




說(shuō) 明:源端 Oracle 數(shù)據(jù)庫(kù)版本 19c, ogg 19.1 源端也可以是 11.2.0.4 db,ogg 版本 12.3.0.1.2
目標(biāo)端:Kafka 版本 kafka_2.11-2.0.0, JDK1.8, ogg for bigdata 12.3.2.1.1
--源端 version
Oracle GoldenGate Command Interpreter for Oracle
Version 19.1.0.0.4 OGGCORE_19.1.0.0.0_PLATFORMS_191017.1054_FBO
Linux, x64, 64bit (optimized), Oracle 19c on Oct 17 2019 21:16:29
Operating system character set identified as US-ASCII.
Copyright (C) 1995, 2019, Oracle and/or its affiliates. All rights reserved.
--目標(biāo)端 version
Oracle GoldenGate for Big Data Version 12.3.2.1.1 (Build 005) 依賴 jdk 1.8 及以上版本,故需安裝 JDK
Oracle GoldenGate for Big Data
Version 12.3.2.1.1 (Build 005)
支持的 Kafka 版本

OGG 12.3.2.1 已停止支持 Kafka 版本 0.8.2.2、0.8.2.1 和 0.8.2.0。這允許在 Kafka 生產(chǎn)者上執(zhí)行刷新調(diào)用,從而為流控制和檢查點(diǎn)提供更好的支持。
一、安裝 ogg
源端 ogg 安裝和普通 ogg 安裝一樣,這里不在介紹,如果有需要請(qǐng)點(diǎn)擊鏈接查看前面文章說(shuō)明。目標(biāo)端 ogg 有所區(qū)別,一定要下載安裝 Oracle GoldenGate for Big Data 相關(guān)版本,官網(wǎng)已經(jīng)看不到 12.3.2.1 的版本了,不過(guò)也可以下載 19.1 或者 21.3 版本的 OGG for bigdata,當(dāng)然也可以到 http://edelivery.oracle.com 網(wǎng)站去下載歷史版本。
安裝 JDK1.8
Oracle GoldenGate for Big Data 已通過(guò) Java 1.8 認(rèn)證。在安裝和運(yùn)行 Oracle GoldenGate for Big Data 之前,您必須安裝 Java(JDK 或 JRE)1.8 或更高版本。可以使用 Java 運(yùn)行時(shí)環(huán)境 (JRE) 或完整的 Java 開(kāi)發(fā)工具包(包括 JRE)。
export JAVA_HOME=/opt/jdk1.8
export PATH=$JAVA_HOME/bin:$PATH
export LD_LIBRARY_PATH=$JAVA_HOME/jre/lib/i386/server:$LD_LIBRARY_PATH
在上面的示例中,目錄 $JAVA_HOME/jre/lib/i386/server 應(yīng)該包含 libjvm.so 和 libjsig.so 文件。包含 JVM 庫(kù)的實(shí)際目錄取決于操作系統(tǒng)以及是否使用 64 位 JVM。
上傳軟件包
OGG_BigData_Linux_x64_12.3.2.1.1.zip,java.tar.gz,kafka_2.11-2.0.0 文章中所涉及到的 12.3 的 OGG 相關(guān)軟件,如有需要可在公眾號(hào)后臺(tái)回復(fù)【OGG12.3】獲取。
unzip OGG_BigData_Linux_x64_12.3.2.1.1.zip
tar -xvf OGG_BigData_Linux_x64_12.3.2.1.1.tar
./ggsci
./ggsci: error while loading shared libraries: libjvm.so: cannot open shared object file: No such file or directory
--ggsci 報(bào)錯(cuò),提示找不到 libjvm.so 文件,需要安裝配置 java 路徑,前期的 OGG 版本暫時(shí)還未集成 java 需要單獨(dú)安裝。
安裝 java 配置環(huán)境變量
cd /home/oracle/java1.8
tar -xvf java.tar.gz
tree -L 2 java
java
`-- jdk1.8.0_181
|-- bin
|-- COPYRIGHT
|-- include
|-- javafx-src.zip
|-- jre
|-- lib
|-- LICENSE
|-- man
|-- README.html
|-- release
|-- src.zip
|-- THIRDPARTYLICENSEREADME-JAVAFX.txt
`-- THIRDPARTYLICENSEREADME.txt
--配置環(huán)境變量
vi .bash_profile
export JAVA_HOME=/home/oracle/java1.8/java/jdk1.8.0_181/
export PATH=$JAVA_HOME/bin:$PATH
export LD_LIBRARY_PATH=$JAVA_HOME/jre/lib/amd64/server:$LD_LIBRARY_PATH
source .bash_profile
啟動(dòng)目標(biāo)端 ogg
Oracle GoldenGate for Big Data
Version 12.3.2.1.1 (Build 005)
Oracle GoldenGate Command Interpreter
Version 12.3.0.1.2 OGGCORE_OGGADP.12.3.0.1.2_PLATFORMS_180712.2305
Linux, x64, 64bit (optimized), Generic on Jul 13 2018 00:46:09
Operating system character set identified as US-ASCII.
