




版本信息
服務器版本:Kylin v10sp2
數據庫版本:Mogdb 2.0.1
故障現象
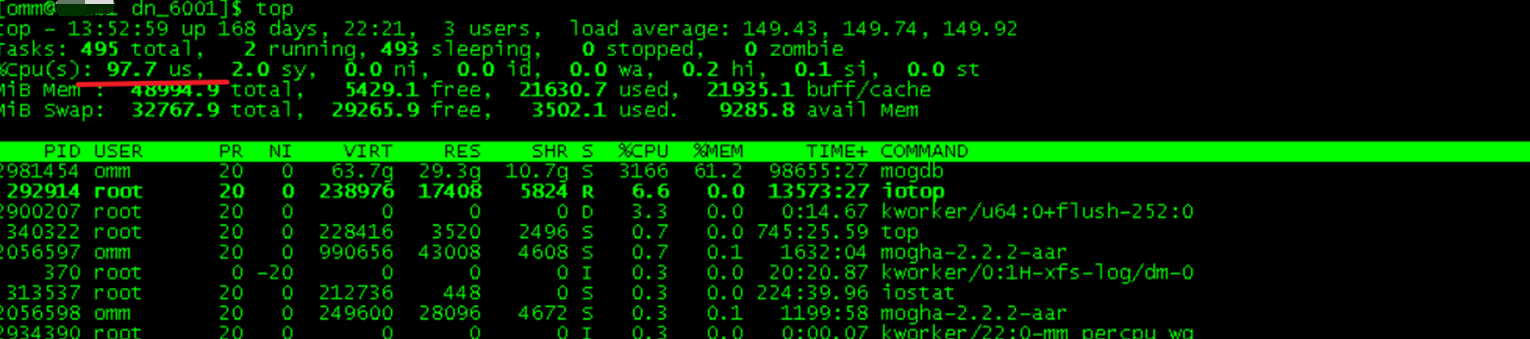
早起,用戶告知生產數據庫CPU使用率過高,達到了95+。簡單排查后,發現數據庫主進程占用了75%的CPU消耗,開始進入處理流程。

故障處理流程
一般導致數據庫占用CPU資源過高主要由SQL硬解析,并行,栓鎖spin,執行計劃改變等多個原因導致。碰到此類問題,首先應盡快理清數據庫當前正在運行的事務,運行的SQL,確定問題發生時間,查看數據庫日志,系統日志等明確故障成因。
1、查看數據庫當前事務,及SQL
--查看數據庫當前事務
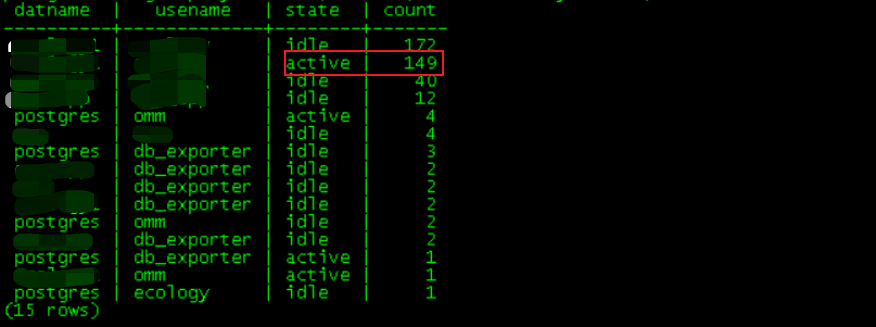
select datname,usename,state,count(*)
from pg_stat_activity
group by datname,usename,state order by 5 desc;
--查看業務系統運行的SQL
select datname,usename,state,query,count(*)
from pg_stat_activity
where datname='xxxxx' and state='active'
group by datname,usename,state,query order by 5 desc;

