




介紹
在本文中,我們將繼續討論關于“數據科學”和“機器學習”的重要關鍵面試問題,這有助于清楚地了解這些技術,也有助于機器學習、人工智能和數據科學面試。
我們相信您已經學習了有監督和無監督算法的理論和實踐知識。
因此,讓我們在這里測試您的知識。
面試問題
1.監督學習和無監督學習的區別。
|
|
| 監督學習算法使用標記數據(目標列)進行訓練。 | 無監督學習算法通過使用未標記的數據進行訓練。 |
| 監督學習算法旨在訓練模型在給定新數據時預測輸出。 | 無監督學習算法旨在從未知數據集中找到隱藏的模式和有用的見解 |
| 輸入數據與輸出一起提供給模型。 | 僅向模型提供輸入數據。 |
| 監督學習可以分為: 1.分類和 2.關聯問題。 | 無監督學習可分為: 1. 聚類和 2. 關聯問題。 |
2. 什么是線性回歸?
線性回歸通過尋找直線的最佳擬合來建立因變量 (Y) 和一個或多個自變量 (X) 之間的關系。
線性模型的方程是 Y = mX+C,
其中 m 是斜率,C 是截距。
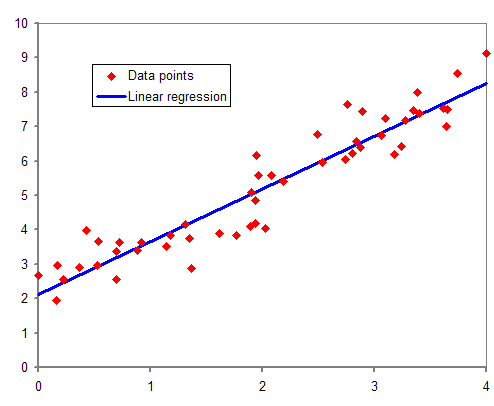
在上圖中,我們看到的紅點是“Y”關于 X 的分布。在現實生活中,沒有一條直線貫穿所有數據點。因此,這里的目標是擬合直線的最佳擬合,以最小化預期值和實際值之間的誤差。
回歸指標
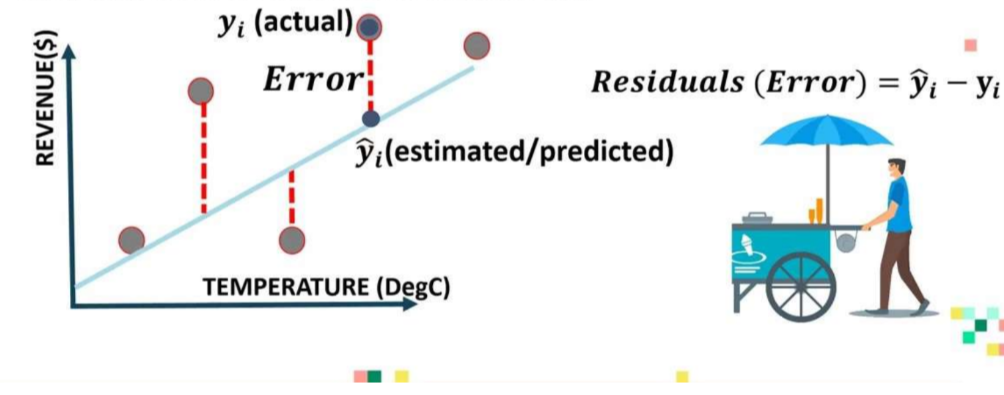
回歸指標:

3. 解釋回歸模型中的錯誤:
1. 平均絕對誤差 (MAE):
MAE 是通過計算模型預測值和真實(實際)值之間的絕對差來計算的。
MAE 是回歸模型產生的平均誤差幅度的度量:
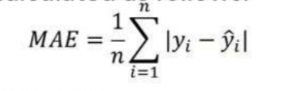
如果 MAE 為零,則表明模型預測是完美的。
2. 均方誤差 (MSE):
MSE 與平均絕對誤差 (MAE) 非常相似。在 MAE 中,不是使用絕對值,而是計算模型預測和訓練數據集(真值)之間差異的平方。
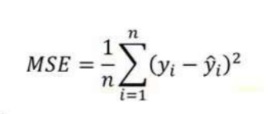
MSE 值通常大于 MAE,因為殘差是平方的。在數據異常值的情況下,與 MAE 相比,MSE 將變得非常大。
在 MSE 中,由于誤差是平方的,因此任何預測誤差都會受到嚴重懲罰。
3.根均方誤差(RMSE):
均方根誤差 (RMSE) 表示殘差的標準差(模型預測與真實值(訓練數據)之間的差異
。RMSE 提供了對分散殘差大小的估計。