Copyright (C) 1995, 2018, Oracle and/or its affiliates. All rights reserved.
Shell> ./ggsci
GGSCI> CREATE SUBDIRS
-- 編輯 MGR 配置文件
GGSCI> EDIT PARAM MGR
PORT 7809
DYNAMICPORTLIST 7810-7829
AUTORESTART EXTRACT *,RETRIES 5,WAITMINUTES 3
PURGEOLDEXTRACTS ./dirdat/*,usecheckpoints, minkeepdays 30
GGSCI>START MGR
GGSCI>INFO MGR
二、配置 ogg
源端配置 ogg
--MGR 參數(shù)如下
view params mgr
PORT 7809
DYNAMICPORTLIST 7710-7729
AUTOSTART EXTRACT *
PURGEOLDEXTRACTS /ogg19c/dirdat/*,usecheckpoints, minkeepdays 15
Lagcriticalminutes 60
ACCESSRULE, PROG *, IPADDR 192.*.*.*, ALLOW
start mgr
配置捕獲投遞進(jìn)程
add extract ext1, TRANLOG, BEGIN NOW, THREADS 2
add exttrail /ogg19c/dirdat/dw, extract ext1, megabytes 100
edit params ext1
extract ext1
setenv (NLS_LANG="AMERICAN_AMERICA.AL32UTF8")
userid ogg@DW, password ogg
--USERIDALIAS alias_ogg
TRANLOGOPTIONS DBLOGREADER
exttrail /ogg19c/dirdat/dw ,FORMAT RELEASE 12.2
discardfile /ogg19c/dirrpt/ext1.dsc, append, MEGABYTES 1024
--DDL EXCLUDE ALL
statoptions reportfetch
reportrollover at 08:30
GETUPDATEBEFORES
NOCOMPRESSDELETES
NOCOMPRESSUPDATES
TABLE ODSOR.T_MON_DOCDATUM;
--TABLE PDB.Schema.table;
start ext1
.......
