




國產數據庫梳理
當前國產數據庫百花齊放,幾乎每隔半年就會冒出一家數據庫,各大廠商在去年也都更新了自己的數據庫產品線名稱,太多的數據庫讓人混淆。
本文是對幾大巨頭廠商產品的一個梳理,給大家做個普及。
背景介紹及架構介紹
網上對這些數據庫介紹有些誤導,流傳各種說法,比如:流傳OB基于MySQL、GaussDB 200/300 和openGauss有啥區別,沒辦法誰讓當前國產數據庫太多…
| Tidb | PolarDB | TDSQL | GaussDB | OceanBase | |
|---|---|---|---|---|---|
| 公司 | PingCap | 阿里云 | 騰訊 | 華為 | 阿里 |
| 歷史 | 基于Google Spnner論文實現的原生分布式數據庫 | PolarDB現在也是一個系列,分別是:PolarDB-X分布式數據庫從DRDS升級過來的,PolarDB-O兼容Oracle數據庫,PolarDB-MySQL/PostgreSQL Shared-Storage架構對比AWS Aurora但實現有所不同,Aurora對內核改動更大,完全取消了數據文件,PolarDB則是用redo進行節點之間的傳輸 | 現在做了名字修改,分為TDSQL-MySQL和PG,PG版是以前的TBase。TDSQL-C對標的是Aurora | GaussDB現在是一個系列,現在常說的就是PG這個版本,以前叫做100,200,300對應現在的openGauss(交易型),GaussDB DWS(分析型),GaussDB for openGauss(HTAP)。GaussDB for MySQL對標Aurora) | 100%自研,沒有基于任何開源數據庫模塊,經歷開源->閉源->開源 |
