




PostgreSQL數(shù)據(jù)庫(kù)有著各種各樣的高可用方案,絕大多數(shù),都是基于流復(fù)制機(jī)制實(shí)現(xiàn)的,常見(jiàn)的例如Patroni+DCS,Pacemaker+Corosync,Repmgr,keepalived,pg_auto_failover,PGpool等等,其中使用較多的應(yīng)該是Patroni和Repmgr兩種,下文針對(duì)PostgreSQ的兩種高可用方案Repmgr和Patroni進(jìn)行部分場(chǎng)景對(duì)比。
一、Repmgr
1.Repmgr特點(diǎn)
Repmgr是2010年由2ndQuadrant推出的一款PostgreSQL故障切換工具,repmgr是一個(gè)開源工具套件,用于管理PostgreSQL服務(wù)器集群中的復(fù)制和故障轉(zhuǎn)移。它擴(kuò)展了PostgresSQL內(nèi)建的hot-standby能力,可以監(jiān)控復(fù)制和執(zhí)行管理任務(wù)。
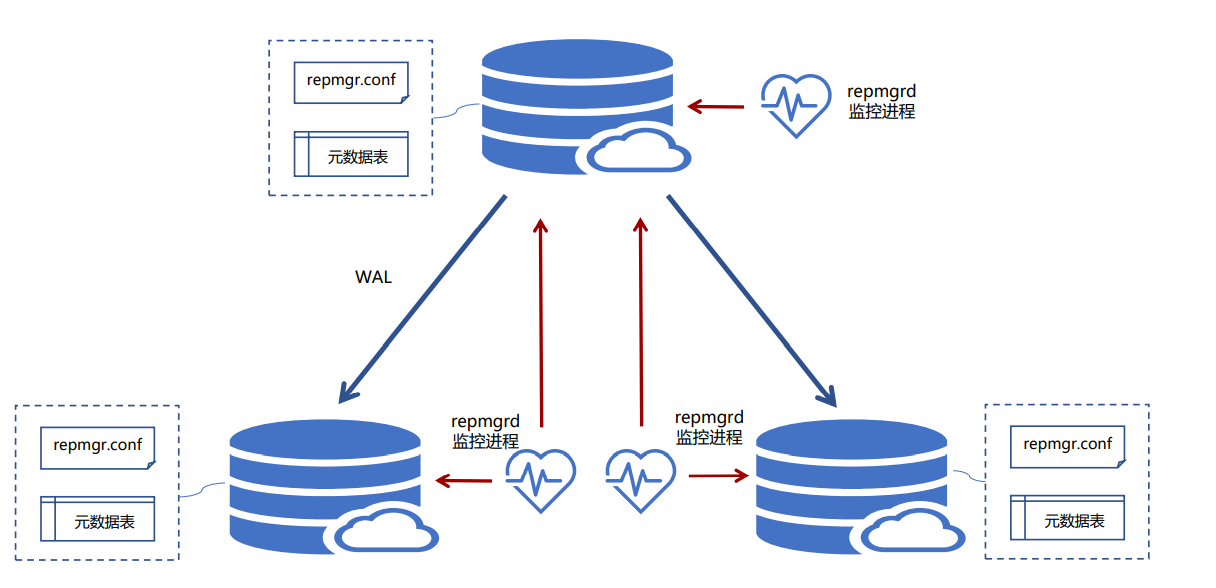
(1)Repmgr命令管理 (replication manager)
Repmgr是一個(gè)命令行工具,日常操作主要通過(guò)Repmgr進(jìn)行操作,功能包括集群狀態(tài)查看、switchover、克隆備庫(kù)、失效節(jié)點(diǎn)重新加入等。
用于執(zhí)行管理任務(wù)的命令行工具,主要有以下方面作用:
- 設(shè)置備用服務(wù)器
- 將備用服務(wù)器升級(jí)為主服務(wù)器
- 切換主服務(wù)器和備用服務(wù)器
- 顯示流復(fù)制狀態(tài)
- clone恢復(fù)備機(jī)數(shù)據(jù)
- 注冊(cè)節(jié)點(diǎn)
(2)Repmgrd守護(hù)進(jìn)程 (replication manager daemon)
Repmgrd 是一個(gè)守護(hù)進(jìn)程,支持故障檢測(cè)、failover,監(jiān)控和記錄集群信息以及自定義腳本接受集群事件通知event_notification_command,它有一組預(yù)定義的事件,并將這些事件的每次發(fā)生都存儲(chǔ)在 repmgr.events 表中。Repmgr 允許將事件通知傳遞給用戶定義的程序或腳本,該程序或腳本可以采取進(jìn)一步的行動(dòng),例如發(fā)送電子郵件或觸發(fā)任何警報(bào)。
可以使用Repmgrd設(shè)置自動(dòng)故障轉(zhuǎn)移。Repmgrd 需要在啟動(dòng) PostgreSQL 服務(wù)器時(shí)加載共享庫(kù)“repmgr”。庫(kù)名稱應(yīng)配置在 postgresql.conf 文件的shared_preload_libraries里。并且需要在 repmgr.conf 文件中設(shè)置 failover=automatic 參數(shù)。一旦設(shè)置了所有這些參數(shù),Repmgrd 守護(hù)程序就會(huì)開始主動(dòng)監(jiān)控集群。如果主節(jié)點(diǎn)出現(xiàn)任何故障,它將嘗試多次重新連接。當(dāng)所有連接到主節(jié)點(diǎn)的嘗試都失敗時(shí),Repmgrd 將通過(guò)選舉選擇最符合條件的備用節(jié)點(diǎn)作為新的主節(jié)點(diǎn)。
它主動(dòng)監(jiān)視復(fù)制集群中的服務(wù)器并執(zhí)行以下任務(wù):
- 監(jiān)控和記錄集群復(fù)制性能
- 通過(guò)檢測(cè)主服務(wù)器故障并提升最合適的備用服務(wù)器來(lái)執(zhí)行故障轉(zhuǎn)移
- 將有關(guān)群集中事件的通知提供給用戶定義的腳本,該腳本可以執(zhí)行諸如通過(guò)電子郵件發(fā)送警報(bào)等任務(wù)
