




我們收到了大量想更多了解Oracle的優化器轉換的請求,所以,我們想我們應該組織一個系列博客文章,來描述最常用的轉換。在接下來的一個季度里,你應該會每月看到兩篇關于這方面的文章。
開始前,我們需要解釋一下轉換的含義是什么?當一條SQL語句被解析,優化器會嘗試“轉換”或重寫該SQL為一個語義上等價的,處理起來更有效率的SQL。我們首次提及轉換的概念是在2008年6月,一篇名為《為什么我查詢中的一些表從執行計劃中消失了?》的博客文章中。這篇最初的文章中,只討論了Oracle數據庫11g中引入的一種新轉換,稱為表消除。新系列文章中的第一部分,我們將討論子查詢展開。我必須要感謝Rafi ---- 優化器的高級開發人員之一,他為本主題提供了內容。
子查詢展開
子查詢展開是一種將子查詢轉換為外連接的優化方法,并允許優化器在選擇訪問路徑,連接方法和連接次序期間,考慮子查詢中的表。展開要么是將子查詢是合并到外層查詢中,要么轉換為一個內聯視圖(譯者注:出現在from子句中的子查詢)。
沒有子查詢展開,子查詢將為外層查詢中的每一行進行多次評估。因此很多高效的訪問方法和連接方法不會被考慮。
這里,我們將討論出現在WHERE子句中的ANY和EXISTS子查詢上的展開.
術語
任何出現在查詢語句中的子查詢塊,都可以被稱之為子查詢。但是,我們將出現在WHERE、SELECT和HAVING子句中的子查詢塊,使用術語子查詢來稱之。部分Oracle官方文檔使用術語“嵌套子查詢”來稱呼他們。出現在FROM子句中的子查詢塊被稱為視圖或派生表。
分類子查詢的方法有很多種,主要的分類方法是基于子查詢在SQL語句中的使用方式。一個WHERE子句中的子查詢屬于以下類型之一:單行,EXISTS,NOT EXISTS, ANY 或者ALL。單行子查詢最多只能返回1行,而其它類型的子查詢可以返回0行或多行。
ANY和ALL子查詢會和關系比較操作符(=, >,>=, <, <=, 和 <>.)一起使用。SQL中,集合操作符 IN 用 =ANY 縮寫,NOT IN 用 <>ALL 縮寫。
查詢A展示了一個EXISTS的關聯子查詢的示例
A.
SELECT C.cust_last_name, C.country_id
FROM customers C
WHERE EXISTS (SELECT 1
FROM sales S
WHERE S.quantity_sold > 1000 and
S.cust_id = C.cust_id);
出現在子查詢中的 ,且不屬于子查詢中定義的表中的列,稱之為關聯列。A例中的子查詢就是關聯的,它引用了一個關聯列 c.cust_id,他來自于表customers,而該表并不是由子查詢定義的(即表沒有出現在子查詢中)。謂詞S.cust_id = C.cust_id被稱為關聯條件或關聯謂詞。
再來看查詢B,它包含一個非關聯的ANY子查詢。請注意查詢B和查詢A在語義上是等價的。
B.
SELECT C.cust_last_name, C.country_id
FROM customers C
WHERE C.cust_id =ANY (SELECT S.cust_id
FROM sales S
WHERE S.quantity_sold > 1000);
示例B中的子查詢是非關聯的,即,他沒有引用關聯列。 "C.cust_id = ANY S.cust_id"被稱為連接條件。
子查詢評估
如果一個NOT EXISTS子查詢返回0行,則被評估為TRUE。
ANY/ALL子查詢會返回值的集合,如果謂詞中包含ANY/ALL的子查詢滿足該條件,則其被評估為TRUE.例如上例,至少要有一個s.cust_id要可匹配上查詢B中的ANY子查詢的連接條件中的C.cust_id。
注:oracle會將一個不能展開的ANY或ALL子查詢,轉換為相應的EXISTS和NOT EXISTS子查詢。
當一個關聯子查詢不能展開時,該子查詢會被評估多次,為外層表的每一行,替換關聯列的值(例如示例A中customers.cust_id)。因此,子查詢中表的訪問和連接在每一次調用時被重復執行,并且,涉及子查詢中的表和外層查詢中的表的連接次序也是不能改變的。這類評估還會抑制并行化。
XA展示了查詢A的執行計劃。這里的子查詢展開被關閉了。觀察執行計劃底部的謂詞信息,不能展開的子查詢文本被顯示為filter。如執行計劃所示,子查詢會被評估多次(例如50K次,外層CUSTOMERS表中的每一行一次)。
XA.