從架構相似看各個廠家之間產品對標:
- MySQL系列
| PingCap | 騰訊 | 阿里 | 華為 | 備注 | |
|---|---|---|---|---|---|
| Tidb | TDSQL-新敏態引擎 | ||||
| TDSQL-MySQL | PolarDB-X(以前的DRDS) | DDM | |||
| TDSQL-C for MySQL | Polardb for MySQL | GaussDB for MySQL | 這一類需要帶云底座,依賴于底層文件系統 |
- PG系列
| PingCap | 騰訊 | 阿里 | 華為 | 備注 | |
|---|---|---|---|---|---|
| TDSQL-PG | GaussDB for openGauss | ||||
| TDSQL-C for PostgreSQL | Polardb for PostgreSQL | 這一類需要帶云底座,依賴于底層文件系統 |
架構上劃分
產品太多,如果從各家產品做劃分介紹會有很大重復性,從架構角度看會比較清晰
分庫分表類
這類架構相信大家很熟悉了,發展到現在也很長時間了,通過Proxy進行數據路由和分片,數據節點存放具體數據一般是主備數據庫架構,由于歷史原因這類架構下MySQL版本與PG版本會有不同:
-
MySQL
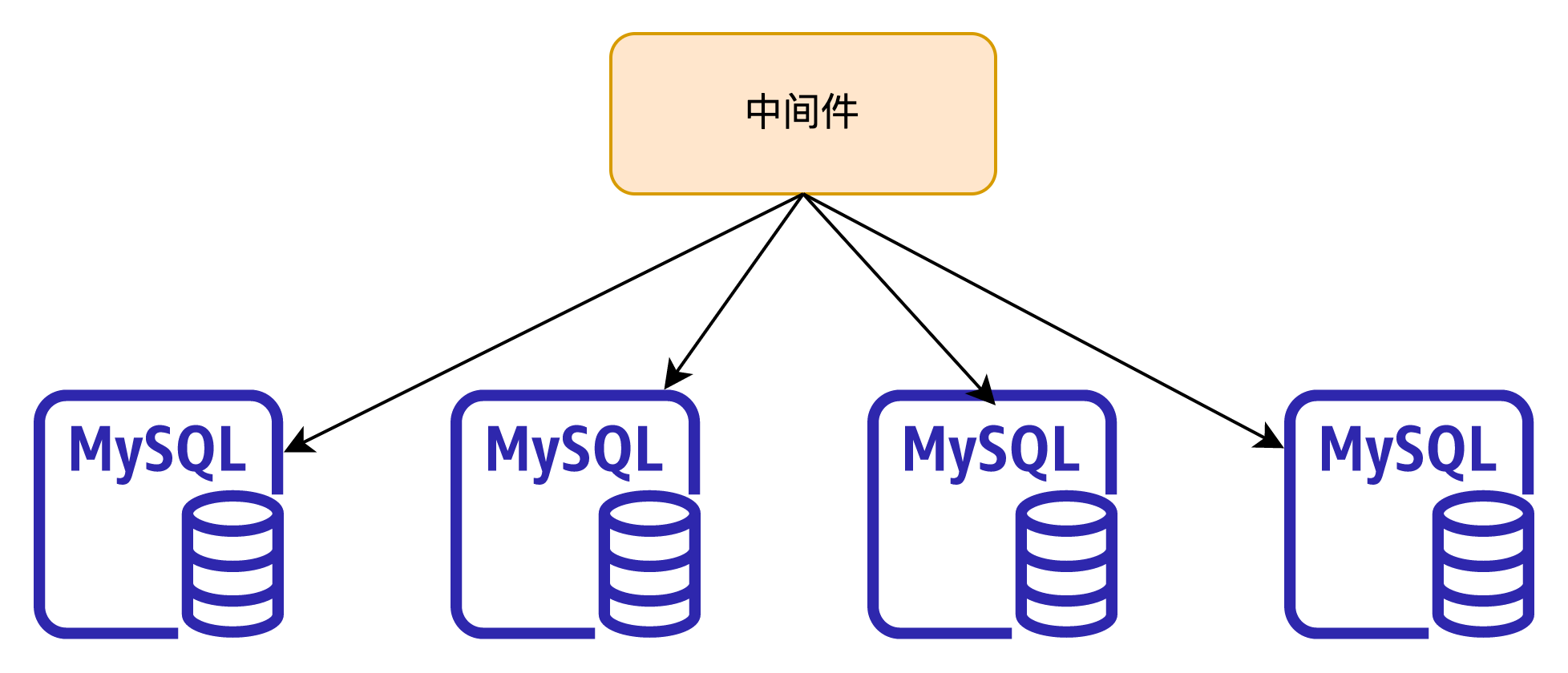
