




第一章 問題引入分析
在分析客戶環境的一條SQL時,發現了無法順利謂詞推入的現象。故此對案例做了進一步模擬及測試。以確定問題原因。數據庫版本:ORACLE 11G。
SELECT 。。。 --省略部分
FROM (SELECT
。。。 --省略部分
FROM t_a a
UNION ALL
SELECT
。。。 --省略部分
FROM t_b rc) cc
WHERE EXISTS (SELECT 1
FROM t
WHERE t.case_id = cc.case_id
AND t.code = 'xxxxxxxxxxxxx');
其中,子查詢中的code列具有很好的過濾條件,返回行數很少。且對應視圖cc中相關表的關聯列case_id也包含索引。在這種情況下,個人理解優化器應該是可以順利的將外面EXISTS子查詢的關聯列推入到視圖CC內的,從而通過訪問CC的索引來避免視圖CC中的兩次全表掃描訪問的。
而實際事與愿違,不論如何添加hint,都無法推入關聯條件到CC視圖內。總是通過全表掃描訪問大表。造成性能問題。也自己檢查了滿足謂詞推入的條件。確定當前場景下理應可以謂詞推入:

拋開連接方式不談,首先CC視圖就是包含UNION/ALL類的,是滿足謂詞推入的前提條件的。
基于上述問題現象,設計了如下測試腳本:以供后續實驗進一步定位問題:
CREATE TABLE SZT.T1CO AS SELECT * FROM DBA_OBJECTS;
CREATE TABLE SZT.T2CO AS SELECT * FROM DBA_OBJECTS;
CREATE TABLE SZT.T1 AS SELECT * FROM DBA_OBJECTS;
CREATE INDEX SZT.IDX_T2CO_ID ON SZT.T2CO(OBJECT_ID);
CREATE INDEX SZT.IDX_T1CO_ID ON SZT.T1CO(OBJECT_ID);
CREATE INDEX SZT.IDX_T1_DATA ON SZT.T1(DATA_OBJECT_ID);
exec dbms_stats.gather_table_stats(ownname=>'SZT',tabname=>'T1CO');
exec dbms_stats.gather_table_stats(ownname=>'SZT',tabname=>'T2CO');
exec dbms_stats.gather_table_stats(ownname=>'SZT',tabname=>'T1');
測試語句:
select count(*)
from (select object_id, object_name, data_object_id
from t2co
union all
select object_id, object_name, data_object_id
from t1co) cc
where exists (select 1
from t1
