




如何查詢數(shù)據(jù)庫(kù)中未使用綁定變量的SQL語(yǔ)句?
[TOC]
? 背景:
? 我們會(huì)經(jīng)常在一些客戶的AWR報(bào)告中,能夠看到如下類似信息,SQL的前綴部分都一樣,執(zhí)行時(shí)間也基本一致,詳細(xì)查看具體的SQL_TEXT后,我們可以看到僅僅是where條件中的變量值不一樣,其他都一樣,沒(méi)有采用綁定變量的方式,而是一個(gè)個(gè)常量。
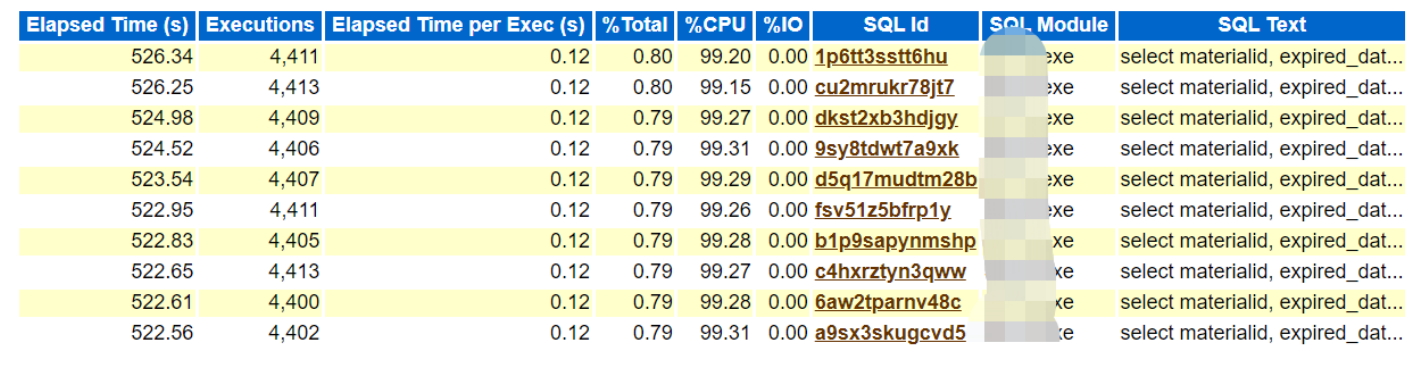
對(duì)于這種在AWR報(bào)告中,能夠體現(xiàn)出來(lái)的,我們比較容易發(fā)現(xiàn),可及時(shí)反饋給開(kāi)發(fā)人員處理。但是在一些環(huán)境中,系統(tǒng)中其實(shí)存在較多的未使用綁定變量的SQL,但是在AWR報(bào)告TOP SQL部分,并沒(méi)有體現(xiàn)出來(lái),這個(gè)時(shí)候,就需要我們?nèi)?shù)據(jù)庫(kù)中手動(dòng)撈取。
當(dāng)Oracle中存在大量的類似sql,基本結(jié)構(gòu)一樣,僅where條件的取值不一樣時(shí),我們應(yīng)該采用綁定變量的方法,來(lái)減少sql的硬解析,能夠提高數(shù)據(jù)庫(kù)性能,避免出現(xiàn)shared pool相關(guān)的等待事件,同時(shí)也能節(jié)約CPU資源。
下面我們通過(guò)案例,如果查詢數(shù)據(jù)庫(kù)中未使用綁定變量的SQL?
1. 構(gòu)造環(huán)境
-- 創(chuàng)建測(cè)試表,并插入數(shù)據(jù)
SQL> set timing on
SQL> drop table t purge;
Table dropped.
Elapsed: 00:00:00.18
SQL> create table t(x int);
Table created.
Elapsed: 00:00:00.04
SQL> begin
2 for i in 1 .. 1000
3 loop
4 execute immediate
5 'insert into t values (:x)' using i;
6 end loop;
7 commit;
8 end;
9 /
PL/SQL procedure successfully completed.
Elapsed: 00:00:00.03
SQL> select count(*) from t;
COUNT(*)
----------
1000
Elapsed: 00:00:00.00
2. 案例演示
– 方便演示,我們清理一下shared pool
SQL> alter system flush shared_pool;
System altered.
Elapsed: 00:00:00.12
2.1 未使用綁定變量
SQL> begin
2 for i in 1 .. 1000
3 loop
4 execute immediate
5 'select /*tag1*/ count(*) from t where x= '||i||'';
6 end loop;
7 commit;
8 end;
9 /
PL/SQL procedure successfully completed.