--集成模式需要先注冊(cè)進(jìn)程到數(shù)據(jù)庫(kù),不然啟動(dòng)會(huì)報(bào)錯(cuò) OGG-02022 Logmining server does not exist on this Oracle database
dblogin userid ogg@TEST, password ogg
dblogin userid c##ogg@EDW password ogg
unregister extract ext1 database
register extract ext1 database
register extract ext1 database CONTAINER (SPRINTPDB1) --PDB模式
add extract ext1, INTEGRATED TRANLOG, BEGIN NOW
add exttrail /ogg19c/dirdat/ss, extract ext1, megabytes 1024
注意的兩點(diǎn):1.“FORMAT RELEASE 12.2” 指定 trail 文件格式的版本,可選的版本有
values (10.4|11.1|11.2|12.1|12.2|12.3|18.1|19.1) for [release]
但是,當(dāng)數(shù)據(jù)庫(kù)為 19c OGG 為 19.1 時(shí)只能選擇最低版本為 12.2,不能選擇 11.2,在 11g 數(shù)據(jù)庫(kù)和 OGG 12.3 中可以選擇 11.2。
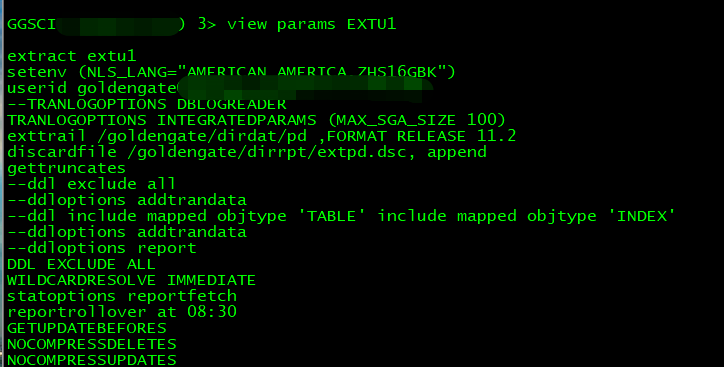
2.從 Oracle 同步數(shù)據(jù)到 Kafka 時(shí)不支持 DDL,故源端 DDL 變更不會(huì)同步到目標(biāo)端,也不需要配置 DDL 相關(guān)捕獲,DDL 相關(guān)參數(shù)也不需要配置。
Only the TRUNCATE TABLE DDL statement is supported. All other DDL statements are ignored.
You can use the TRUNCATE statements one of these ways:
In a DDL statement, TRUNCATE TABLE, ALTER TABLE TRUNCATE PARTITION, and other DDL TRUNCATE statements. This uses the DDL parameter.
Standalone TRUNCATE support, which just has TRUNCATE TABLE. This uses the GETTRUNCATES parameter.
注意:只支持 TRUNCATE TABLE DDL 語(yǔ)句。所有其他 DDL 語(yǔ)句將被忽略。
使用 TRUNCATE 語(yǔ)句的方式如下:
在 DDL 語(yǔ)句中,TRUNCATE TABLE, ALTER TABLE TRUNCATE PARTITION,以及其他 DDL TRUNCATE 語(yǔ)句。
獨(dú)立的 TRUNCATE 支持,它只有 TRUNCATE TABLE。它使用 GETTRUNCATES 參數(shù)。
添加投遞進(jìn)程
add extract dpe1, exttrailsource /ogg19c/dirdat/dw
add rmttrail /soft/dirdat/dw, EXTRACT dpe1, MEGABYTES 1024
edit params dpe1
extract dpe1
setenv (NLS_LANG="AMERICAN_AMERICA.AL32UTF8")
rmthost 192.168.27.15,mgrport 7809,compress
rmttrail /soft/dirdat/dw,format release 12.2
--dynamicresolution
passthru
numfiles 3000
TABLE ODSOR.T_MON_DOCDATUM;
start dpe1
.......