- repmgrd 根據(jù)本地?cái)?shù)據(jù)庫(kù)角色不同,其功能也不同:
主庫(kù):repmgrd僅監(jiān)控本地?cái)?shù)據(jù)庫(kù),負(fù)責(zé)自動(dòng)恢復(fù)、同異步切換
備庫(kù):repmgrd監(jiān)控本地?cái)?shù)據(jù)庫(kù)和主數(shù)據(jù)庫(kù),負(fù)責(zé)自動(dòng)切換、復(fù)制槽刪除
(3)相關(guān)元數(shù)據(jù)
表
repmgr.events:用來(lái)記錄repmgr管理的事件信息
repmgr.nodes:復(fù)制群集中每個(gè)服務(wù)器的連接和狀態(tài)信息
repmgr.monitoring_history:repmgrd寫入的歷史備用監(jiān)視信息
repmgr.voting_term:【5.2新增】主要用來(lái)記錄投票信息
視圖
repmgr.show_nodes:基于表repmgr.nodes,增加了顯示上游節(jié)點(diǎn)的信息
repmgr.replication_status:?jiǎn)⒂胷epmgrd的監(jiān)視時(shí),顯示每個(gè)備用數(shù)據(jù)庫(kù)的當(dāng)前監(jiān)視狀態(tài)。
Repmgr元數(shù)據(jù)的schema可以存儲(chǔ)在現(xiàn)有的數(shù)據(jù)庫(kù)或在自己的專用數(shù)據(jù)庫(kù),repmgr元數(shù)據(jù)的schema不能駐留在不屬于Repmgr管理的復(fù)制集群的數(shù)據(jù)庫(kù)服務(wù)器上。
——
Repmgr本身不支持虛擬IP的功能 ,我們可以借助keepalived來(lái)實(shí)現(xiàn)虛擬IP的功能。另外在配置文件中,也可以設(shè)置promote_command為一個(gè)自定義腳本
2.Repmgr如何仲裁哪臺(tái)備機(jī)升主
- 每個(gè)備機(jī)檢查到主機(jī)數(shù)據(jù)庫(kù)故障后會(huì)進(jìn)行重試,重試最后一次后,會(huì)去詢問(wèn)其他備用數(shù)據(jù)庫(kù)。如果其它備用節(jié)點(diǎn)的最后一個(gè)復(fù)制的LSN或與主節(jié)點(diǎn)的最后一次通信的時(shí)間比當(dāng)前節(jié)點(diǎn)的最后一個(gè)復(fù)制的LSN或最后一次通信的時(shí)間更近,則該節(jié)點(diǎn)不執(zhí)行任何操作,并等待與主節(jié)點(diǎn)的通信恢復(fù)。
- 如果所有備機(jī)數(shù)據(jù)庫(kù)節(jié)點(diǎn)都看不到主庫(kù),則它們將檢查witness見(jiàn)證節(jié)點(diǎn)是否可用。如果也無(wú)法到達(dá)witness見(jiàn)證節(jié)點(diǎn),則備機(jī)會(huì)假定主服務(wù)器端發(fā)生網(wǎng)絡(luò)中斷,因此不會(huì)繼續(xù)選擇新的主服務(wù)器。如果可以到達(dá)witness見(jiàn)證節(jié)點(diǎn),則備機(jī)節(jié)點(diǎn)會(huì)假定主服務(wù)器已關(guān)閉,然后繼續(xù)選擇主節(jié)點(diǎn)。之后將升級(jí)配置為“首選”主節(jié)點(diǎn)的節(jié)點(diǎn)。每個(gè)備機(jī)數(shù)據(jù)庫(kù)節(jié)點(diǎn)將重新初始化其復(fù)制,以跟隨新的主數(shù)據(jù)庫(kù)。