與 MSE 相比,RMSE 可以很容易翻譯,因為RMSE 單位類似于輸出單位。
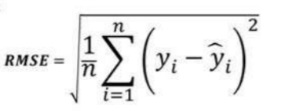
4. 平均百分比誤差 (MPE):
平均百分比誤差 (MPE) 有助于深入了解與負誤差相比有多少正誤差。
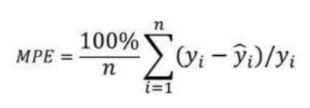
5. 平均絕對百分比誤差 (MAPE):
平均絕對誤差值的范圍可以從零到無窮大,因此與訓練數據相比,很難解釋結果。
平均絕對百分比誤差與 MAE 等效,但以百分比形式提供誤差,因此克服了 MAE 的限制。
如果數據點值為零(因為涉及除法運算符),MAPE 可能會表現出一些限制。
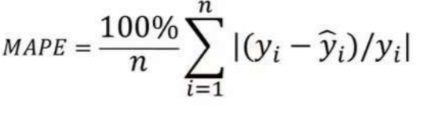
4. 什么是 R-Square,R-Square 究竟代表什么?
1. R-Square 表示因變量 (Y) 的方差已被自變量解釋的比例。
2. R-Square 提供對擬合優度的洞察。
3. 最大 R-Square 值為 1。
4. 始終預測 y 的期望值而忽略輸入特征的一致模型的 R-Square 評級為 0。
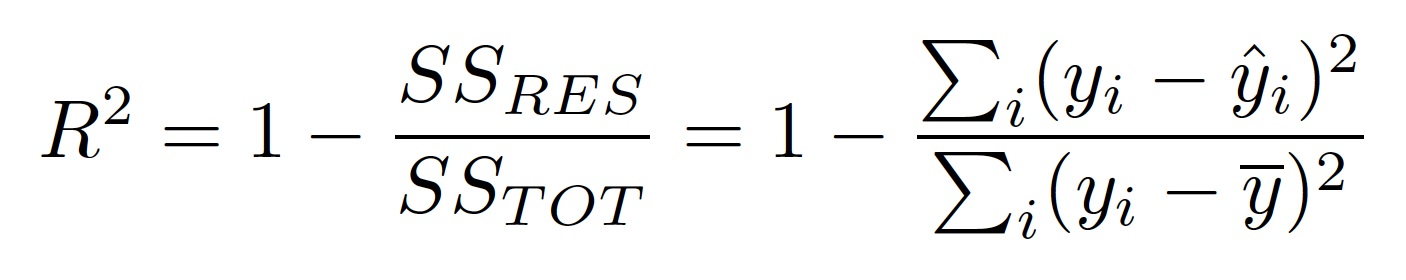
5. R-Square 和 Adjusted R-Square 有什么區別?
R-Square ( R2 ) 解釋了輸入變量解釋輸出/預測變量變化的程度。
如果 R-Square 為 0.8,則意味著 80% 的輸出變化由輸入變量解釋。所以簡單來說,R-Squared 越高,輸入變量解釋的變化就越多,因此我們的模型就越好。
R 方的限制之一是它通過向模型中添加自變量來增加,即使它們與輸出變量沒有任何關系或與輸出變量的關系非常小。
這就是調整后的 R 平方可以提供幫助的地方。如果我們嘗試添加一個不會改進模型的自變量,調整后的 R 方會通過添加懲罰來克服這個問題。
如果將無用的預測變量添加到模型中,調整后的 R-Square 將會減少。
如果將有用的預測變量添加到模型中,調整后的 R-Square 將會增加。
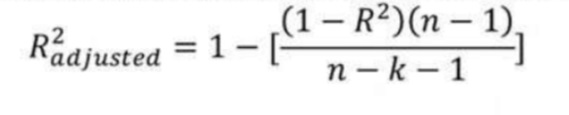
字母 k 表示自變量數,字母 n 表示樣本數。
因此,如果您正在開發多個變量的線性回歸模型。始終建議您使用調整后的 R-Squared 來判斷模型的優劣。如果您只有一個輸入變量 R-Square 和 Adjusted R-Square 將是相同的。
6. 線性回歸的假設是什么?