-
PG
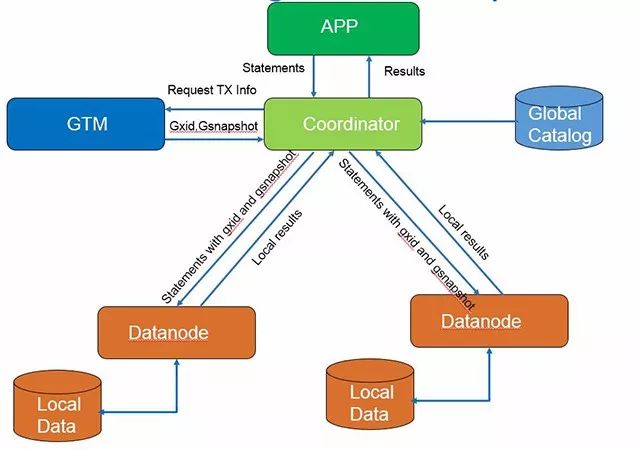
這類分庫分表架構優缺點明顯,數據按表中某一個字段做水平拆分,對于業務簡單查詢維度單一,每次都能帶有這個分片鍵,性能上會有很大優勢,隨著數據節點增加會有很好的線性上升,但問題也很明顯對復雜SQL語句的支持,跨節點查詢數據需要匯總到Proxy或者Coordinator節點,對網絡和CPU都會有較大壓力,通常都需要應用做改造適配可能還會做一些業務妥協。
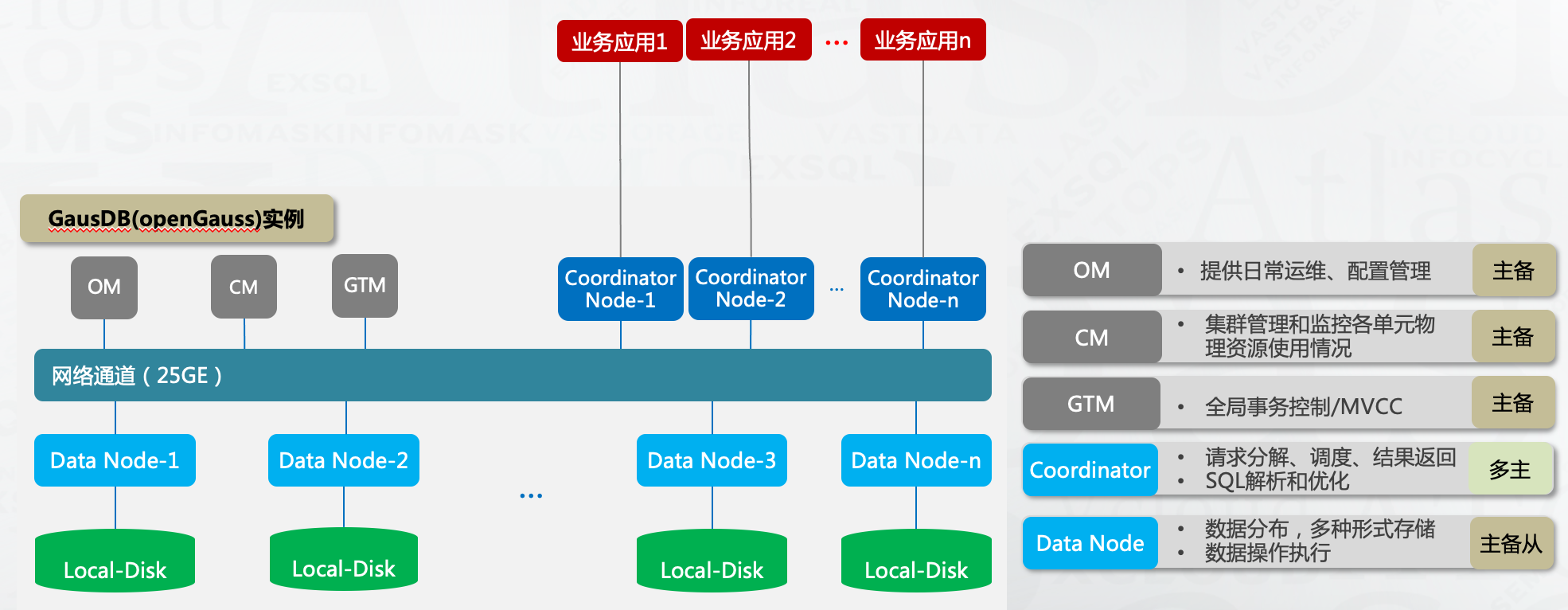
目前PG版本的分庫分表架構已知的都是來自于PGXC,相比MySQL多了GTM節點負責全局一致性快照管理,且Coordinator節點是一個完整的PG數據庫,天然支持SQL語法詞法解析,相對來說對于復雜SQL的支持會好一些。
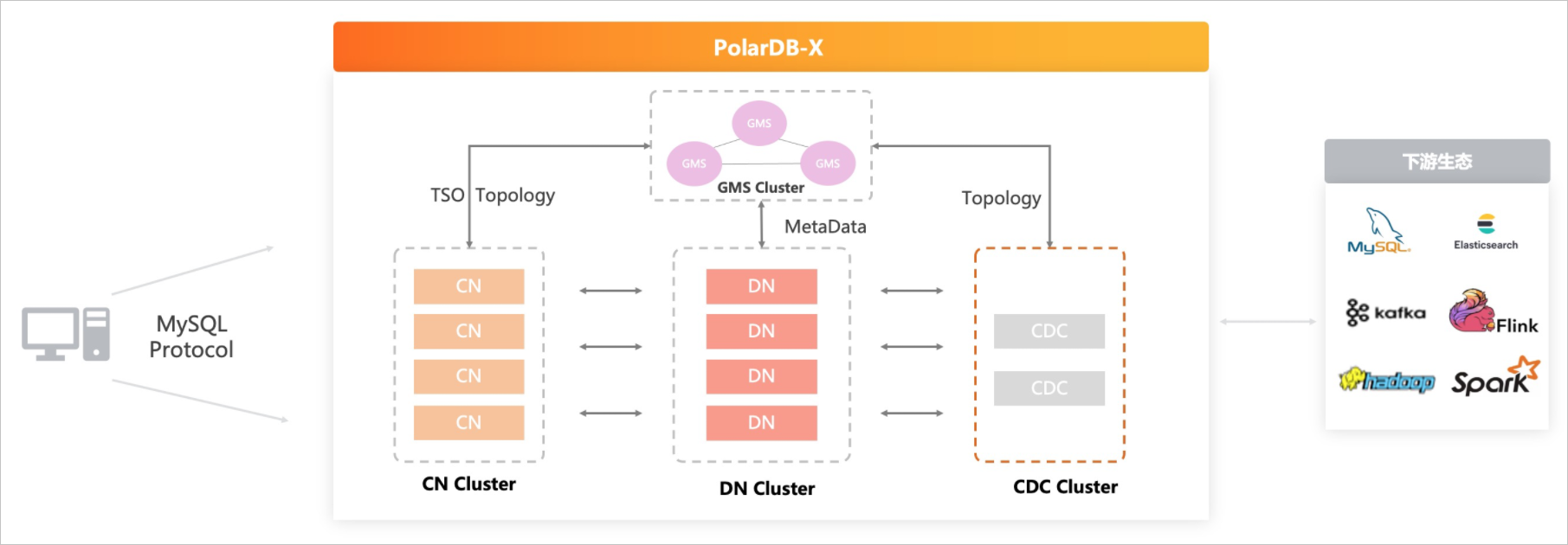
當然阿里的PolarDB-X則有些不同,提供GMS節點作為全局時間戳管理
代表產品:
| 公司 | MySQL | PG |
|---|---|---|
| 騰訊 | TDSQL-MySQL | TDSQL-PostgreSQL |
| 華為 | DDM分布式中間件 | GaussDB for openGauss |
| 阿里 | PolarDB-X |
針對跨節點查詢的SQL,GaussDB for openGauss與TDSQL-PostgreSQL分別提供了Stream流(廣播流、聚合流和重分布流)和數據重分布(Data Redistribution)減少跨節點查詢性能問題,以GaussDB for openGauss為例:
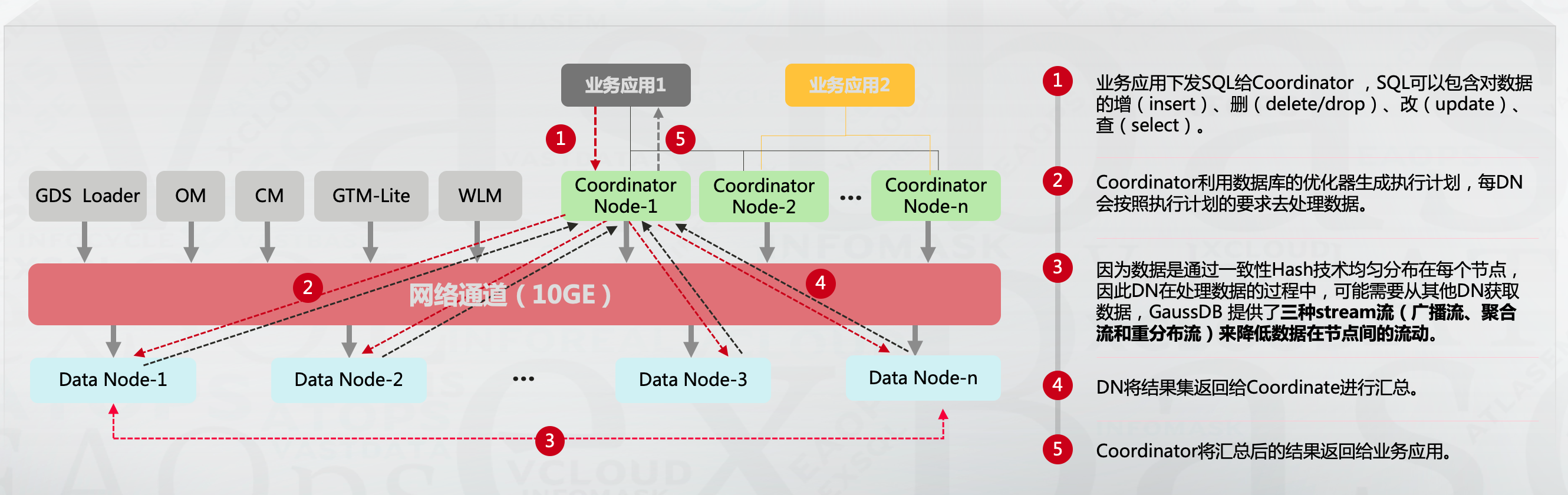
節點之間會做數據交互,盡可能將計算操作offload到數據節點,減少CN節點計算壓力和CN,DN之間網絡流量壓力。這是當前場景的優化方法卸載計算資源壓力。
此外Polardb-X還通過只讀節點,將AP與TP流量進行物理隔離,提供HTAP處理能力
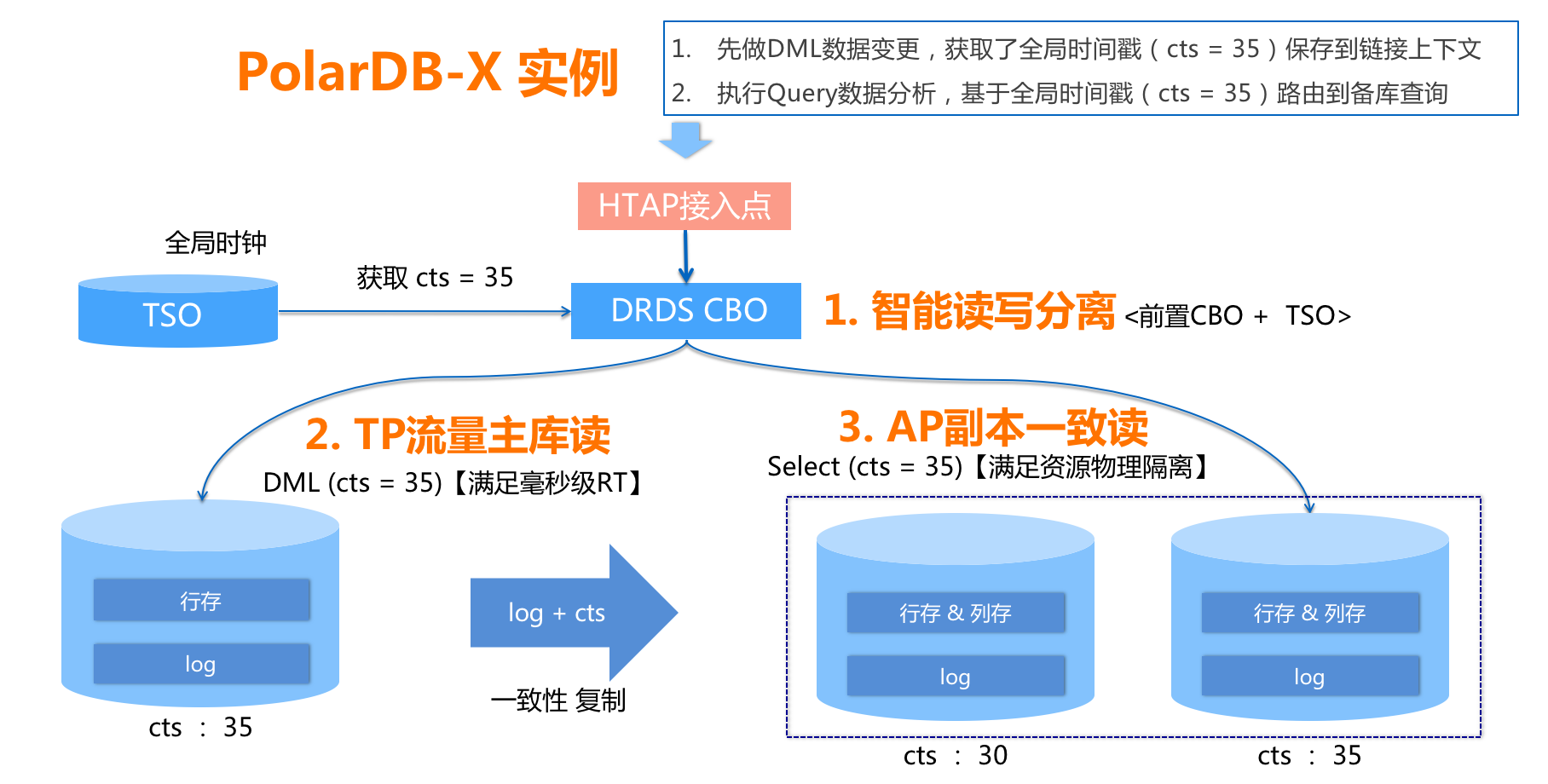
這類架構擴容是比較大的挑戰,根據已有資料的了解MySQL和PG這兩個系列擴容不相同:
MySQL系通常做法是創建表時默認創建256個分片,后面再添加DN節點時通過遷移分片完成擴容,這種做法方便但DN節點數有上限。
PG系的做法是數據重分布,并不是提前在一個DN上創建多個分片,重分布過程通過全量+增量的方式,實現比較麻煩但理論上沒有上限
| TDSQL-MySQL | TDSQL-PostgreSQL | GaussDB for openGauss | PolarDB-X(兼容MySQL) | |
|---|---|---|---|---|
| 動態擴展 | 支持 | 支持 | 支持,需要對等比例擴容 | 支持 |
| 存儲過程 | 不支持 | 支持 | 支持 | 不支持 |
| 物化視圖 | 不支持 | 支持 | 支持 | 不支持 |
| 全局索引 | 不支持 | 不支持 | 不支持 | 支持 |
| 臨時表 | 不支持 | 支持 | 支持 | 不支持 |