Repmgr怎么選主: 當(dāng)需要failover時(shí),repmgr選舉候選備節(jié)點(diǎn)會(huì)以以下順序選舉:LSN > Priority > Node_ID。若LSN一樣,會(huì)根據(jù)priority優(yōu)先級(jí)進(jìn)行比較,該優(yōu)先級(jí)是在配置文件中進(jìn)行參數(shù)配置,將priority設(shè)置為0會(huì)禁止參與選主。若優(yōu)先級(jí)也一樣,會(huì)比較節(jié)點(diǎn)的Node ID,小者會(huì)優(yōu)先選舉
3.Repmgr如何處理腦裂場(chǎng)景(位置參數(shù)、witness見(jiàn)證節(jié)點(diǎn))
(1)位置參數(shù)
Repmgr使用location位置參數(shù)處理腦裂場(chǎng)景,其中每個(gè)節(jié)點(diǎn)應(yīng)根據(jù)其所在的數(shù)據(jù)中心指定位置參數(shù)。在任何網(wǎng)絡(luò)分裂的情況下,Repmgr將確保與主節(jié)點(diǎn)位于同一位置的節(jié)點(diǎn)的提升。如果它在該位置找不到任何節(jié)點(diǎn),它將不會(huì)提升任何位置的任何節(jié)點(diǎn)。
location='location1' # 定義location
除此之外可以使用witness見(jiàn)證服務(wù)器的額外節(jié)點(diǎn)處理網(wǎng)絡(luò)隔離,避免產(chǎn)生腦裂。
(2)見(jiàn)證節(jié)點(diǎn)
witness見(jiàn)證節(jié)點(diǎn)重要用來(lái)處理集群主庫(kù)和備庫(kù)之間可能存在網(wǎng)絡(luò)擁塞、延遲、路由等問(wèn)題影響,導(dǎo)致主庫(kù)還在正常工作,而備庫(kù)無(wú)法聯(lián)系主庫(kù)的場(chǎng)景。通過(guò)設(shè)置witness節(jié)點(diǎn)可以針對(duì)主庫(kù)與備庫(kù)之間切換的檢查完整性,即輔助備節(jié)點(diǎn)進(jìn)行監(jiān)控,避免因網(wǎng)絡(luò)問(wèn)題導(dǎo)致的腦裂現(xiàn)象。
見(jiàn)證節(jié)點(diǎn)主要的工作是幫助備庫(kù)達(dá)到法定的數(shù)量。它是一個(gè)僅考慮多數(shù)票數(shù)的節(jié)點(diǎn)。該服務(wù)器上不需要安裝PostgreSQL,因此在復(fù)制中沒(méi)有任何作用。
當(dāng)備機(jī)連不上主機(jī)了,就會(huì)連接witness見(jiàn)證節(jié)點(diǎn),如果也連接不上見(jiàn)證節(jié)點(diǎn),那判斷自己網(wǎng)絡(luò)故障了,如果能連上見(jiàn)證節(jié)點(diǎn),則認(rèn)為主機(jī)故障,見(jiàn)證節(jié)點(diǎn)的作用類似于一個(gè)信任的網(wǎng)關(guān)。
witness必須配合Repmgrd。 Remgrd啟動(dòng)后會(huì)作為常規(guī)服務(wù)運(yùn)行并持續(xù)監(jiān)視集群的運(yùn)行狀況。當(dāng)達(dá)到與主機(jī)數(shù)據(jù)庫(kù)失去聯(lián)系的法定人數(shù)時(shí),它將啟動(dòng)故障轉(zhuǎn)移。它不僅可以自動(dòng)升級(jí)備用數(shù)據(jù)庫(kù),還可以在多節(jié)點(diǎn)群集中重新啟動(dòng)其他備用數(shù)據(jù)庫(kù)以跟隨新的主數(shù)據(jù)庫(kù)。
4.Repmgr優(yōu)缺點(diǎn)
(1)repmgr 優(yōu)點(diǎn)
- Repmgr 提供了幫助設(shè)置主節(jié)點(diǎn)和備用節(jié)點(diǎn)以及配置復(fù)制的實(shí)用程序。
- 不使用任何額外的端口進(jìn)行通信。如果想執(zhí)行切換,那么它才需要配置無(wú)密碼SSH。
- 通過(guò)調(diào)用已注冊(cè)事件的用戶腳本來(lái)提供通知。