線性回歸是一種統計模型,它允許基于一個或多個自變量(表示為 X)的變化來解釋因變量 y。它基于因變量和自變量之間的線性關系來做到這一點。
1. 線性/線性關系:自變量 X 和因變量 Y 之間存在線性關系。檢測是否滿足此假設的最簡單方法是創建 X 與 Y 的散點圖。這使您可以可視化是否這兩個變量之間存在線性關系。
2. 獨立性:線性回歸的下一個假設是殘差是獨立的。在處理時間序列數據時最相關。理想情況下,我們不希望在連續殘余之間存在模式。測試是否滿足此假設的最簡單方法是查看殘差時間序列圖,它是殘差與時間的關系圖。
3. 正態性:線性回歸的下一個假設是殘差是“正態分布的”。QQ 圖是分位數圖的縮寫,是一種我們可以用來確定模型的殘差是否服從正態分布的圖。如果圖上的點大致形成一條直線對角線,則滿足正態性假設。
4. 等方差/同方差性:殘差在每個 X 水平(自變量)處具有恒定方差。它被稱為同方差性。將回歸線擬合到一組數據后,您可以創建一個散點圖,顯示模型的擬合值與這些擬合值的殘差。
7.回歸和相關有什么區別?
相關性: 在實際情況下,相關性衡量兩個變量之間關系的強度或程度。它沒有捕捉因果關系。“相關性”用一個點來表示。
回歸:衡量一個變量如何影響另一個變量。“回歸”是關于模型擬合的。它試圖捕捉因果關系并解釋因果關系。“回歸”由回歸線表示。
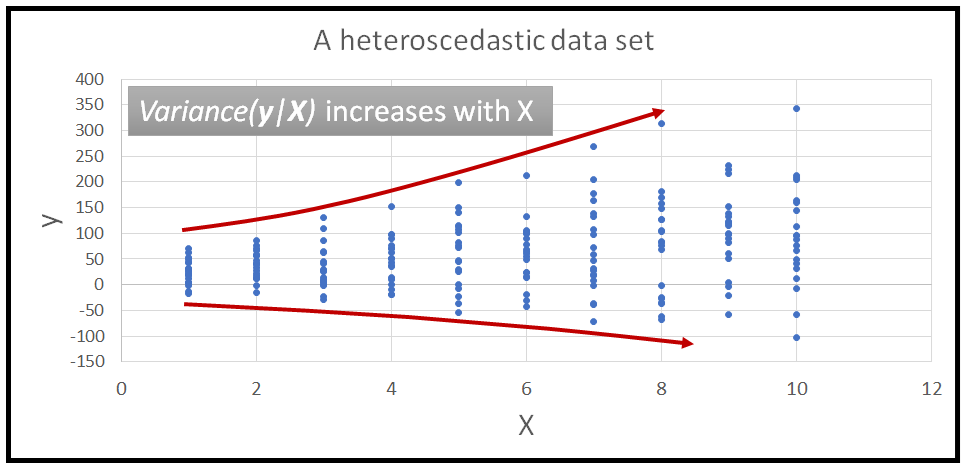
8. 什么是異方差?如何檢測它?
異方差是指殘差的方差在一系列測量值上不相等的情況。運行回歸分析時,“異方差”會導致殘差(也稱為誤差項)分布不均。
9. 什么是線性回歸中的截距?它的意義是什么?
截距是函數穿過 Y 軸的點。當所有 X = 0 時,截距是 Y 值的標準平均值。
10.什么是OLS?
OLS 代表普通最小二乘。線性回歸算法的主要目標是通過最小化誤差項來找到系數或估計值,從而使平方誤差之和最小。此過程稱為 OLS。
此方法通過最小化觀察值和預測值之間的平方差之和來找到最佳擬合線,稱為回歸線。
11. 什么是多重共線性?
這是一種現象,其中兩個或多個自變量(預測變量)彼此高度相關,使得一個變量可以在其他變量的幫助下線性預測。它決定了自變量之間的相互關系和關聯。
多重共線性的原因:
1.假人使用不準確。
2. 由于可以從數據集中的另一個變量計算的變量。
檢測多重共線性:
1. 通過使用相關系數。
2.借助方差膨脹因子(VIF)和特征值。
12. 什么是 VIF?你是怎么計算的?