Elapsed: 00:00:00.38
2.2 使用綁定變量
SQL> begin
2 for i in 1 .. 1000
3 loop
4 execute immediate
5 'select /*tag2*/ count(*) from t where x= :1' using i;
6 end loop;
7 commit;
8 end;
9 /
PL/SQL procedure successfully completed.
Elapsed: 00:00:00.01
3. 獲取未使用綁定變量的SQL
方法一:通過(guò)force_matching_signature分析
? 10g以后v$SQL動(dòng)態(tài)性能視圖增加了FORCE_MATCHING_SIGNATURE列,其官方定義為:
The signature used when the CURSOR_SHARING parameter is set to FORCE,也就是Oracle通過(guò)將原SQL_TEXT轉(zhuǎn)換為可能的FORCE模式后計(jì)算得到的一個(gè)SIGNATURE值。我們知道,如果cursor sharing設(shè)置為force , oracle將類似的SQL的謂詞用一個(gè)變量代替,同時(shí)將它們看做同一條SQL語(yǔ)句處理。
SQL> set numwidth 20
SQL> select force_matching_signature,count(1) from v$sql group by force_matching_signature order by count(1) desc;
FORCE_MATCHING_SIGNATURE COUNT(1)
------------------------ --------------------
11420119939742656807 1000
0 14
4650186927289073934 2
6434074771071323635 2
1435631005720608251 1
12313764141852424472 1
9194475184364435657 1
12005390545862180746 1
SQL> select sql_text from v$sql where force_matching_signature=11420119939742656807 and rownum<10;
SQL_TEXT
--------------------------------------------------------------------------------
select /*tag1*/ count(*) from t where x= 782
select /*tag1*/ count(*) from t where x= 497
select /*tag1*/ count(*) from t where x= 286
select /*tag1*/ count(*) from t where x= 937
select /*tag1*/ count(*) from t where x= 458