- 在主服務(wù)器發(fā)生故障時(shí)可以執(zhí)行自動(dòng)故障轉(zhuǎn)移。
- 對(duì)數(shù)據(jù)庫(kù)侵入小,維護(hù)起來(lái)和正常主備流復(fù)制基本一致。
- 配置簡(jiǎn)單。
(2)repmgr 缺點(diǎn)
- repmgr 不會(huì)檢測(cè)備用庫(kù)是否在恢復(fù)配置中使用未知或不存在的節(jié)點(diǎn)錯(cuò)誤配置。即使節(jié)點(diǎn)在未連接到主/級(jí)聯(lián)備用節(jié)點(diǎn)的情況下運(yùn)行,節(jié)點(diǎn)也會(huì)顯示為備用節(jié)點(diǎn)。
- 無(wú)法從 PostgreSQL 服務(wù)關(guān)閉的節(jié)點(diǎn)檢索另一個(gè)節(jié)點(diǎn)的狀態(tài)。因此,它不提供分布式控制解決方案。
- 它不能在備機(jī)單個(gè)節(jié)點(diǎn)down掉時(shí),自動(dòng)把其拉起。
二、Patroni
1.Patroni特點(diǎn)
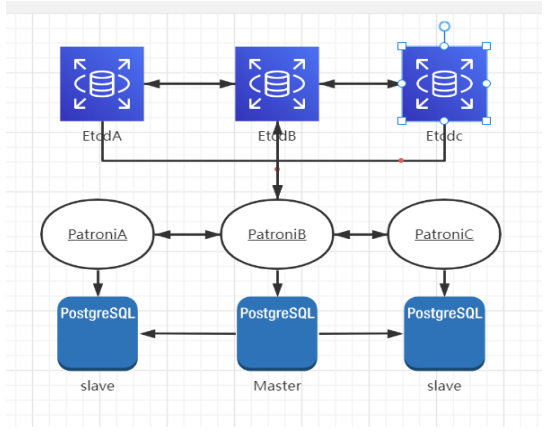
Patroni起源于 Compose 的一個(gè)項(xiàng)目Governor 的一個(gè)分支。它是一個(gè)用 Python 編寫的開源工具套件,用于管理 PostgreSQL 集群的高可用性。Patroni 沒(méi)有構(gòu)建自己的一致性協(xié)議,而是利用了分布式配置存儲(chǔ)(DCS) 提供的一致性模型 ,如 Zookeeper、etcd、Consul 和 Kubernetes等。下文主要以ETCD作為DCS舉例來(lái)說(shuō)明:
etcd可以進(jìn)行心跳檢測(cè)(etcd 之間的心態(tài)檢測(cè))、存儲(chǔ)并在各個(gè)節(jié)點(diǎn)上同步鍵值信息。etcd最少需要三個(gè)節(jié)點(diǎn)且為奇數(shù)來(lái)進(jìn)行 leader 選舉(腦裂發(fā)生時(shí) etcd 集群會(huì)僵死等待恢復(fù),不會(huì)發(fā)生都認(rèn)為自己是主的情況)。
Patroni通過(guò)一個(gè)api接口連接到etcd(或者其他DCS),向其插入鍵值對(duì)記錄patroni參數(shù)、數(shù)據(jù)庫(kù)參數(shù)、主備信息以及連接信息,平常通過(guò)etcd對(duì)其它節(jié)點(diǎn)做心跳檢測(cè),通過(guò)從etcd獲取數(shù)據(jù)對(duì)中存儲(chǔ)的主備信息來(lái)判斷各節(jié)點(diǎn)的狀態(tài)對(duì)集群進(jìn)行自動(dòng)管理
Patroni 確保 PostgreSQL HA 集群的端到端設(shè)置,包括流復(fù)制。它支持創(chuàng)建備用節(jié)點(diǎn)的各種方式,并且可以根據(jù)您的需要定制模板。 Patroni 借助回調(diào)可以支持事件通知,回調(diào)是由某些操作觸發(fā)的腳本。它使用戶能夠通過(guò)提供暫停/恢復(fù)功能來(lái)執(zhí)行任何維護(hù)操作。watchdog支持功能使框架更加健壯。
2.DCS(分布式配置存儲(chǔ)) Zookeeper vs etcd vs Consul
Zookeeper
Zookeeper帶來(lái)的主要優(yōu)勢(shì)是它的成熟度,健壯性和功能豐富性。 但是,它也有其自身的一系列缺點(diǎn),其中Java和復(fù)雜性是主要原因。 Zookeeper對(duì)Java的使用以及相當(dāng)數(shù)量的依賴關(guān)系使它比同等競(jìng)爭(zhēng)產(chǎn)品消耗更多的資源。 除此之外,Zookeeper也很復(fù)雜。 維護(hù)成本比較高。 功能豐富性很高,但是很多復(fù)雜的功能可能不會(huì)使用到。