VIF 代表方差膨脹因子,它決定了估計回歸系數的方差由于變量之間存在共線性而增加了多少。它還計算特定回歸模型中存在多少多重共線性。
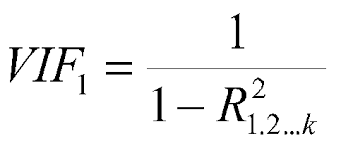
總是希望 VIF 值盡可能低。設置了閾值,這意味著任何大于閾值的自變量都必須刪除。
13. 對于線性回歸模型,我們如何解釋 QQ 圖?
QQ 圖用于表示兩個相互關聯的分布的分位數的圖形繪圖。簡單來說,QQ圖就是用來檢驗誤差的正態性的。
每當我們解釋 QQ 圖時,我們都應該關注對應于正態分布的 y=x 線。有時這也被稱為統計中的 45 度線。
QQ圖的用法:
1. 檢查兩個樣本是否來自同一個總體。
2. 兩個樣本是否有相同的尾巴。
3. 兩個樣本是否具有相同的分布形狀。
14. 為什么首選絕對誤差而不是平方誤差?
1. 從我們的模型進行預測時,絕對誤差通常更接近我們想要的。但是,如果我們想懲罰那些導致誤差最大值的預測。
2. 在數學方面,平方函數處處可微,而絕對誤差在所有點處不可微,其導數未定義為 0。這使得平方誤差比數學優化技術更可取。
3.我們使用均方根誤差代替均方誤差,使RMSE的單位和因變量相等,結果可解釋。
15. 線性回歸算法的缺點是什么?
1、線性假設:始終假設自變量(輸入)和因變量(輸出)之間存在線性關系。因此,我們無法借助線性回歸來擬合復雜的問題。
2.異常值:對異常值高度敏感。
3. 多重共線性:受多重共線性影響。
16. 什么是正則化?解釋它的類型?
正則化旨在通過以下方式解決一些常見的模型問題:
1. 最小化模型復雜度。
2. 懲罰損失函數。
3. 減少模型過擬合(增加更多偏差以減少模型方差)。
一般來說,我們一般可以解釋,正則化是一種減少模型過擬合和方差的方法。為了這-
1. 它需要一些額外的偏見
2. 需要搜索最優懲罰超參數。
類型:
1. L2 正則化:嶺回歸
2. L1 正則化:LASSO 回歸
3.結合L1和L2:彈性網絡
L2 正則化:嶺回歸
嶺回歸通過應用懲罰項(減少權重和偏差)來克服過度擬合。
在 Ridge 中,回歸斜率隨著 ridge 回歸懲罰項而減小,因此模型對自變量的變化變得不那么敏感。
最小二乘回歸:最小值(殘差平方和)
嶺回歸:最小值(殘差平方和 + α .(斜率)2)
L1 正則化:LASSO 回歸
套索回歸類似于嶺回歸。它通過引入偏置項來工作,但不是平方斜率,而是將斜率的絕對(模量)值添加為“懲罰項”。
最小二乘回歸:最小值(殘差平方和)
嶺回歸:最小值(殘差平方和 + α |斜率|)
彈性網:
彈性網絡是一種流行的正則化線性回歸類型,它結合了 L1 和 L2 懲罰項。
17. 機器學習中的分類算法是什么?
分類算法是一種監督學習技術,用于根據訓練數據識別新觀察的類別。在分類中,程序從給定的數據集或觀察中學習,然后將新的觀察分類為若干類或組,例如是或否。0 或 1。垃圾郵件或非垃圾郵件。類可以稱為目標或類別。
1.二元分類器:如果分類問題只有兩種可能的結果,則稱為二元分類器。
示例:是或否、男性或女性、垃圾郵件或非垃圾郵件
2. 多類分類器:如果問題有兩個以上的結果,則稱為多類分類器。
示例農作物類型分類,音樂類型分類。
分類算法可以進一步分為主要的兩類:
1. 線性模型:
1. 邏輯回歸
2. 支持向量機。
2.非線性模型:
1. K-最近鄰
2. 內核支持向量機
3.樸素貝葉斯
4.決策樹分類
5. 隨機森林分類。
18.你對混淆矩陣的理解是什么?解釋?
1.混淆矩陣是一個N x N矩陣,用于評估分類模型的性能,其中N是目標類的數量。
2.混淆矩陣在機器學習模型的幫助下將實際目標值與預測值進行比較。
3. 也稱為誤差矩陣。
19.什么是AUC-ROC曲線?