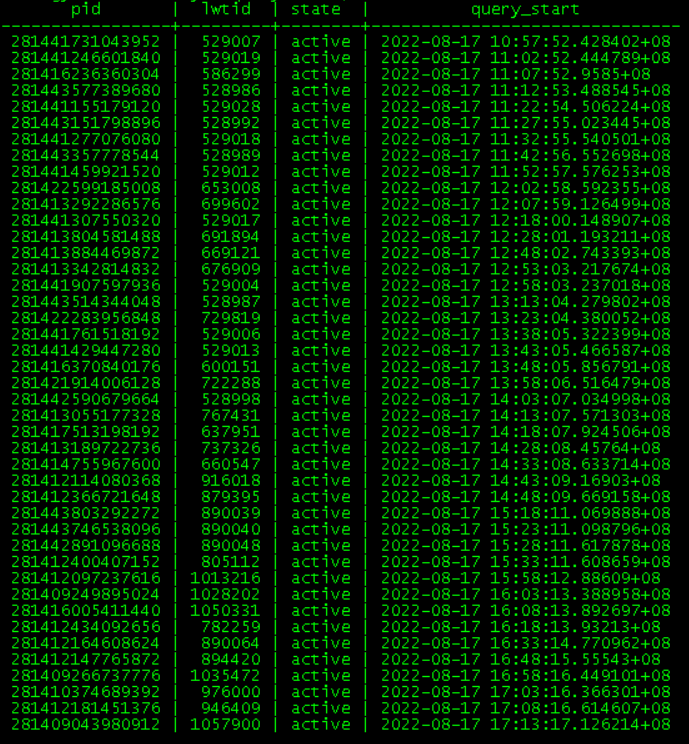
可以發現生產業務正在長時間運行同一個SQL,從截圖中發現這個SQL運行了140次,而且都處在active狀態,繼續查看SQL的開始執行時間
--查看pid和SQL,開始時間
select pid,lwtid,state,query_start from pg_stat_activity a,dbe_perf.thread_wait_status s where a.pid=s.tid
and a.datname='xxxxx' and a.state='active' and a.usename='xxxxx'
order by a.query_start;
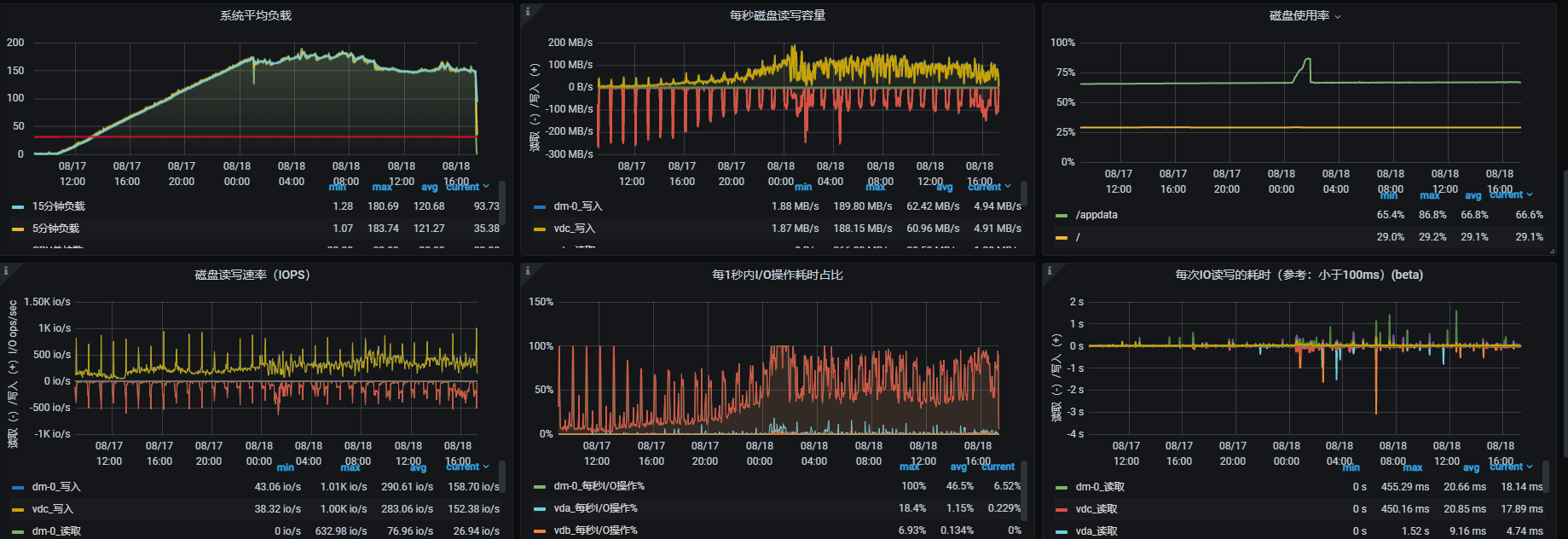
2、確定故障發生時間
使用Mogdb—export監控軟件,確定故障發生時間,在17日10點發生,17日12點,服務器CPU峰值達到峰值(沒有安裝Mogdb-export的系統可以使用sar命令對系統日志進行小時粒度的性能分析,確定問題時間點)
3、輸出故障SQL
由于在數據字典中,SQL顯示不全,可以通過設置log_min_duration_statement參數將SQL存入數據庫日志中
4、查看數據庫日志
無報錯,略
5、查看系統日志
無報錯,略
故障分析
經過以上的診斷后,基本可以確定故障點就是這個SQL了,查看SQL的執行計劃,發現存在性能瓶頸

同時通過SQL的運行時間發現一個規律,SQL每5min定時啟動運行一次,而5min卻不夠SQL執行完,形成了瀑布效應,最終形成了性能雪崩,導致服務器CPU使用率達到了95%+。
故障處理
對運行SQL的140個會話,直接kill session,釋放性能消耗(注意,如果開啟了線程池,使用pg_terminate_backen(pid)函數將無法正常的釋放事務,可以使用pg_terminate_session(pid,sessionid)替代)
--kill session
select pg_terminate_backend(pid)
from pg_stat_activity
where state = 'active' and datname='xxxxx' and usename='xxxxx';
故障總結
本次遇到的故障處理并不復雜,但是具有代表性,在發生故障時,首先需要確定問題點,在簡單判斷問題成因后,可以通過數據字典,日志,數據庫相關組件一同確定問題。如本次案例中,類似的性能問題,除了上文中提到的,還可以通過查詢判斷栓鎖,等待事件,WDR報告,stack工具等一起定位問題。
同時,清理相關的session也只是處理問題的開始,后續可能還會存在SQL調優的工作,所以盡量收集表結構,表的信息重現故障場景也是很重要的工作。本次案例中,用戶直接將SQL發給研發廠商進行處理,不涉及后續SQL調優方面內容。