etcd
etcd是可通過(guò)HTTP訪問(wèn)的鍵/值存儲(chǔ)。 它是分布式的,具有可用于構(gòu)建服務(wù)發(fā)現(xiàn)的分層配置系統(tǒng)。 它非常易于部署,設(shè)置和使用,可提供可靠的數(shù)據(jù)持久性,安全性并具有非常好的文檔。etcd的簡(jiǎn)單性比Zookeeper更好。 但是,必須先將其與少量第三方工具結(jié)合使用,然后才能實(shí)現(xiàn)服務(wù)發(fā)現(xiàn)目標(biāo)。
Consul
Consul是一個(gè)高度一致的數(shù)據(jù)存儲(chǔ),它形成了一個(gè)動(dòng)態(tài)集群。 具有分層的鍵/值存儲(chǔ),該鍵/值存儲(chǔ)不僅可以用于存儲(chǔ)數(shù)據(jù),還可以注冊(cè)服務(wù),這些服務(wù)可以用于各種任務(wù),從發(fā)送有關(guān)數(shù)據(jù)更改的通知到根據(jù)其輸出運(yùn)行運(yùn)行狀況檢查和自定義命令。與Zookeeper和etcd不同,Consul實(shí)現(xiàn)了嵌入式服務(wù)發(fā)現(xiàn)系統(tǒng),因此無(wú)需構(gòu)建自己的系統(tǒng)或使用第三方系統(tǒng)。 除其他事項(xiàng)外,該發(fā)現(xiàn)還包括對(duì)節(jié)點(diǎn)和在它們之上運(yùn)行的服務(wù)的運(yùn)行狀況檢查。
ZooKeeper和etcd僅提供原始的K/V存儲(chǔ),并要求應(yīng)用程序開發(fā)人員構(gòu)建自己的系統(tǒng)來(lái)提供服務(wù)發(fā)現(xiàn)。 另一方面,Consul提供了用于服務(wù)發(fā)現(xiàn)的內(nèi)置框架。 客戶端只需要注冊(cè)服務(wù)并使用DNS或HTTP接口執(zhí)行發(fā)現(xiàn)。 其他兩個(gè)工具需要手工解決方案或使用第三方工具。Consul為多個(gè)數(shù)據(jù)中心提供了開箱即用的本機(jī)支持,該系統(tǒng)不僅可以在同一集群中的節(jié)點(diǎn)之間工作,而且還可以跨數(shù)據(jù)中心工作。
3.Patroni如何仲裁哪臺(tái)備機(jī)升主
Patroni監(jiān)控本地的PostgreSQL狀態(tài),并將相關(guān)信息寫入etcd,每個(gè)Patroni都能讀寫etcd上的key,從而獲取外地PostgreSQL數(shù)據(jù)庫(kù)信息。當(dāng)etcd的leader節(jié)點(diǎn)不可用時(shí),etcd會(huì)一致性的選擇一個(gè)合適的節(jié)點(diǎn)作為主節(jié)點(diǎn),新的etcd主節(jié)點(diǎn)將獲取leader key。
etcd怎么選主:假設(shè)etcd有三個(gè)節(jié)點(diǎn),三個(gè)節(jié)點(diǎn)都去創(chuàng)建一個(gè)全局的唯一key,誰(shuí)先創(chuàng)建成功誰(shuí)就是master主節(jié)點(diǎn)。其他節(jié)點(diǎn)持續(xù)待命繼續(xù)獲取,主節(jié)點(diǎn)繼續(xù)續(xù)租key值(key值會(huì)過(guò)期)。當(dāng)持有key的節(jié)點(diǎn)down機(jī)時(shí),或者key值過(guò)期被刪,其他節(jié)點(diǎn)創(chuàng)建key成功,則新master主節(jié)點(diǎn)產(chǎn)生,其他節(jié)點(diǎn)繼續(xù)這樣待命持續(xù)獲取key的狀態(tài)。
- Patroni 自動(dòng)創(chuàng)建主備流復(fù)制集群通過(guò) api 接口往 etcd 記錄鍵值來(lái)儲(chǔ)存主備信息與連接