然后需要對(duì)同步的表添加補(bǔ)充日志,一般通過(guò)登錄 OGG 添加即可,不過(guò),業(yè)務(wù)對(duì)于 Kafka 端的要求開(kāi)啟全部列的補(bǔ)充日志。
add trandata ODSOR.T_MON_DOCDATUM
info trandata ODSOR.T_MON_DOCDATUM
--使用 SQL 命令手動(dòng)添加主鍵補(bǔ)全日志
alter table ODSOR.T_MON_DOCDATUM add supplemental log data (primary key) columns;
--使用 SQL 命令手動(dòng)添加所有列補(bǔ)全日志,在日志中補(bǔ)全所有字段(排除 LOB 和 LONG 類型)
alter table ODSOR.T_MON_DOCDATUM add supplemental log data (all) columns;
--使用 SQL 命令手動(dòng)刪除補(bǔ)全日志
alter table ODSOR.T_MON_DOCDATUM drop supplemental log data (all) columns;
---關(guān)閉補(bǔ)全日志
alter database drop supplemental log data (primary key,unique index) columns;
---重新開(kāi)啟補(bǔ)全日志
alter database add supplemental log data (primary key,unique index) columns;
goldengate.def 表結(jié)構(gòu)定義文件
在 ogg for bigdata 以前的版本中,需要表結(jié)構(gòu)定義文件,利用 DEFGEN 工具可以為源端和目標(biāo)端表生成數(shù)據(jù)定義文件,當(dāng)源庫(kù)和目標(biāo)庫(kù)類型不一致時(shí),或源端的表和目標(biāo)端的表結(jié)構(gòu)不一致時(shí),數(shù)據(jù)定義文件時(shí)必須要有的。
一般生成數(shù)據(jù)定義文件的步驟如下:
Step1. 編輯defgen文件
GGSCI> edit param test_ogg
defsfile /goldengate/dirdef/goldengate.def,FORMAT RELEASE 11.2, PURGE
userid ogg,password ogg
TABLE ODSOR.T_MON_DOCDATUM;
Step2. 利用 defgen 工具生成 defgen.prm 文件
/ogg19c/defgen paramfile /ogg19c/dirprm/test_ogg.prm
或者
./defgen paramfile ./dirprm/test_ogg.prm
Step3. 將生成好的數(shù)據(jù)定義文件 scp 二進(jìn)制模式傳輸?shù)侥繕?biāo)端對(duì)應(yīng)的目錄 dirdef
scp /ogg19c/dirdef/goldengate.def oracle@192.168.17.25:/soft/dirdef/goldengate_rep03.def
目標(biāo)端配置 ogg
編輯 rep 復(fù)制進(jìn)程參數(shù)文件
以下官方文檔示例參數(shù)模板:
REPLICAT hdfs
TARGETDB LIBFILE libggjava.so SET property=dirprm/hdfs.properties
--SOURCEDEFS ./dirdef/dbo.def
DDL INCLUDE ALL
GROUPTRANSOPS 1000
MAPEXCLUDE dbo.excludetable
MAP dbo.*, TARGET dbo.*;
以下是對(duì)這些 Replicat 配置條目的解釋:
REPLICAT hdfs --Replicat 進(jìn)程的名稱。
TARGETDB LIBFILE libggjava.so SET property=dirprm/hdfs.properties --在您退出時(shí)設(shè)置目標(biāo)數(shù)據(jù)庫(kù)libggjava.so并將 Java 適配器屬性文件設(shè)置為dirprm/hdfs.properties.
–SOURCEDEFS ./dirdef/dbo.def --設(shè)置源數(shù)據(jù)庫(kù)定義文件。它被注釋掉是因?yàn)?Oracle GoldenGate 跟蹤文件在跟蹤中提供元數(shù)據(jù)。
GROUPTRANSOPS 1000 --將源跟蹤文件中的 1000 個(gè)事務(wù)分組為單個(gè)目標(biāo)事務(wù)。這是默認(rèn)設(shè)置,可提高大數(shù)據(jù)集成的性能。
MAPEXCLUDE dbo.excludetable --設(shè)置要排除的表。
MAP dbo., TARGET dbo.; --設(shè)置輸入到輸出表的映射。
以下是我測(cè)試環(huán)境參數(shù)配置:
REPLICAT rep03
sourcedefs /soft/dirdef/goldengate_rep03.def
TARGETDB LIBFILE libggjava.so SET property=dirprm/kafka_dw.props
REPORTCOUNT EVERY 1 MINUTES, RATE
GROUPTRANSOPS 10000
GETUPDATEBEFORES
HANDLECOLLISIONS
REPLACEBADCHAR SUBSTITUTE ? FORCECHECK
MAP ODSOR.T_MON_DOCDATUM,target ODSOR.T_MON_DOCDATUM;
MAP OPS.T_LABEL_RULE,target OPS.T_LABEL_RULE;
MAP prod.*,target prod.*;
MAPEXCLUDE PROD.T_FILE_NAME;
......