where data_object_id = '46'
and t1.object_id = cc.object_id);
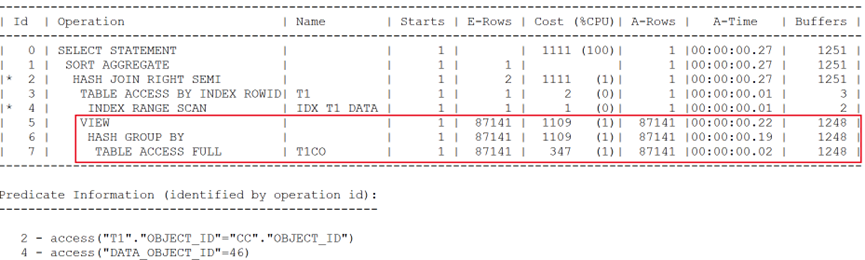
對應的執行計劃輸出如下:
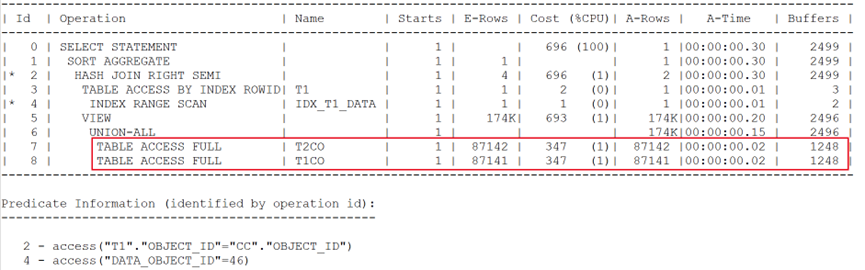
可以看到,盡管T1表預估與實際返回行數僅為1,但對于希望出現的謂詞推入到CC視圖的動作,仍然沒有出現。與原始問題現象保持一致,兩次全表訪問大表,造成性能問題。
第二章 不同關聯寫法的實驗對比
基于上一章節發現的性能問題,嘗試做了幾種結構相似的改寫,以確定無法謂詞推入的問題是否還存在。也設計了可以做謂詞推入的三種類似視圖。讓測試結果更全面。
2.1 內連接寫法
由于EXISTS關聯子查詢只是為了與CC視圖做半連接,可以等價的將EXISTS子查詢改寫為如下類別語句:
t1子查詢去重后與原始的exists子查詢完全等價。
2.1.1 UNION視圖
select count(*)
from (select object_id, object_name, data_object_id
from t2co
union all
select object_id, object_name, data_object_id
from t1co) cc,
(select distinct t1.object_id
from t1
where data_object_id = '46') t1
where t1.object_id = cc.object_id ;
執行計劃如下:
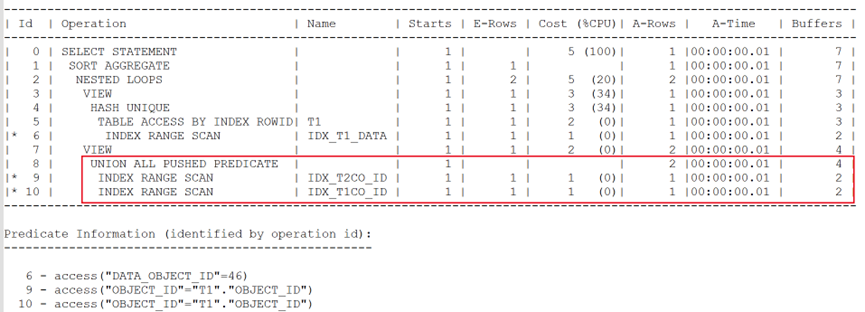
由于改寫為內連接形式,順利實現了謂詞推入,這才是我們希望看到的高效查詢。
2.1.2 DISTINCT視圖
將CC視圖改寫為distinct視圖。
select count(*)
from (select distinct object_id, object_name, data_object_id
from t1co) cc,
(select distinct t1.object_id
from t1
where data_object_id = '46') t1
where t1.object_id = cc.object_id ;
執行計劃如下:
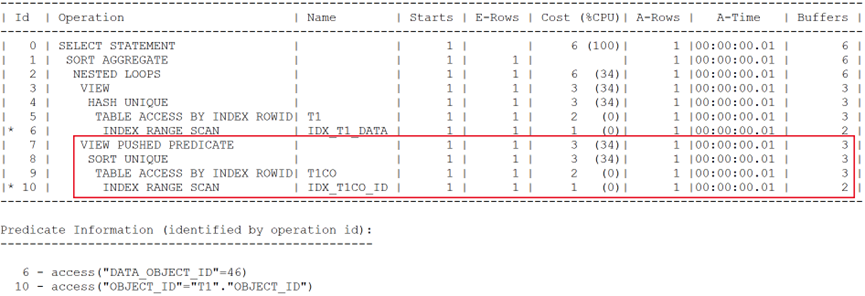
同樣做了謂詞推入。
2.1.3 GROUP BY視圖
將CC視圖改寫為group by視圖。
select count(*)
from (select object_id, object_name, data_object_id,COUNT(*) CNT
from t1co
GROUP BY object_id, object_name, data_object_id) cc,
(select distinct t1.object_id
from t1
where data_object_id = '46') t1