信息以及配置信息,而Etcd 進(jìn)行心跳檢測(cè)(etcd 之間的心態(tài)檢測(cè))與存儲(chǔ)鍵值信息 - Patroni 通過(guò)連接 etcd 對(duì)其它節(jié)點(diǎn)做心跳檢測(cè),每 loop_wait 秒一次
- Patroni 通過(guò)連接到 etcd 集群,向其插入鍵值記錄 patroni 參數(shù)、數(shù)據(jù)庫(kù)參數(shù)、主備信息以及連接信息。通過(guò)向 etcd 拿取鍵值中儲(chǔ)存的主備信息來(lái)判斷各節(jié)點(diǎn)的狀態(tài)來(lái)切換。各節(jié)點(diǎn)會(huì)在 data 目錄下生成 recovery.done(與 recovery.conf一樣,里面的 primary_conninfo 記錄是上一次主節(jié)點(diǎn)的連接信息),原主節(jié)點(diǎn)發(fā)生切換時(shí)自動(dòng)改變后綴為 recovery.conf,原備節(jié)點(diǎn)會(huì)刪除掉自身的recovery.conf 文件,再通過(guò) pg_rewind 來(lái)快速恢復(fù)節(jié)點(diǎn),不需要做bacebackup基礎(chǔ)備份。
- 異步流復(fù)制時(shí)主從之間延時(shí):主從之間 wal 日志延時(shí)超過(guò)
maximum_lag_on_failover(byte)的大小,主備有可能會(huì)重啟但不會(huì)發(fā)生切換。
數(shù)據(jù)丟失量通過(guò) maximum_lag_on_failover,ttl,loop_wait 三個(gè)參數(shù)控制。
最壞的情況下的丟失量:maximum_lag_on_failover 字節(jié)+最后的 TTL 秒時(shí)間內(nèi)寫入的日志量(loop_wait /2 在平均情況下)。 - haproxy+keeplived 保持對(duì)外的訪問(wèn) ip 端口不變
4.Patroni如何處理腦裂場(chǎng)景(watchdog)
正常停止Patroni時(shí),Patroni會(huì)順便把本機(jī)的PG進(jìn)程也停掉。然而,當(dāng)Patroni進(jìn)程自身沒(méi)法正常工作時(shí),以上的保護(hù)措施難以成功。例如Patroni進(jìn)程異常終止或主機(jī)臨時(shí)hang住等。
為了更可靠的防止腦裂,Patroni支持經(jīng)過(guò)Linux的watchdog監(jiān)視patroni進(jìn)程的運(yùn)行,當(dāng)Patroni進(jìn)程沒(méi)法正常往watchdog設(shè)備寫入心跳時(shí),由watchdog觸發(fā)Linux重啟。
使用watchdog防止出現(xiàn)腦裂,如果Leader節(jié)點(diǎn)異常導(dǎo)致Patroni進(jìn)程無(wú)法及時(shí)更新watchdog,會(huì)在Leader key過(guò)期的前5秒觸發(fā)重啟。重啟如果在5秒之內(nèi)完成,Leader節(jié)點(diǎn)有機(jī)會(huì)再次獲得Leader鎖,否則Leader key過(guò)期后,由備庫(kù)通過(guò)選舉選出新的Leader。
Patroni會(huì)在將PostgreSQL提升為master之前嘗試激活watchdog。
如果看atchdog激活失敗并且watchdog模式是required那么節(jié)點(diǎn)將拒絕成為主節(jié)點(diǎn)。
在決定參加leader選舉時(shí),Patroni還將檢查watchdog配置是否允許它成為領(lǐng)導(dǎo)者。