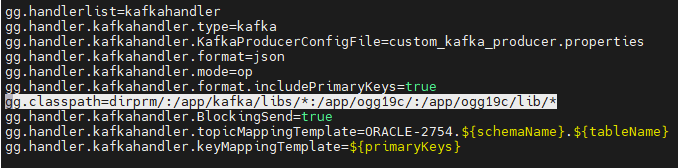
kafka_dw.props 配置文件如下,下游 Kafka 集群安裝配置這里就先不介紹了。

vim /soft/dirprm/kafka_dw.props
gg.handlerlist=kafkahandler
gg.handler.kafkahandler.type=kafka
gg.handler.kafkahandler.KafkaProducerConfigFile=custom_kafka_producer.properties
gg.handler.kafkahandler.format=json
gg.handler.kafkahandler.mode=op
gg.handler.kafkahandler.format.includePrimaryKeys=true
gg.classpath=dirprm/:/home/oracle/kafka/libs/*:/soft/:/soft/lib/*
gg.handler.kafkahandler.BlockingSend=false
#gg.handler.kafkahandler.topicMappingTemplate=ORACLE_JIEKEDB_${schemaName}_${tableName}_${primaryKeys}
#gg.handler.kafkahandler.keyMappingTemplate=ORACLE_JIEKEDB_${schemaName}_${tableName}_${primaryKeys}
gg.handler.kafkahandler.topicMappingTemplate=ORACLE_DW_75.${schemaName}.${tableName}
gg.handler.kafkahandler.keyMappingTemplate=${primaryKeys}

- Blocking Versus Non-Blocking Mode 阻塞模式與非阻塞模式
Kafka處理器可以以阻塞模式(同步)或非阻塞模式(異步)將消息發(fā)送到Kafka。
阻塞模式由 Kafka 處理程序的以下配置屬性設(shè)置:
gg.handler.name.BlockingSend=true
消息以同步方式發(fā)送到Kafka。Kafka處理程序在當(dāng)前消息已寫(xiě)入目標(biāo)主題并收到確認(rèn)之前,不會(huì)發(fā)送下一條消息。阻塞模式雖然會(huì)降低性能,但能最大程度地保證消息傳遞。
在阻塞模式下,絕不能設(shè)置 Kafka 生產(chǎn)者的 linger.ms 變量,因?yàn)檫@會(huì)導(dǎo)致 Kafka 生產(chǎn)者在將消息發(fā)送到 Kafka 代理之前等待整個(gè)超時(shí)周期。當(dāng)這種情況發(fā)生時(shí),Kafka 處理程序正在等待消息已發(fā)送的確認(rèn),而與此同時(shí),Kafka 生產(chǎn)者正在緩沖要發(fā)送到 Kafka 代理的消息。
非阻塞模式由 Kafka 處理程序的以下配置屬性設(shè)置:
gg.handler.name.BlockingSend=false
消息以異步方式發(fā)送到Kafka。Kafka消息逐個(gè)發(fā)布,無(wú)需等待確認(rèn)。Kafka生產(chǎn)者客戶端可能會(huì)緩沖傳入的消息,以提高吞吐量。
在每次事務(wù)提交時(shí),都會(huì)調(diào)用 Kafka 生產(chǎn)者的刷新(flush)方法,以確保所有未處理的消息都被傳輸?shù)?Kafka 集群。這使得 Kafka 處理器能夠安全地進(jìn)行檢查點(diǎn)操作,確保零數(shù)據(jù)丟失。調(diào)用 Kafka 生產(chǎn)者的刷新方法不受 linger.ms 持續(xù)時(shí)間的影響。這使得 Kafka 處理器能夠安全地進(jìn)行檢查點(diǎn)操作,確保零數(shù)據(jù)丟失。
您可以通過(guò)Kafka生產(chǎn)者配置文件中的多個(gè)可配置屬性來(lái)控制Kafka生產(chǎn)者何時(shí)將數(shù)據(jù)刷新到Kafka代理。為了使Kafka生產(chǎn)者能夠批量發(fā)送消息,必須在Kafka生產(chǎn)者配置文件中同時(shí)設(shè)置batch.size和linger.ms這兩個(gè)Kafka生產(chǎn)者屬性。batch.size控制在發(fā)送到Kafka之前要緩沖的最大字節(jié)數(shù),而linger.ms變量控制在發(fā)送數(shù)據(jù)之前要等待的最大毫秒數(shù)。一旦達(dá)到batch.size或linger.ms周期到期(以先到者為準(zhǔn)),就會(huì)將數(shù)據(jù)發(fā)送到Kafka。僅設(shè)置batch.size變量會(huì)導(dǎo)致消息立即發(fā)送到Kafka。