1. ROC Curve 代表 Receiver Operating Characteristics Curve & AUC 代表 Area Under the Curve。
2. 該圖顯示了分類模型在不同閾值下的性能。
3. 為了可視化多類分類模型的性能,我們使用 AUC-ROC 曲線。
4. ROC 曲線以 FPR(假陽性率)為 X 軸,TPR(真陽性率)為 Y 軸繪制。
5. 如果 ROC-AUC = 1,完美分類器。
20.什么是邏輯回歸?
邏輯回歸是一種監督學習分類算法,用于預測目標變量的概率。
目標或依賴的性質是不可分割的,這意味著將只有兩個可能的類別。
簡而言之,因變量本質上是二進制的,數據編碼為 1 或 0。
在邏輯回歸中,我們不是擬合回歸線,而是擬合“S”形邏輯函數,它預測兩個最大值(0 或 1)。
例子:
1. 細胞是否癌變。
2. 學生將通過或失敗。
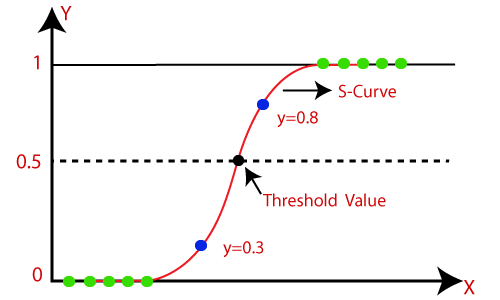
21.什么是Logistic函數或Sigmoid函數?
Sigmoid 函數是一種數學函數,用于將預測值映射到 0 和 1 的概率。
線性回歸模型將預測值生成為從負無窮到正無窮的任意數字。但是我們知道概率可以在 0 到 1 之間。
為了克服這個問題,我們使用回歸曲線,它使用 Sigmoid 函數將曲線的直線轉換為 S 曲線,它總是會給出 0 到 1 之間的值1. S型曲線稱為sigmoid或Logistic函數。功能。
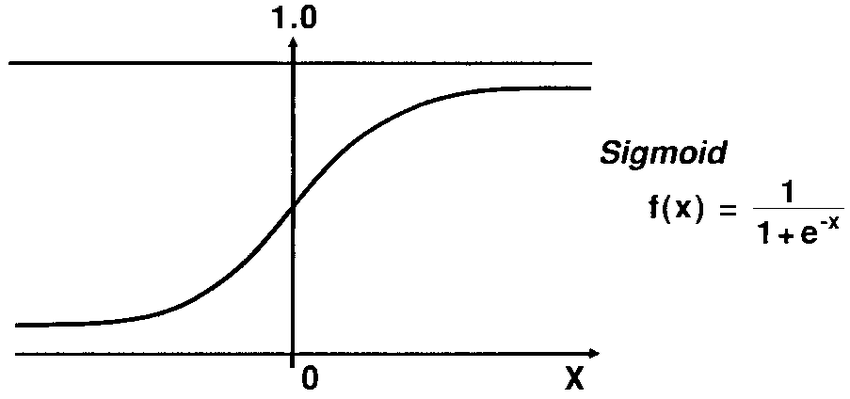
22. 解釋邏輯回歸中的假設:
1. 自變量之間沒有或最小的多重共線性,因此預測變量不相關。
2. 結果的 Logit 和每個預測變量之間應該存在線性關系。
3. 通常需要大樣本量。
4. 它假定觀察之間沒有依賴關系。
23. 線性回歸和邏輯回歸的比較。
| 線性回歸 | 邏輯回歸 |
| 線性回歸用于使用給定的一組自變量來預測連續因變量。 | 邏輯回歸用于使用給定的一組自變量來預測 0 和 1 形式的分類因變量。 |
| 它基于最小二乘估計方法。 | 它基于最大似然估計方法 |
| 這里不需要閾值。 | 這里需要閾值。 |
| 在線性回歸中,要求因變量和自變量之間的關系必須是線性的。 | 因變量和自變量之間不需要具有線性關系。 |
| 在線性回歸中,自變量之間存在共線性的可能性。 | 在邏輯回歸中,自變量之間不應存在共線性。 |
面試問題的結論
感謝您的閱讀。我希望你對出現在數據科學面試中充滿信心。我希望你喜歡面試問題,并且能夠測試你對數據科學和機器學習的了解。如果您有任何反饋或想分享您對這些評論的看法,請在下面的評論框中分享。
電子郵件:anurag8200@gmail.com
原文標題:Interview Questions to Test your Data Science Skills
原文作者:ANURAG SINGH CHOUDHARY
文章來源:https://www.analyticsvidhya.com/blog/2022/06/interview-questions-to-test-your-data-science-skills/