select /*tag1*/ count(*) from t where x= 969
select /*tag1*/ count(*) from t where x= 637
select /*tag1*/ count(*) from t where x= 161
select /*tag1*/ count(*) from t where x= 742
9 rows selected.
Elapsed: 00:00:00.00
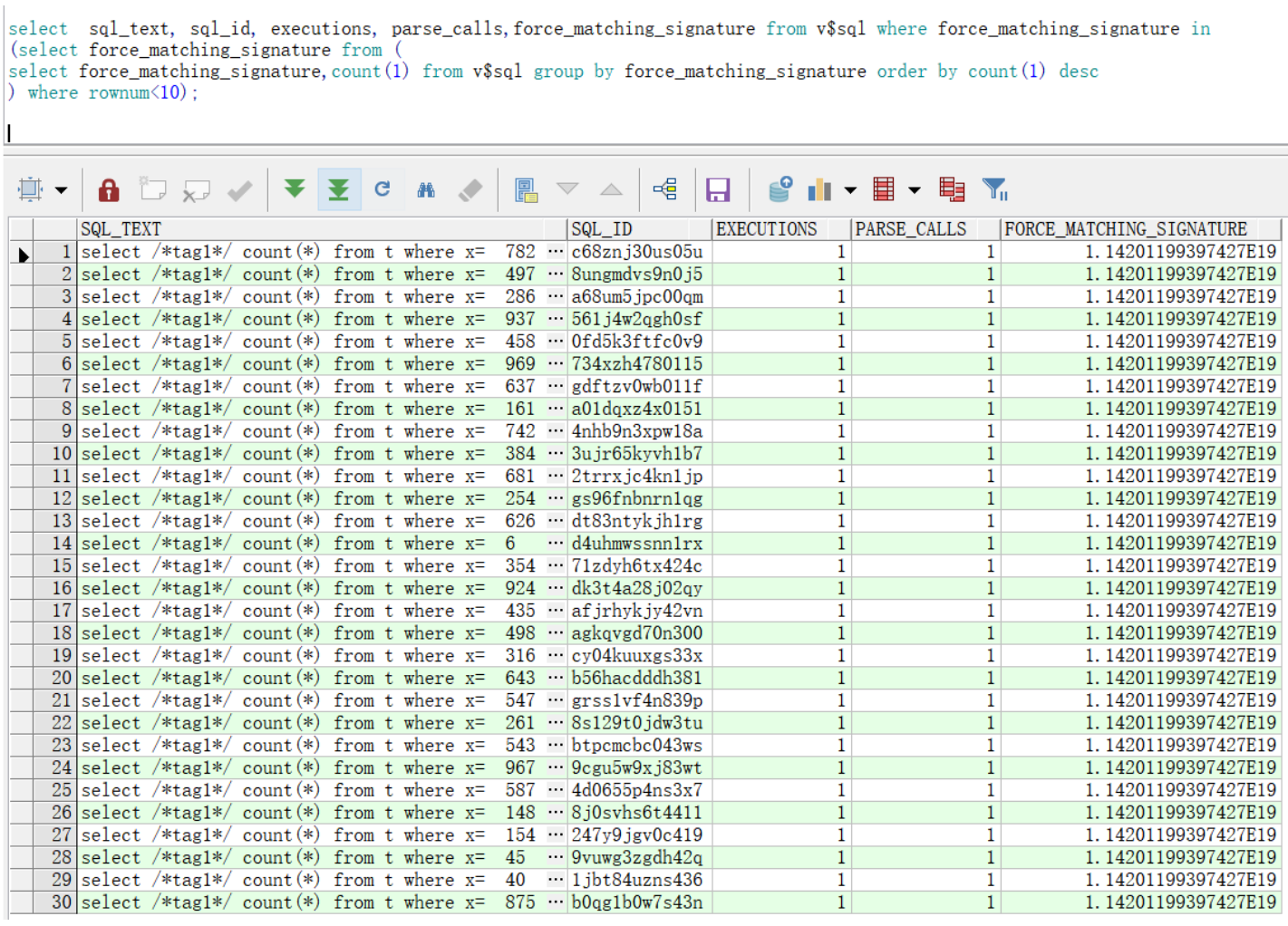
將上面SQL整合到一起,如下:
select sql_text, sql_id, executions, parse_calls,force_matching_signature from v$sql where force_matching_signature in
(select force_matching_signature from (
select force_matching_signature,count(1) from v$sql group by force_matching_signature order by count(1) desc
) where rownum<10);
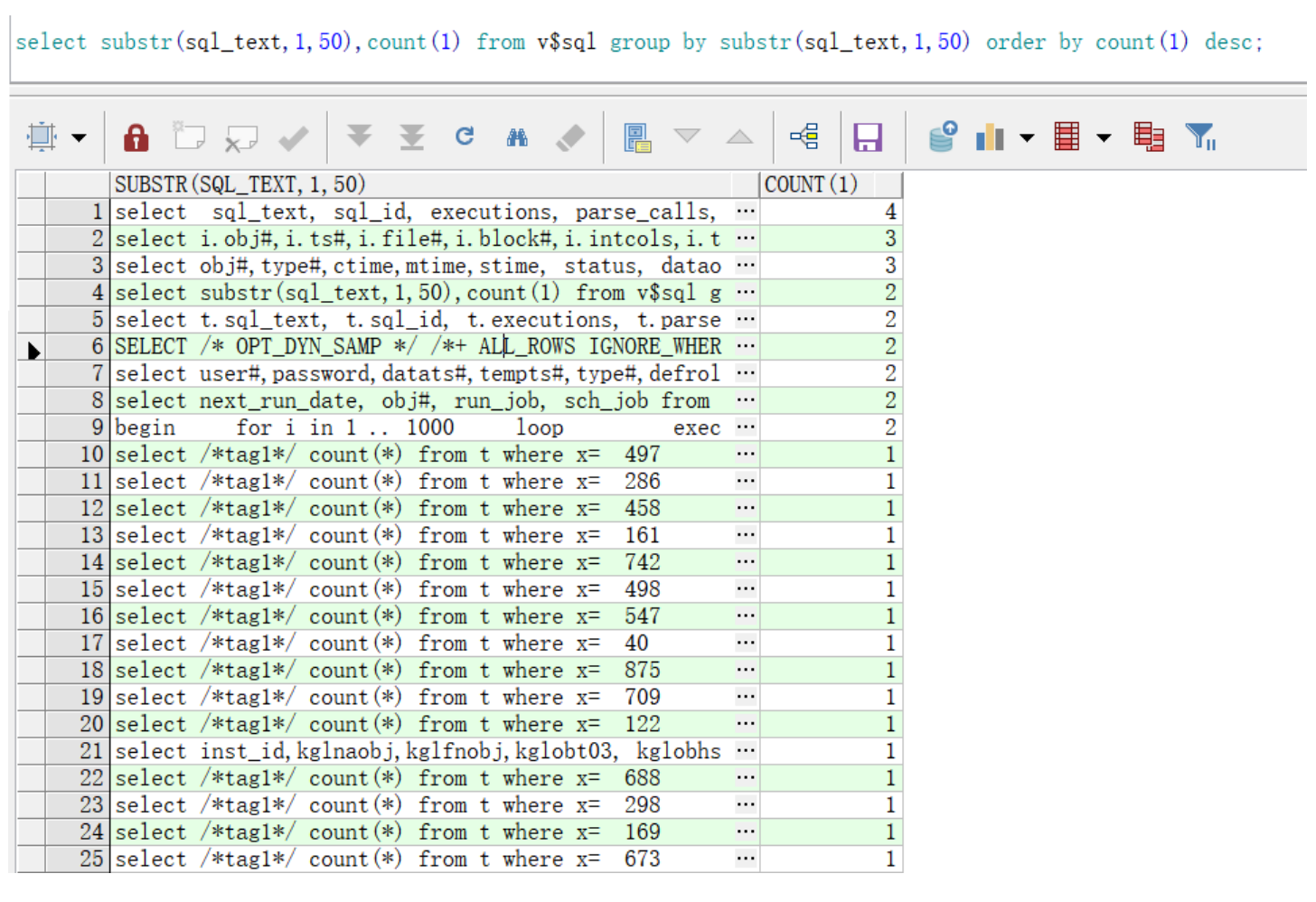
方法二:通過(guò)sql文本分析
select substr(sql_text,1,50),count(1) from v$sql group by substr(sql_text,1,50) order by count(1) desc;