在將PostgreSQL降級(jí)后(例如由于手動(dòng)故障轉(zhuǎn)移),Patroni將再次禁用watchdog。當(dāng) Patroni處于暫停狀態(tài)時(shí),watchdog也將被禁用。正常停止Patroni服務(wù),也會(huì)將watchdog禁用。
5.Patroni優(yōu)缺點(diǎn)
(1)Patroni優(yōu)點(diǎn)
- Patroni 支持集群的端到端設(shè)置。
- 支持 REST API 和 HAproxy 集成。
- 通過(guò)某些操作觸發(fā)的回調(diào)腳本支持事件通知。
- 利用 DCS 選取主節(jié)點(diǎn)。
- 支持自動(dòng)failover和按需switchover
- 支持同步復(fù)制下備庫(kù)故障時(shí)自動(dòng)降級(jí)為異步復(fù)制(功效相似于MySQL的半同步,可是更加智能)
- 支持控制指定節(jié)點(diǎn)是否參與選主,是否參與負(fù)載均衡以及是否能夠成為同步備機(jī)
- 支持經(jīng)過(guò)pg_rewind自動(dòng)修復(fù)舊主。
- 支持多種方式初始化集群和重建備機(jī),包括pg_basebackup和支持pgBackRest,barman等備份工具的自定義腳本
- 支持自定義外部callback腳本
- 支持REST API
- 支持經(jīng)過(guò)watchdog防止腦裂
- 支持k8s,docker等容器化環(huán)境部署
- 支持多種常見(jiàn)DCS存儲(chǔ)元數(shù)據(jù),包括etcd,ZooKeeper,Consul,Kubernetes等
除此之外,Patroni在目前支持的 邏輯復(fù)制槽的自動(dòng)failover 這一功能,在PostgreSQL的高可用方案里,是比較方便且獨(dú)樹一幟的。所以,如果可用服務(wù)器在至少3臺(tái)或者有邏輯復(fù)制需求的時(shí)候,Patroni是一款很值得推薦的PostgreSQL高可用工具,但是這個(gè)最少節(jié)點(diǎn)的限制也是其中一個(gè)缺點(diǎn)。
(2)Patroni缺點(diǎn)
- Patroni 不會(huì)檢測(cè)到在恢復(fù)配置中具有未知或不存在節(jié)點(diǎn)的備用的錯(cuò)誤配置。即使備節(jié)點(diǎn)在未連接到主/級(jí)聯(lián)備用節(jié)點(diǎn)的情況下運(yùn)行,該節(jié)點(diǎn)也將顯示為從節(jié)點(diǎn)。
- 用戶需要處理 DCS 軟件的設(shè)置、管理和升級(jí)。和原本運(yùn)維主備流復(fù)制環(huán)境差異較大。對(duì)數(shù)據(jù)庫(kù)的侵入較大。
- 需要為組件通信打開多個(gè)端口:
- Patroni 的 REST API 端口
- DCS 最少 2 個(gè)端口
三、Patroni和Repmgr相關(guān)場(chǎng)景對(duì)比
1.備機(jī)測(cè)試
| 場(chǎng)景 | Repmgr | Patroni |
|---|---|---|
| kill PostgreSQL 進(jìn)程 | 需要手動(dòng)干預(yù)才能再次啟動(dòng)PostgreSQL 進(jìn)程。 | Patroni 使 PostgreSQL 進(jìn)程回到運(yùn)行狀態(tài)。 |
| 正常停止 PostgreSQL 進(jìn)程 | 需要手動(dòng)干預(yù)才能再次啟動(dòng)PostgreSQL 進(jìn)程。 | Patroni 使 PostgreSQL 進(jìn)程回到運(yùn)行狀態(tài)。 |
| 重啟服務(wù)器 | 需要手動(dòng)啟動(dòng)PostgreSQL,并將服務(wù)器標(biāo)記為正在運(yùn)行。 | Patroni會(huì)在在重啟及服務(wù)器后啟動(dòng),除非配置為在重新啟動(dòng)時(shí)不啟動(dòng)。一旦 Patroni 啟動(dòng),它就會(huì)啟動(dòng) PostgreSQL 進(jìn)程并設(shè)置備機(jī)配置。 |
