn)樗且粋€(gè)文檔。
Oracle Database
最開始的問題是與甲骨文的比較。
讓我們啟動(dòng)一個(gè)容器:
docker pull gvenzl/oracle-xe
docker run --name ora -e ORACLE_PASSWORD=franck -d gvenzl/oracle-xe
你得等一等, 空的Oracle數(shù)據(jù)庫并不輕。 Docker日志記錄ora,直到看到監(jiān)聽器成功啟動(dòng)。 不用擔(dān)心The listener supports no services…它們將被動(dòng)態(tài)注冊(cè)。
我使用gen_table_ddl上面定義的創(chuàng)建表:
gen_table_ddl 100 60 100000 franck_varchar | sed -e '/create table/s/bigint/number/' | sqlplus system/franck@//localhost/xepdb1
我生成的CSV,如我上面所做的gen_random_csv,但現(xiàn)在到一個(gè)linux命名|被SQLLoader讀取,因?yàn)槲也徽J(rèn)為SQLLoader可以從stdin讀取:
mknod franck_varchar.dat p
gen_random_csv 100 60 100000 > franck_varchar.dat &
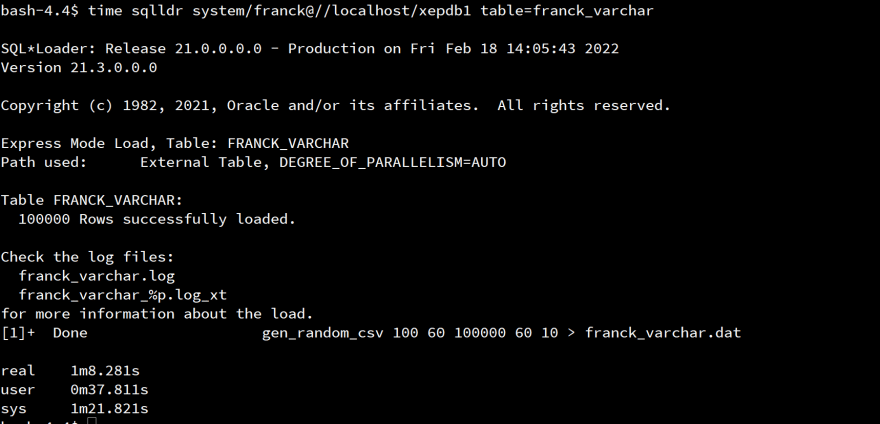
并使用所有默認(rèn)值的 SQL*Loader Express 調(diào)用:
time sqlldr system/franck@//localhost/xepdb1 table=franck_varchar
這很快:
從字典中快速檢查大小:
sqlplus system/franck@//localhost/xepdb1
SQL>
select segment_type||' '||segment_name||': '
||dbms_xplan.format_size(bytes)
from dba_segments
where owner=user and segment_name in (
'FRANCK_VARCHAR'
,(select index_name from user_indexes where table_name='FRANCK_VARCHAR'))
;
SEGMENT_TYPE||''||SEGMENT_NAME||':'||DBMS_XPLAN.FORMAT_SIZE(BYTES)
--------------------------------------------------------------------------------
TABLE FRANCK_VARCHAR: 783M
INDEX SYS_C008223: 2048K
和PostgreSQL一樣,索引是2M。 堆表是783M,比我的原始數(shù)據(jù)稍高。 注意,我在這里保留了缺省PCTFREE。 當(dāng)你在堆表上將它們的行存儲(chǔ)到塊中時(shí),這些都是需要注意的。 Oracle有一些壓縮選項(xiàng),但對(duì)于這個(gè),你需要購買Exadata來獲得HCC,或者將你的數(shù)據(jù)移動(dòng)到他們的云上。 其他表壓縮選項(xiàng)在這里沒有任何作用,因?yàn)闆]有重復(fù)的值。
這里,我在每一列中插入了100個(gè)字符,因?yàn)檫@是我的測(cè)試用例。 但我知道,在YugabyteDB中,將列存儲(chǔ)為子文檔對(duì)每列都有開銷,這是基于塊的堆表中可變大小行的開銷。 然后我在gen_random_csv 1 60 100000的每列中只運(yùn)行一個(gè)字符.