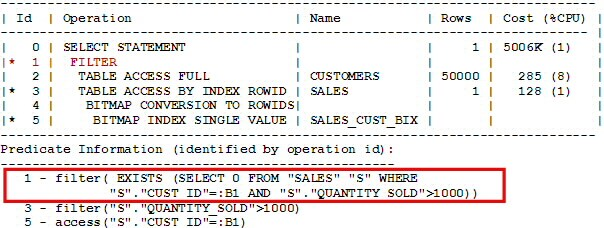
EXISTS和ANY子查詢
半連接通常用來展開EXISTS和ANY子查詢。但是,在不涉及重復行的情況下,內連接也是可以用來展開EXISTS和ANY子查詢的。
這里,我們使用如下的非標準語法,來表示半連接:
T1.x S= T2.y
其中T1是半連接中的左表,T2是半連接中的右表。半連接的語義如下:
只要T1.x可以在T2.y的值中找到匹配,就返回T1表的該行,而無需進一步查找更多的匹配。
考慮一下前面的查詢A,子查詢展開產生了查詢C,這里子查詢被合并到了外層查詢。關聯條件被轉換為連接謂詞;customers表和sales表成為了半連接中相應的左表和右表。
C.
SELECT C.cust_last_name, C.country_id
FROM customers C, sales S
WHERE S.quantity_sold > 1000 and
C.cust_id S= S.cust_id;
查詢C的執行計劃如下面的XC所示。注意計劃XC和XA的成本的不同。XA是關閉展開時產生的,顯然,展開時的計劃(XC)是更優的,其成本已從5006K下降到2300.(查詢B也會產生和XC相同的計劃)
XC.
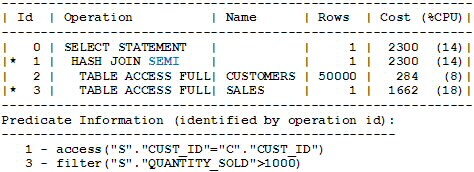
現在,再看一下查詢D。它包括了兩個表的非相關ANY子查詢。
D.
SELECT C.cust_last_name, C.country_id
FROM customers C
WHERE C.cust_id =ANY (SELECT S.cust_id
FROM sales S, products P
WHERE P.prod_id = S.prod_id and P.prod_list_price > 105);
查詢D中的子查詢可以通過半連接被展開。但是,子查詢中的表是內連接,sales和products表應該在半連接前被執行。因此,需要生成內聯視圖,以確保連接次序。查詢E展示了對查詢D的展開轉換。這里的子查詢是不相關的,并且轉換為內聯視圖。成為半連接中的右表。而關聯謂詞則被轉換為連接謂詞。
E.