where t1.object_id = cc.object_id ;
執行計劃如下:
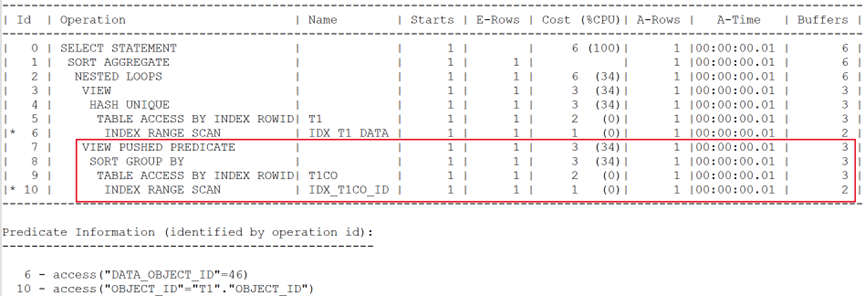
同樣做了謂詞推入。
2.2 EXISTS關聯子查詢
UNION視圖上面已經測試過,無法謂詞推入,這里不再測試。
2.2.1 DISTINCT視圖
將CC視圖改寫為distinct視圖。
select count(*)
from (
select distinct object_id, object_name, data_object_id
from t1co) cc
where exists (select 1
from t1
where data_object_id = '46'
and t1.object_id = cc.object_id);
執行計劃如下:
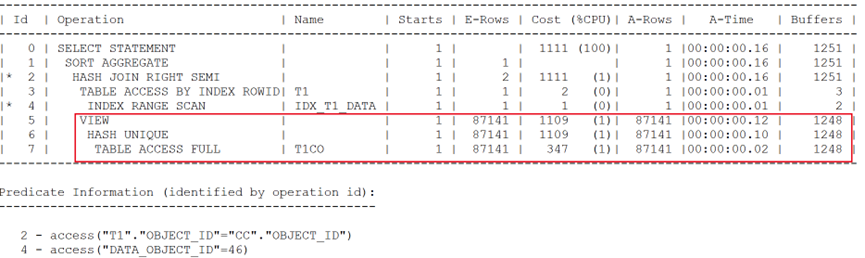
盡管將視圖調整為distinct。但謂詞推入技術仍沒有出現,訪問大表造成性能問題。
2.2.2 GROUP BY視圖
將CC視圖改寫為group by視圖。
select count(*)
from (
select object_id, object_name, data_object_id,count(*)
from t1co
group by object_id, object_name, data_object_id) cc
where exists (select 1
from t1
where data_object_id = '46'
and t1.object_id = cc.object_id);
執行計劃如下:
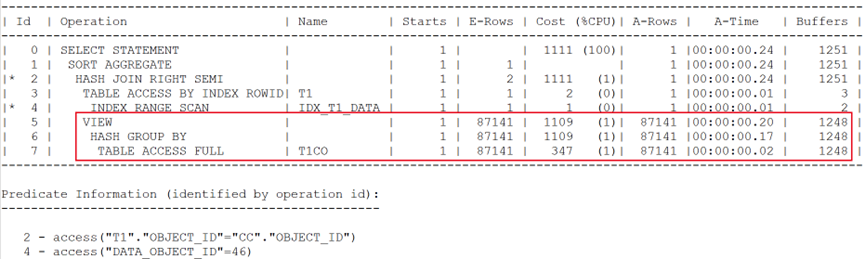
盡管將視圖調整為group by。但謂詞推入技術仍沒有出現,訪問大表造成性能問題。
2.3 IN子查詢
EXISTS子查詢是可以等價改寫為IN子查詢的。這里繼續測試。
2.3.1 UNION視圖
select count(*)
from (select object_id, object_name, data_object_id
from t2co
union all
select object_id, object_name, data_object_id
from t1co) cc
where cc.object_id IN (select t1.object_id
from t1
where data_object_id = '46');
執行計劃如下:
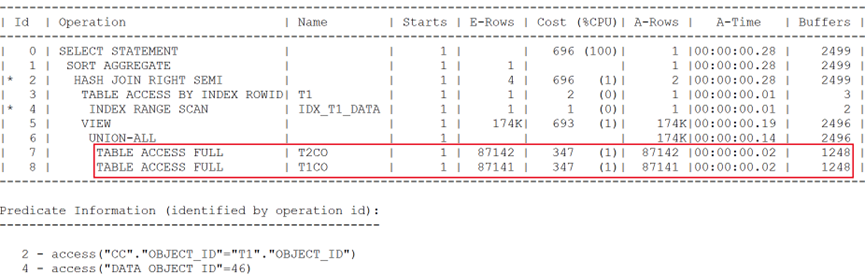
通過IN子查詢寫法,仍然無法完成謂詞推入。
2.3.2 DISTINCT視圖
將CC視圖改寫為distinct視圖。
select count(*)
from (
select distinct object_id, object_name, data_object_id