CSV 中的卷現(xiàn)在為 13MB:
# time gen_pg 1 60 100000 franck_varchar | wc -c | numfmt --to=si
13M
我已經(jīng)導(dǎo)入了這個(gè)并檢查了存儲(chǔ)
甲骨文:
SEGMENT_TYPE||''||SEGMENT_NAME||':'||DBMS_XPLAN.FORMAT_SIZE(BYTES)
--------------------------------------------------------------------------------
TABLE FRANCK_VARCHAR: 8192K
INDEX SYS_C008223: 2048K
8MB的數(shù)據(jù),2MB的索引————這很小。 這甚至比CSV文件還少一點(diǎn)… ??但是,等等。 沒有解釋的實(shí)驗(yàn)結(jié)果是不可信的。 唯一可以更小的是NUMBER數(shù)據(jù)類型。 ???♂?我記得我之前用ALTER TABLE franck_varchar MOVE COMPRESS做了一個(gè)測(cè)試,沒有重新創(chuàng)建表。 它沒有改變隨機(jī)的100個(gè)字符值,但現(xiàn)在我有很多重復(fù)的每個(gè)塊只有一個(gè)字符隨機(jī)。
讓我們?cè)谥匦聞?chuàng)建表的情況下再次運(yùn)行它:
SEGMENT_TYPE||''||SEGMENT_NAME||':'||DBMS_XPLAN.FORMAT_SIZE(BYTES)
--------------------------------------------------------------------------------
TABLE FRANCK_VARCHAR: 15M
INDEX SYS_C008225: 2048K
是的,這是正確的。 如果沒有壓縮,卷只比原始卷加上索引高一點(diǎn)。
#### PostgreSQL:
pg_size_pretty | ?column?
----------------+----------------------------------------------
15 MB | /var/lib/postgresql/data/base/13757/19616663
oid | relname | reltoastrelid
----------+----------------+---------------
\! du -ah /var/lib/postgresql/data/base/13757 | sort -h | tail -5
752K /var/lib/postgresql/data/base/13757/1255
752K /var/lib/postgresql/data/base/13757/2840
2.2M /var/lib/postgresql/data/base/13757/19616667
16M /var/lib/postgresql/data/base/13757/19616663
27M /var/lib/postgresql/data/base/13757
這里沒有TOAST, 2MB用于索引,16MB用于堆表。 PostgreSQL有大量的逐行元數(shù)據(jù)來管理鎖和MVCC。
YugabyteDB:
Total: 328.32M
Consensus Metadata: 19.7K
WAL Files: 255.80M
SST Files: 72.50M
SST Files Uncompressed: 237.76M
因?yàn)槲臋n存儲(chǔ)中的每列存儲(chǔ),我預(yù)計(jì)會(huì)很大。 由于壓縮,簡(jiǎn)單的基于增量編碼的前綴壓縮,以及默認(rèn)的——enable_ondisk_compression=true——compression_type=Snappy,這不會(huì)帶來太多好處。 當(dāng)然,如果你將YugabyteDB與Oracle或PostgreSQL進(jìn)行比較,會(huì)看到 4 倍的系數(shù)。 但這不是在現(xiàn)實(shí)生活中應(yīng)該看到的,存儲(chǔ)60列,其中只有一個(gè)字節(jié)。 我們擁有所有 PostgreSQL 數(shù)據(jù)類型,例如 ARRAY 或 JSONB。 對(duì)于填充列的增強(qiáng),還有一個(gè)未解決的問題。 順便說一下,我是在YugabyteDB 2.11.2中運(yùn)行這個(gè).
概括
我在一個(gè)特定的案例中做了這個(gè)測(cè)試,我得到了一個(gè)關(guān)于存儲(chǔ)到Y(jié)ugabyteDB的大小的問題。 當(dāng)然,所有這些都取決于列數(shù)、數(shù)據(jù)類型、值、寫模式、數(shù)據(jù)庫設(shè)置、讀性能需求等等。 今天,開發(fā)人員沒有時(shí)間對(duì)所有這些進(jìn)行微調(diào)。像YugabyteDB平板存儲(chǔ)所基于的RocksDB這樣的鍵值對(duì)文檔存儲(chǔ)更容易。在壓縮 SST 文件期間,少量的寫入放大通過壓縮來平衡。橫向擴(kuò)展的能力可以克服任何限制。
總之,現(xiàn)代SQL數(shù)據(jù)庫也支持JSON文檔,比如PostgreSQL JSONB,也可以在YugabyteDB或Oracle OSON中使用。 如果您有60列的文本,那么也許這應(yīng)該放到一個(gè)文檔中。