| 多租戶(線下部署不帶云底座) | 支持,通過多實例方式 | 不支持 | 不支持 | |
| 觸發器 | 不支持 | 支持 | 支持 | 不支持 |
| 閃回 | 支持 | 不支持 | 不支持 | 支持 |
| Oracle兼容性 | 不支持 | 支持 | 不支持 | 不支持 |
| 節點之間分布式執行 | 不支持 | 支持 | 支持 | 支持 |
| 列存 | 不支持 | 支持 | 支持 | 支持(通過搭建只讀實例) |
TDSQL-MySQL使用限制:https://cloud.tencent.com/document/product/557/47511
PolarDB-X 使用限制:https://help.aliyun.com/document_detail/313262.html
Spanner 架構
Tidb根據Google Spanner和F1做的實現,是一個具備易擴展、高性能、高可靠的NewSQL分布式數據庫,相比分庫分表架構在動態擴容上更加友好,且用戶不需要再考慮分片鍵的選擇,業務不會有很大的改造。
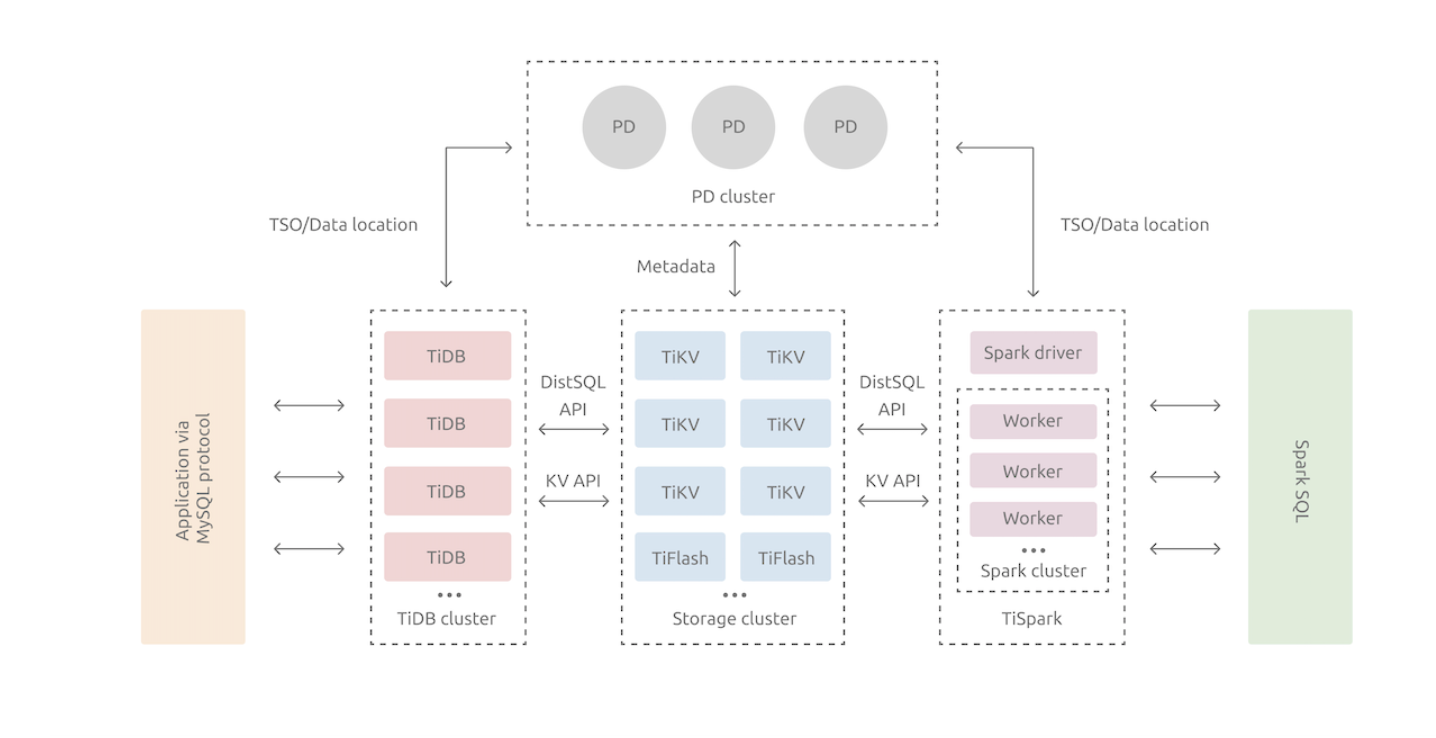
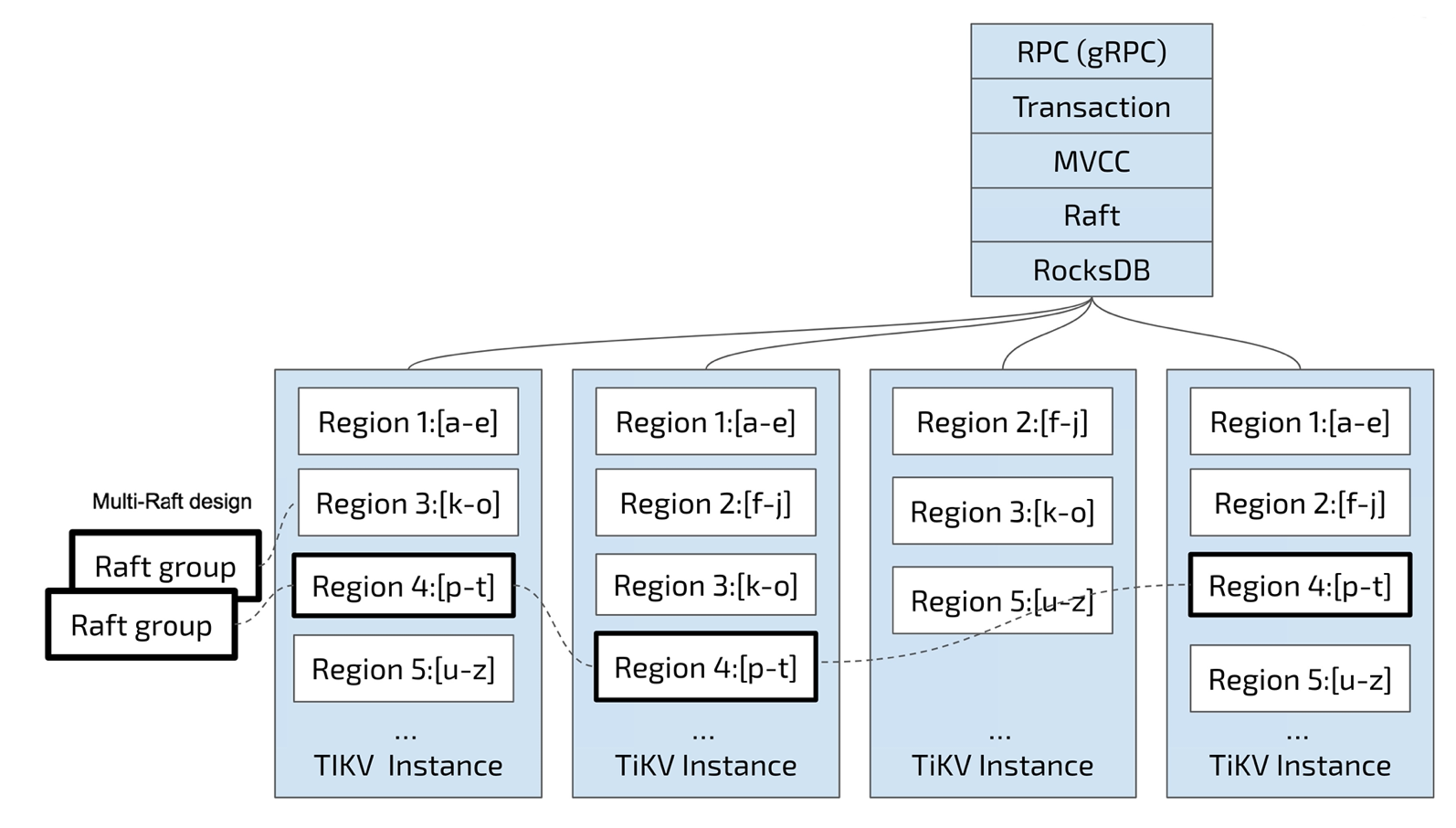
從架構上是 Share Nothing 架構,計算存儲分離,PD負責調度和存儲元數據信息,TIKV存儲層,Tidb接入層
將整個 Key-Value 空間分成很多段,每一段是一系列連續的 Key,將每一段叫做一個 Region,并且 會盡量保持每個 Region 中保存的數據不超過一定的大小,目前在 TiKV 中默認是 96MB。每一個 Region 都可以用 [StartKey, EndKey) 這樣一個左閉右開區間來描述