from t1co) cc
where cc.object_id IN (select t1.object_id
from t1
where data_object_id = '46');
執行計劃如下:
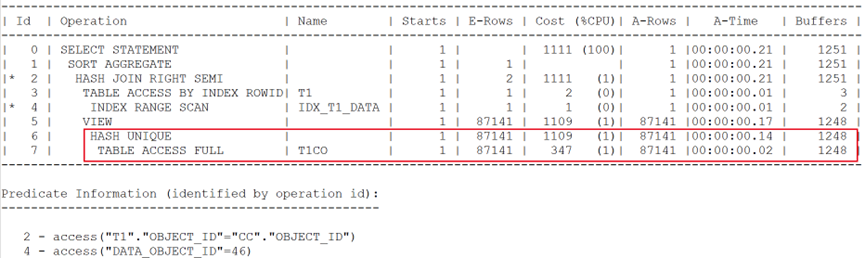
盡管將視圖調整為distinct。但謂詞推入技術仍沒有出現,訪問大表造成性能問題。
2.3.3 GROUP BY視圖
將CC視圖改寫為group by視圖。
select count(*)
from (
select object_id, object_name, data_object_id,count(*)
from t1co
group by object_id, object_name, data_object_id) cc
where cc.object_id IN (select t1.object_id
from t1
where data_object_id = '46');
執行計劃如下:
盡管將視圖調整為group by。但謂詞推入技術仍沒有出現,訪問大表造成性能問題。
第三章 問題總結
經過上述三種場景,九個實驗的測試過程可知:
只有與視圖間是直接連接的寫法,可以順利實現謂詞推入。而對于使用了子查詢做主要過濾條件的寫法,都不能完成謂詞推入。這里分析可能優化器在對子查詢做子查詢展開后,并沒有對能否進一步做謂詞推入做比較全面的嘗試,導致謂詞推入失敗。
為了進一步分析問題。嘗試對UNION視圖的查詢做了10053分析。
其中不能謂詞推入的EXISTS寫法,是有如下信息:
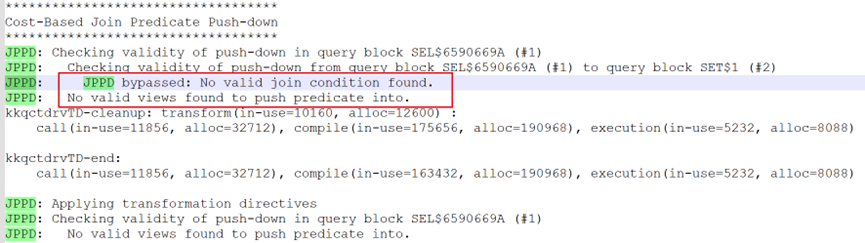
沒有發現有效的連接條件;
沒有發現可將謂詞推入的有效視圖。
這里看到優化器也是嘗試做了謂詞推入的嘗試,但沒有成功。
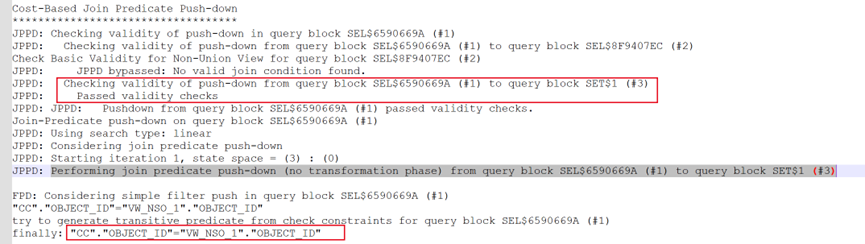
而通過連接寫法的視圖,其10053中是可以順利找到謂詞推入視圖的:

這里看到,成功的找到可以謂詞推入的條件,并將謂詞推入到了視圖內部。
通過本篇的實驗,告訴我們在SQL中的主要過濾條件如果在子查詢中,如果還希望將連接條件推入到外部視圖中去。是無法順利完成的。因此就需要我們在編寫SQL的時候,對這種場景進行分析。避免通過子查詢完成主要的過濾條件。
第四章 最后的話
以上測試僅是在ORACLE 11G環境完成的,不排除隨著版本的升級,ORACLE優化器可能會修復上述明顯的問題缺陷。
因此又在12C的場景下做了簡單測試。發現只有IN子查詢及UNION視圖的組合,才可以順利推入,對于其他寫法及視圖的組合,仍然不能謂詞推入。
查看10053信息:
ST: Query in kkqstardrv:******* UNPARSED QUERY IS *******

可以看到12C環境也僅是把目標SQL轉換成內連接的寫法,才順利的實現了謂詞推入。
這里也可以看出,優化器找到了可以謂詞推入的條件,從而順利的推入。