4. 思考綁定變量性能
4.1 未使用綁定變量
select t.sql_text, t.sql_id, t.executions, t.parse_calls,force_matching_signature
from v$sql t
where sql_text like 'select /*tag1*/ count(*) from t%';
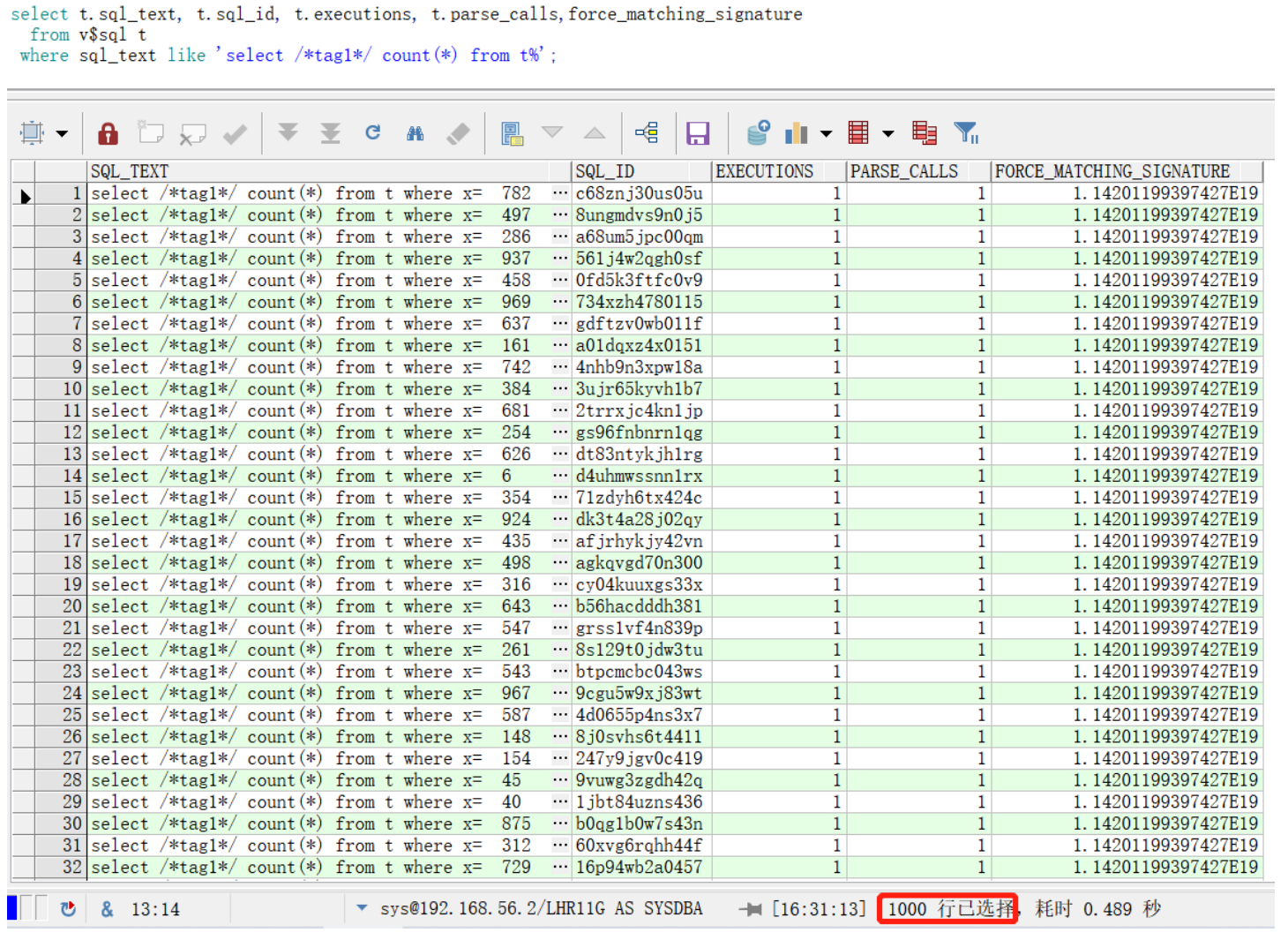
結(jié)論:產(chǎn)生1000個(gè)的類似sql,基本結(jié)構(gòu)一樣,僅where條件的取值不一樣,每個(gè)SQL都執(zhí)行一次,解析一次。
4.2 使用綁定變量
select t.sql_text, t.sql_id, t.executions, t.parse_calls,force_matching_signature
from v$sql t
where sql_text like 'select /*tag2*/ count(*) from t%';
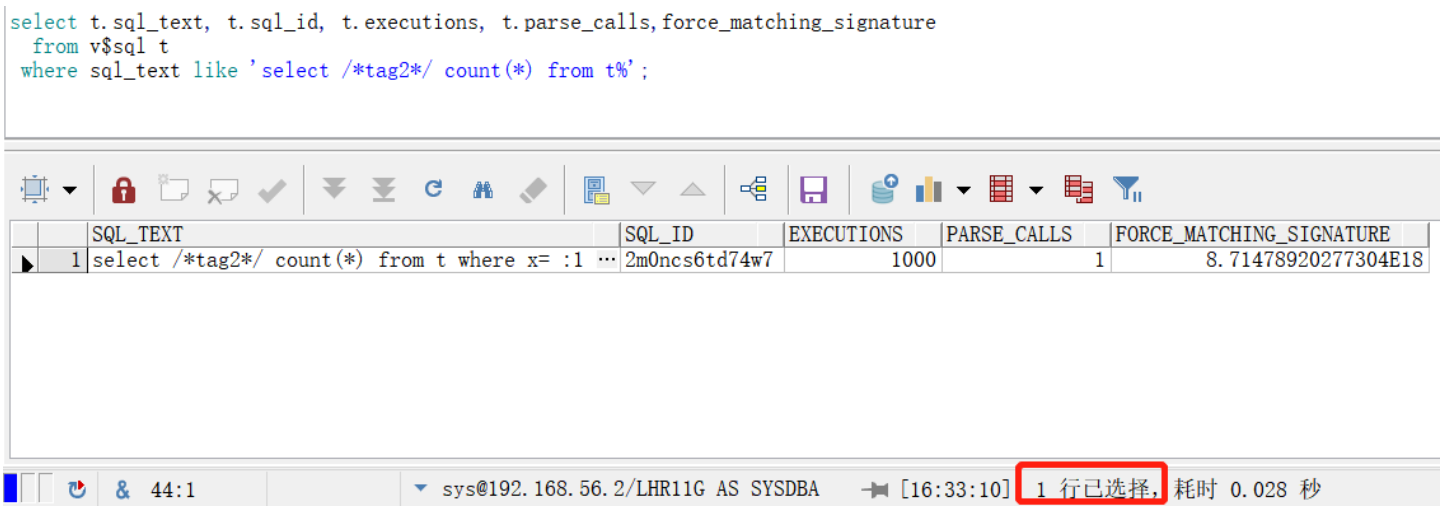
結(jié)論:1. 僅產(chǎn)生1個(gè)SQL,執(zhí)行1000次,僅解析一次。和未使用綁定變量相比,性能更好。
? 2. 從案例演示中,2個(gè)SQL執(zhí)行時(shí)間來(lái)看,使用綁定變量的方式也比未使用綁定變量的方式快很多。