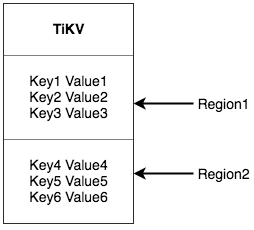
數據按Key切分為多個Region,PD負責將Region盡可能分布到不同的機器上,方便日后的擴容和Region的負載均衡,在Region內部數據是連續存儲的,Region是三副本,使用Raft協議保證了一致性。
PD記錄 Region 在節點上面的分布情況,也就是通過任意一個 Key 就能查詢到這個 Key 在哪 個 Region 中,以及這個 Region 目前在哪個節點上(即 Key 的位置路由信息。
表數據與Key-Value映射關系是將TableID+RowID組成Key,字段作為Value,TableID全局內唯一
Key: tablePrefix{TableID}_recordPrefixSep{RowID} Value: [col1, col2, col3, col4]
索引數據和 Key-Value 的映射關系,主鍵和唯一索引可根據key直接查找對應的RowID定位一條記錄
Key: tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue Value: RowID
普通索引存在多個值,所以根據索引確定一個RowID范圍,再根據RowID查詢到對應Region查詢數據:
Key: tablePrefix{TableID}_indexPrefixSep{IndexID}_indexedColumnsValue_{RowID} Value: null
這點會比分庫分表架構下,沒有根據分片鍵查詢效率高一些。但可能存在熱點數據問題,Region內的數據是順序增長的,很有可能訪問的數據都在一個Region內。
Tidb5.0之后新推出了Tiflash引擎,結合之前的Tikv提供HTAP處理能力,Tidb的這種方案與解析MySQLBinlog同步到具有AP能力的數據庫不同,使用Raft直接同步到Tiflash中,數據一致性上有很大保障
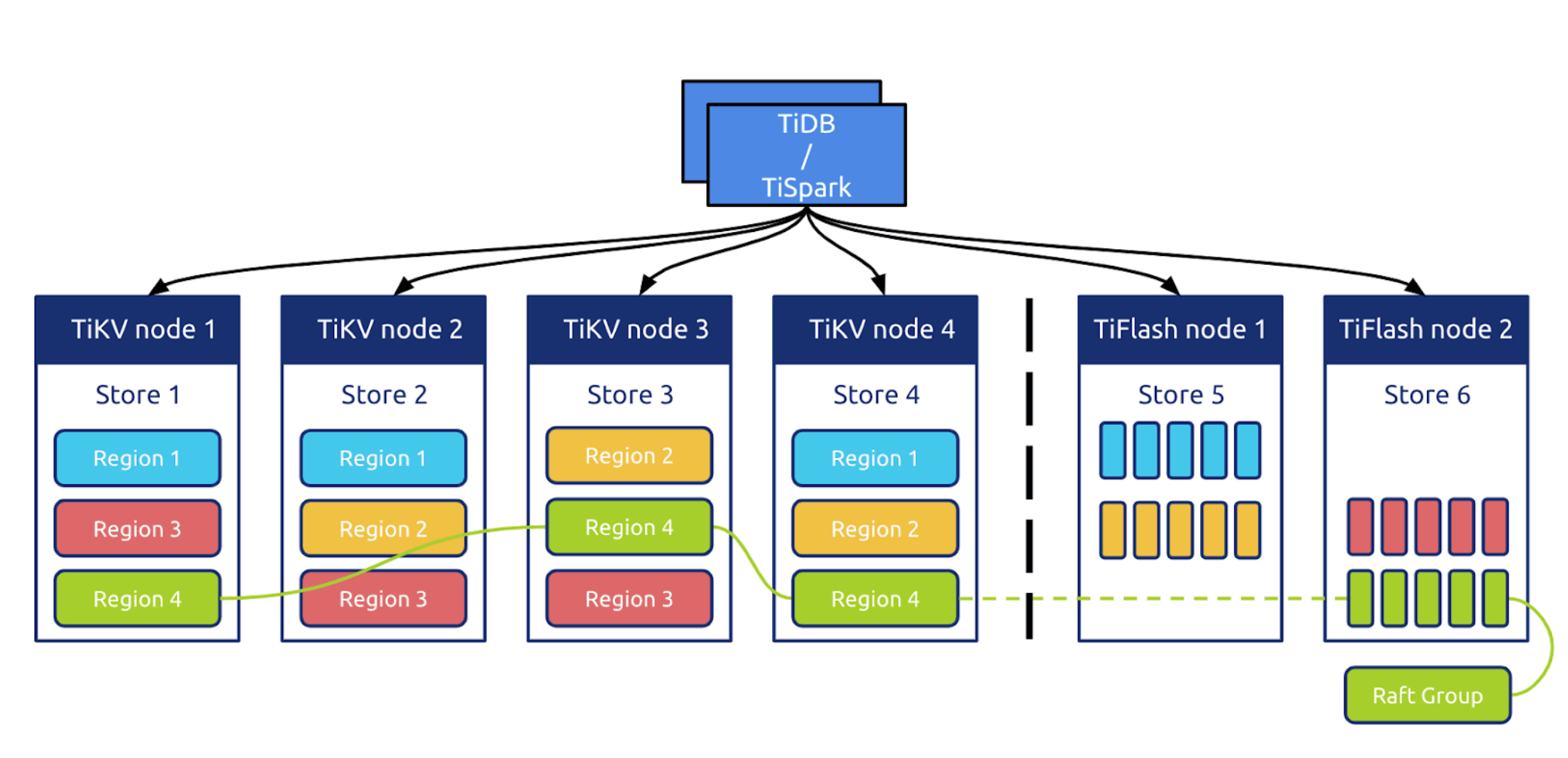
Tidb限制:https://docs.pingcap.com/zh/tidb/dev/tidb-limitations
Tidb與MySQL兼容性對比: https://docs.pingcap.com/zh/tidb/dev/mysql-compatibility
騰訊目前也推出了類架構,TDStore存儲引擎
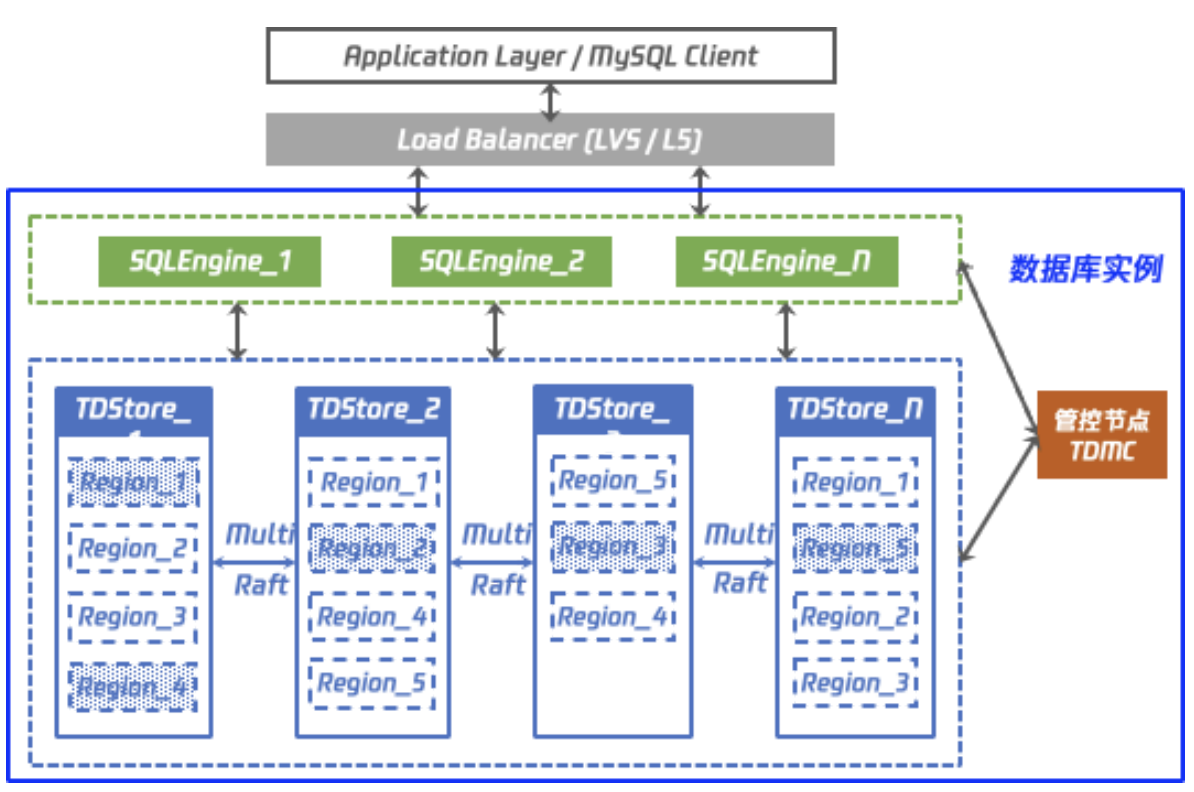
使用限制:https://cloud.tencent.com/document/product/557/63523
這種架構擴容可以通過遷移Region方式,PD節點來負責這個的調度,遷移Region這種會比做數據重分布簡單方便,并且Region也有大小控制,超過閾值后會進行分裂,所以理論上擴容節點是沒有上限。
OceanBase