| 正常停止repmgrd或Patroni | 備機(jī)的不會(huì)成為自動(dòng)故障轉(zhuǎn)移的一個(gè)節(jié)點(diǎn),(備機(jī)狀態(tài)無(wú)變化) | Patroni會(huì)停止備機(jī)PostgreSQL進(jìn)程 |
2.主機(jī)測(cè)試
| 場(chǎng)景 | Repmgr | Patroni |
|---|---|---|
| kill PostgreSQL 進(jìn)程 | Repmgrd在固定的時(shí)間間隔內(nèi),所有備機(jī)都會(huì)對(duì)主節(jié)點(diǎn)連接進(jìn)行健康檢查。當(dāng)所有重試都失敗時(shí),在所有備機(jī)上觸發(fā)選舉。作為選舉的結(jié)果,具有最新收到的 LSN 的備用被提升。失去選舉的備用服務(wù)器將等待來(lái)自新主節(jié)點(diǎn)的通知,并在收到通知后跟隨它。原主節(jié)點(diǎn)需要手動(dòng)干預(yù)才能再次啟動(dòng) postgreSQL 進(jìn)程。 | Patroni 使 PostgreSQL 進(jìn)程回到運(yùn)行狀態(tài)。在該節(jié)點(diǎn)上運(yùn)行的 Patroni 具有主鎖,因此沒(méi)有觸發(fā)選舉。 |
| 正常停止 PostgreSQL進(jìn)程并在健康檢查到期前立即將其恢復(fù) | Repmgrd在固定的時(shí)間間隔內(nèi),所有備機(jī)都會(huì)對(duì)主節(jié)點(diǎn)連接進(jìn)行健康檢查。當(dāng)所有重試都失敗時(shí),在所有備機(jī)上觸發(fā)選舉。然而,新當(dāng)選的主節(jié)點(diǎn)沒(méi)有通知現(xiàn)有的備機(jī),因?yàn)榕f的主節(jié)點(diǎn)回來(lái)了。群集處于不確定狀態(tài),需要人工干預(yù)。 | Patroni 使 PostgreSQL 進(jìn)程回到運(yùn)行狀態(tài)。在該節(jié)點(diǎn)上運(yùn)行的 Patroni 具有主鎖,因此沒(méi)有觸發(fā)選舉。 |
| 重啟服務(wù)器 | 當(dāng)所有備機(jī)上與主的連接健康檢查失敗時(shí),remgrd 開始選舉。符合條件的備機(jī)被提升為新主。當(dāng)原主回來(lái)時(shí),它沒(méi)有加入集群并被標(biāo)記為失敗。需要運(yùn)行 repmgr node rejoin 命令將服務(wù)器添加回集群。 | 發(fā)生故障轉(zhuǎn)移,其中一臺(tái)備機(jī)在獲得鎖后被選為新的主節(jié)點(diǎn)。當(dāng)Patroni在舊主機(jī)點(diǎn)上啟動(dòng)時(shí),它會(huì)拉起原主的PostgreSQL進(jìn)程并執(zhí)行pg_rewind,并、且開始跟隨新主節(jié)點(diǎn)。 |
| 正常停止repmgrd或Patroni | 主節(jié)點(diǎn)不會(huì)成為自動(dòng)故障轉(zhuǎn)移的一部分。PostgreSQL 服務(wù)正常運(yùn)行。啟動(dòng)Repmgrd,PostgreSQL進(jìn)程不自動(dòng)拉起。 | Patroni所在的其中一臺(tái)備機(jī)獲得了 DCS 鎖并提升自身成為主庫(kù)。舊主的PostgreSQL被Patroni關(guān)掉,一旦在舊主機(jī)上啟動(dòng)了 Patroni,它會(huì)將舊主的時(shí)間線和 lsn(use_pg_rewind設(shè)置為 true)調(diào)整到與新主一致并開始跟隨新主。 |