注意:gg.classpath 需要配置 OGG for kafka 的 dirprm 目錄 和庫(kù)文件,還需要配置 ./kafka/libs 庫(kù)文件,不然還會(huì)報(bào)如下錯(cuò)誤。
tar -zxvf kafka.tar.gz
ln -s kafka_2.11-2.0.0/ kafka
vim /soft/dirprm/kafka_dw.props
gg.classpath=dirprm/:/app/kafka/libs/*:/app/ogg19c/:/app/ogg19c/lib/*
SEVERE: org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'userExitDataSource' defined in class path resource [oracle/goldengate/datasource/DataSource-context.xml]: Bean
instantiation via factory method failed; nested exception is org.springframework.beans.BeanInstantiationException: Failed to instantiate [oracle.goldengate.datasource.GGDataSource]: Factory method 'getData
Source' threw exception; nested exception is java.lang.NoClassDefFoundError: org/apache/kafka/clients/producer/Producer
org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'userExitDataSource' defined in class path resource [oracle/goldengate/datasource/DataSource-context.xml]: Bean instant
iation via factory method failed; nested exception is org.springframework.beans.BeanInstantiationException: Failed to instantiate [oracle.goldengate.datasource.GGDataSource]: Factory method 'getDataSource'
threw exception; nested exception is java.lang.NoClassDefFoundError: org/apache/kafka/clients/producer/Producer
at oracle.goldengate.datasource.DataSourceLauncher.<init>(DataSourceLauncher.java:168)
at oracle.goldengate.datasource.UserExitMain.main(UserExitMain.java:124)
Caused by: org.springframework.beans.BeanInstantiationException: Failed to instantiate [oracle.goldengate.datasource.GGDataSource]: Factory method 'getDataSource' threw exception; nested exception is java.l
ang.NoClassDefFoundError: org/apache/kafka/clients/producer/Producer
at org.springframework.beans.factory.support.SimpleInstantiationStrategy.instantiate(SimpleInstantiationStrategy.java:189)
at org.springframework.beans.factory.support.ConstructorResolver.instantiateUsingFactoryMethod(ConstructorResolver.java:588)