SELECT C.cust_last_name, C.country_id
FROM customers C,
(SELECT S.cust_id as s_cust_id
FROM sales S, products P
WHERE P.prod_id = S.prod_id and
P.prod_list_price > 105) VW
WHERE C.cust_id S= VW.s_cust_id;
XE展示了查詢E的執行計劃。它有一個優化器生成的,名為VW_NSQ_1,在三種可用的連接方法(嵌套循環,HASH和排序合并)中,HASH方法被優化器選中做為半連接的連接方法。
XE
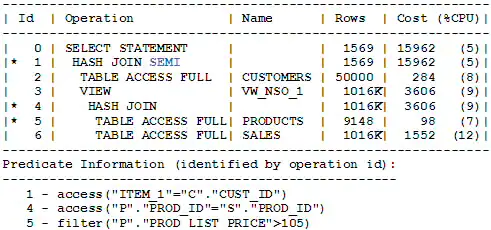
子查詢展開博客的第二部分,會討論NOT EXISTS子查詢,單行聚合子查詢,只要它們被展開前的有效性驗證所允許。
原文鏈接:https://blogs.oracle.com/optimizer/post/optimizer-transformations-subquery-unnesting-part-1
原文內容:
Optimizer Transformations: Subquery Unnesting part 1
January 1, 2020 | 5 minute read
Maria Colgan
Distinguished Product Manager
We have received a ton of requests for more information on Oracle Optimizer Transformations so we thought we would put together a series of blog posts describing the most commonly used transformations. You should expect to see two blog posts a month on this over the next quarter.
Before we begin we should explain what we mean by transformation? When a SQL statement is parsed, the Optimizer will try to “transform” or rewrite the SQL statement into a semantically equivalent SQL statement that can be processed more efficiently. We first discussed the concepts of transformations in a blog post in June 2008 called why are some of tables in my query missing in my plan. This original post dealt with just one of the new transformations introduced in Oracle Database 11g called table elimination. Part one of our new series will deal with subquery unnesting. I must give credit to Rafi, one of the senior Optimizer developers, who provided the content for this topic.
Subquery Unnesting
Subquery unnesting is an optimization that converts a subquery into a join in the outer query and allows the optimizer to consider subquery table(s) during access path, join method, and join order selection. Unnesting either merges the subquery into the body of the outer query or turns it into an inline view.
Without unnesting, the subquery is evaluated multiple times, for each row of the outer table, and thus many efficient access paths and join methods cannot be considered.
Here we will discuss the unnesting of ANY and EXISTS subqueries, which appear in the WHERE clause.
Terminology
Any sub-query block in a query statement may be called a subquery; however, we use the term subquery for a sub-query block that appears in the WHERE, SELECT and HAVING clauses. Some Oracle documentation uses the term “nested subquery” for what we refer to as a subquery. A sub-query block that appears in the FROM clause is called a view or derived table.
There are many ways to classify a subquery. The main categorization comes from the way a subquery is used in SQL statements. A WHERE clause subquery belongs to one of the following types: SINGLE-ROW, EXISTS, NOT EXISTS, ANY, or ALL. A single-row subquery must return at most one row, whereas the other types of subquery can return zero or more rows.
ANY and ALL subqueries are used with relational comparison operators: =, >,>=, <, <=, and <>. In SQL, the set operator IN is used as a shorthand for =ANY and the set operator NOT IN is used as a shorthand for <>ALL.
Query A shows an example of a correlated EXISTS subquery.
A.
SELECT C.cust_last_name, C.country_id
FROM customers C
WHERE EXISTS (SELECT 1
FROM sales S
WHERE S.quantity_sold > 1000 and
S.cust_id = C.cust_id);
A column that appears in a subquery is called a correlated column, if it comes from a table not defined by the subquery. The subquery in A is correlated, as it refers to a correlated column, C.cust_id, which comes from, customers, a table not defined by the subquery. The predicate, S.cust_id = C.cust_id, is called a correlating condition or a correlated predicate.
Consider query B, which contains an uncorrelated ANY subquery. Note that queries B and A are semantically equivalent.
B.
SELECT C.cust_last_name, C.country_id
FROM customers C
WHERE C.cust_id =ANY (SELECT S.cust_id
FROM sales S
WHERE S.quantity_sold > 1000);
The subquery in B is uncorrelated, as it does not refer to a correlated column. “C.cust_id = ANY S.cust_id” in B is called a connecting condition.