... 11 more
Caused by: java.lang.NoClassDefFoundError: org/apache/kafka/clients/producer/Producer
custom_kafka_producer.properties 配置如下:
vim custom_kafka_producer.properties
bootstrap.servers=192.168.217.184:19092,192.168.217.185:19092,192.168.217.186:19092
acks=1
compression.type=gzip
reconnect.backoff.ms=1000
value.serializer=org.apache.kafka.common.serialization.ByteArraySerializer
key.serializer=org.apache.kafka.common.serialization.ByteArraySerializer
batch.size=1048576
linger.ms=0
max.request.size = 50240000
send.buffer.bytes = 50240000
性能考量
Oracle建議,當(dāng)gg.handler.name.BlockingSend=true時(shí),不要在Kafka生產(chǎn)者配置文件中使用linger.ms設(shè)置。這會(huì)導(dǎo)致每次發(fā)送至少阻塞linger.ms時(shí)間,從而引發(fā)嚴(yán)重的性能問(wèn)題,因?yàn)镵afka處理程序配置和Kafka生產(chǎn)者配置相互沖突。此配置會(huì)導(dǎo)致臨時(shí)死鎖情況,即Kafka處理程序在等待發(fā)送確認(rèn),而Kafka生產(chǎn)者在發(fā)送前等待更多消息。一旦linger.ms周期到期,死鎖就會(huì)解除。每次發(fā)送消息時(shí)都會(huì)重復(fù)這種行為。
為獲得最佳性能,Oracle建議您通過(guò)在Java適配器屬性文件中使用以下配置,將Kafka處理程序設(shè)置為使用對(duì)Kafka生產(chǎn)者的非阻塞(異步)調(diào)用以操作模式運(yùn)行:
gg.handler.name.mode = op
gg.handler.name.BlockingSend = false
此外,建議在Kafka生產(chǎn)者屬性文件中設(shè)置batch.size和linger.ms的值。batch.size和linger.ms的設(shè)置值在很大程度上取決于用例場(chǎng)景。通常,較高的值會(huì)帶來(lái)更好的吞吐量,但會(huì)增加延遲。這些屬性的較小值會(huì)降低延遲,但總體吞吐量會(huì)下降。如果源試驗(yàn)文件中有大量輸入數(shù)據(jù),則應(yīng)將batch.size和linger.ms設(shè)置得盡可能高。
使用Replicat變量GROUPTRANSOPS也能提高性能。建議將其設(shè)置為10000。
如果您需要將源跟蹤文件中的序列化操作以單獨(dú)的Kafka消息形式傳遞,那么Kafka處理程序必須設(shè)置為操作模式。
gg.handler.name.mode = op
結(jié)果是產(chǎn)生了更多的Kafka消息,性能也受到了不利影響。

添加 rep 復(fù)制進(jìn)程
添加和啟動(dòng) Replicat 進(jìn)程的命令如下:
GGSCI> add replicat rep03,exttrail /soft/dirdat/dw nodbcheckpoint
GGSCI> START rep03
cat ODSOR.T_MON_DOCDATUM.schema.json
{
"$schema":"http://json-schema.org/draft-04/schema#",
"title":"ODSOR.T_MON_DOCDATUM",
"description":"JSON schema for table ODSOR.T_MON_DOCDATUM",
"definitions":{
"row":{
"type":"object",
"properties":{
"ID":{
"type":[
"string",
"null"
]
},
"FKCORP":{
"type":[
"string",
"null"
]
},
......