Subquery Evaluation
A NOT EXISTS subquery evaluates to TRUE, if it returns no rows.
The ANY/ALL subquery returns a set of values, and the predicate containing the ANY/ALL subquery will evaluate to TRUE, if it is satisfied. For example, at least one S.cust_id values must match C.cust_id in the connecting condition of the ANY subquery of query B.
Note that in Oracle, a non-unnested ANY and ALL subquery is converted into a correlated EXISTS and NOT EXISTS subquery respectively.
When a correlated subquery is not unnested, the subquery is evaluated multiple times, for each row of the outer tables, substituting the values of correlated columns (e.g., customer.cust_id in A). Thus, table accesses and joins inside the subquery are repeatedly performed with each invocation and join orders involving subquery tables and outer query tables cannot be explored. This type of evaluation also inhibits parallelization.
XA shows the execution plan for query A. Here subquery unnesting has been disabled. Observe that the text of the non-unnested subquery filter is displayed in the predicate dump at the bottom of the plan. As the execution plan shows, the subquery will be evaluated multiple (i.e., 50K) times (once per each outer row of the CUSTOMERS table).
XA.
explain_plan_for_A.png
EXISTS and ANY Subqueries
Semi-join is generally used for unnesting EXISTS and ANY subqueries. However, in some cases where duplicate rows are not relevant, inner join can also be used to unnest EXISTS and ANY subqueries.
Here we represent semi-join by the following non-standard syntax: T1.x S= T2.y, where T1 is the left table and T2 is the right table of the semi-join. The semantics of semi-join is the following: A row of T1 is returned as soon as T1.x finds a match with any value of T2.y without searching for further matches.
Consider the previously shown query A. Unnesting of the subquery in A produces query C, where the body of the subquery has been merged into the outer query. Here the correlating condition has been turned into a join predicate; customers and sales become the left and right tables respectively in the semi-join.
C.
SELECT C.cust_last_name, C.country_id
FROM customers C, sales S
WHERE S.quantity_sold > 1000 and
C.cust_id S= S.cust_id;
The execution plan of C is shown below as XC. Note the difference between the costs of the plan XC and the plan XA; recall that XA was generated by disabling unnesting. Clearly, the plan with unnesting (XC) is much more optimal; the cost has come down from 5006K to 2300. (The query B also produces the same plan as XC.)
XC.
explain_plan_for_C.png
Now consider query D, which contains an uncorrelated ANY subquery that has two tables.
D.
SELECT C.cust_last_name, C.country_id
FROM customers C
WHERE C.cust_id =ANY (SELECT S.cust_id
FROM sales S, products P
WHERE P.prod_id = S.prod_id and P.prod_list_price > 105);
The subquery in D can be unnested by using a semi-join; however, the inner join of the tables in the subquery, sales and products must take place before the semi-join is performed. Therefore, an inline view needs to be generated in order to enforce the join order. The query E shows the unnesting transformation of D. Here the subquery is decorrelated and converted into an inline view, which becomes the right table in the semi-join; and the correlated predicate is turned into a join predicate.
E.
SELECT C.cust_last_name, C.country_id
FROM customers C,
(SELECT S.cust_id as s_cust_id
FROM sales S, products P
WHERE P.prod_id = S.prod_id and
P.prod_list_price > 105) VW
WHERE C.cust_id S= VW.s_cust_id;
XE shows the execution plan of E. It has an optimizer-generated inline view named VW_SQ_1. Of the three available join methods (i.e., nested-loop, hash, and sort-merge), the hash method was selected by the optimizer to do the semi-join.
XE
explain_plan_for_E.png
Part 2 of our blog on Subquery Unnesting discusses NOT EXISTS subqueries, single-row aggregated subqueries, as well as the validity checks performed before unnesting is allowed.