正常同步之后,Kafka 則會(huì)讀取 ./dirdef/ 目錄下生成的 json 文件進(jìn)行消費(fèi),消費(fèi)完之后如有必要還會(huì)落庫(kù)寫(xiě)入數(shù)據(jù)庫(kù),如果落庫(kù)有時(shí)候也會(huì)需要同步歷史數(shù)據(jù),可選擇 DataX 等 ETL 工具從源庫(kù)抽取歷史數(shù)據(jù),這里不在介紹,如有需要請(qǐng)自行查找相關(guān)文檔。
三、新增表配置
有時(shí)候隨著業(yè)務(wù)的快速發(fā)展及新功能需求,需要進(jìn)一步同步一些表到 Kafka,下面一起看看操作步驟。
這里以某一用戶下 T_FILE_RENDER 表為例進(jìn)行介紹,步驟完全一樣,不需要同步歷史數(shù)據(jù),僅使用 OGG 同步變化數(shù)據(jù)即可。
--源端
su - oracle
cd /ogg
./ggsci
GGSCI> stop EXT1
GGSCI> edit param ext1
#添加 TABLE CC.T_FILE_RENDER;到參數(shù)文件里,wq!保存退出
TABLE CC.T_FILE_RENDER;
GGSCI> view param ext1
#獲取 goldengate 數(shù)據(jù)庫(kù)用戶連接串
GGSCI> dblogin userid ogg@jiekedb, password ogg
#添加表字段補(bǔ)充日志
GGSCI> add trandata CC.T_FILE_RENDER
GGSCI> info trandata CC.T_FILE_RENDER
#看見(jiàn)is enabled 等字樣就代表補(bǔ)充日志已經(jīng)添加成功
#編輯 dpe1 投遞進(jìn)程添加新增表
GGSCI> edit parmas dpe1
TABLE CC.T_FILE_RENDER;
添加表到表結(jié)構(gòu)定義文件
添加 TABLE CC.T_FILE_RENDER;到表結(jié)構(gòu)變更配置文件
vi /ogg/dirprm/test_ogg.prm
TABLE CC.T_FILE_RENDER;
生成表結(jié)構(gòu)文件并傳到目標(biāo)端相關(guān)文件夾下。
./defgen paramfile dirprm/test_ogg.prm
scp /ogg/dirdef/goldengate.def oracle@192.168.75.17:/ogg/dirdef
添加各個(gè)表的補(bǔ)充日志后,停掉目標(biāo)端 rep1 復(fù)制進(jìn)程和源端 dpe1 投遞進(jìn)程,重啟 ext1 捕獲進(jìn)程。在目標(biāo)端 rep1 進(jìn)程參數(shù)中添加新增表的 MAP 信息,然后重啟即可。
GGSCI> stop rep1
GGSCI> edit params rep1
MAP CC.T_FILE_RENDER,target CC.T_FILE_RENDER;
GGSCI> start rep1
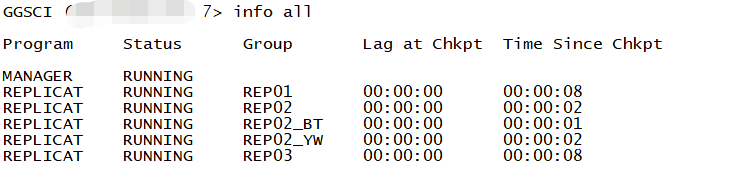
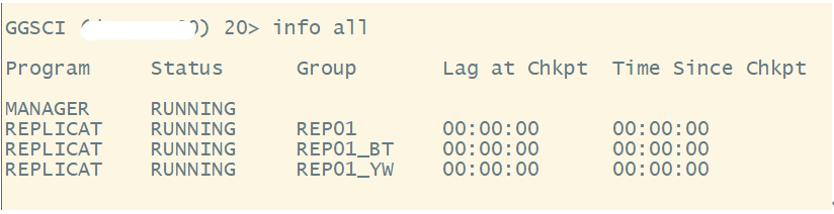
GGSCI> info all
GGSCI> info rep1
#啟動(dòng)之后觀察延遲趨近于0即為正常
參考文檔
https://docs.oracle.com/en/middleware/goldengate/big-data/12.3.2.1/gbdig/installing-oracle-goldengate-big-data.html#GUID-640A1CE0-7F5C-421C-B693-A74C6223F3B2
https://docs.oracle.com/goldengate/bd123010/gg-bd/GADBD/GUID-2561CA12-9BAC-454B-A2E3-2D36C5C60EE5.htm#GADBD449
全文完,希望可以幫到正在閱讀的你,如果覺(jué)得有幫助,可以分享給你身邊的朋友,同事,你關(guān)心誰(shuí)就分享給誰(shuí),一起學(xué)習(xí)共同進(jìn)步~~~
?? 歡迎關(guān)注我的公眾號(hào)【JiekeXu DBA之路】,一起學(xué)習(xí)新知識(shí)!
————————————————————————————
公眾號(hào):JiekeXu DBA之路
墨天輪:http://www.sunline.cc/u/4347
CSDN :https://blog.csdn.net/JiekeXu
騰訊云:https://cloud.tencent.com/developer/user/5645107
————————————————————————————