OB是螞蟻自研的分布式數據庫,OB可以說與國內其它廠商都不同,OB是100%自研并沒有使用任何開源存儲引擎、優化器模塊是真正意義自主可控。架構上OB也與其它架構不同,感覺介于分庫分表和Tidb這兩種架構之間。
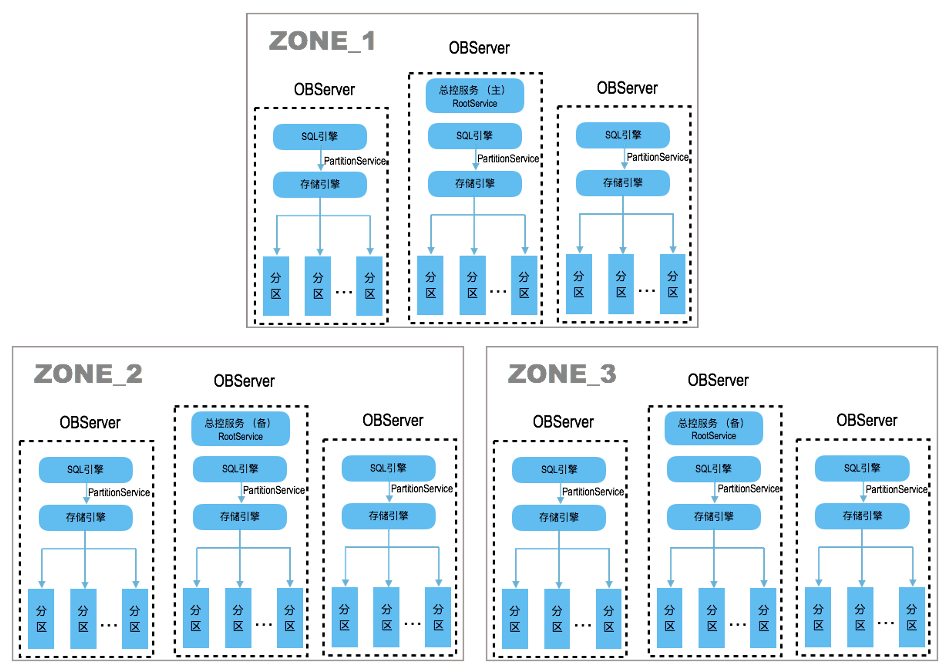
如上圖所示,做一些解釋:
- Zone可認為是不同地區或者不同機房,也可以是同一個機房不同機架,甚至也可以是同一個機架,根據系統和物理環境而定
- 每個Zone內可以是一臺或者多臺OBServer
- 針對每張表可以做分區表,不同的分區表打散到不同的OBServer節點上,所以分區是OB中最小的單元
- 如果不創建分區表,也可以設置以表的維度拆分到不同的OBServer上
下圖更為直觀一些
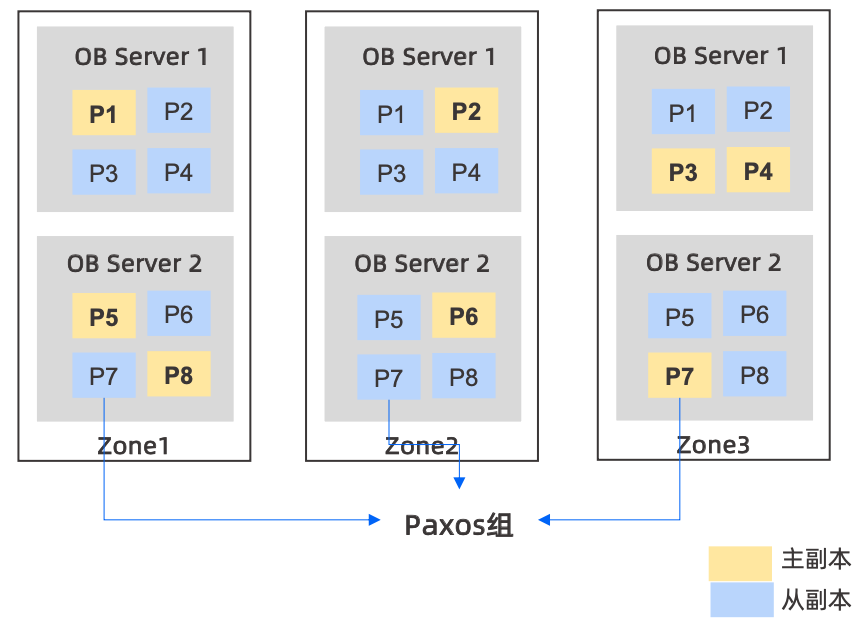
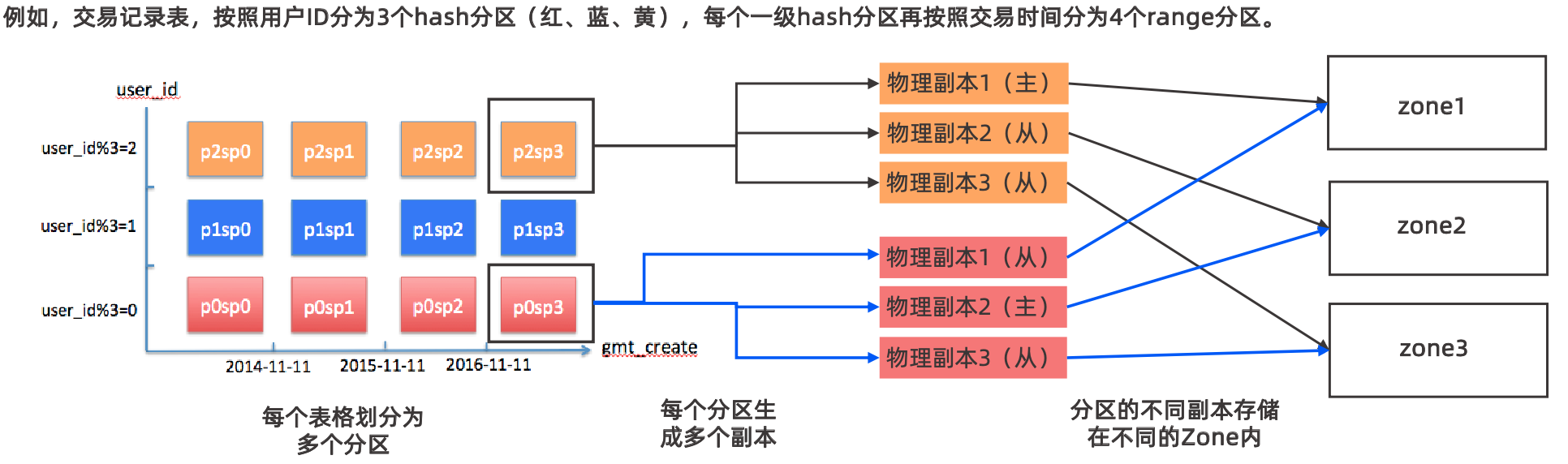
如上圖有3個zone,8個分區,每個zone中有兩個OBServer,每個分區都有三個副本,分布在不同zone中的OBServer上,OB以分區為最小單位組成Paxos組,通過Paxos保證了多副本之間的數據一致性,但Paxos需要多數派提交性能上不一定會比分庫分表好。
這里就需要應用開發階段考慮到分區鍵,其實和分庫分表架構有點像了,都是要用分片鍵定位到某一個分區,如果不帶有分片鍵則可能需要掃描所有分區,當然OB中針對這種問題提供了全局索引功能,解決這種不帶有分區鍵的SQL語句,但全局索引會涉及到分布式事務,對性能有一定影響。
如果不是分區表則會如下圖這種,三個副本之間也是通過Paxos協議保證數據一致性:
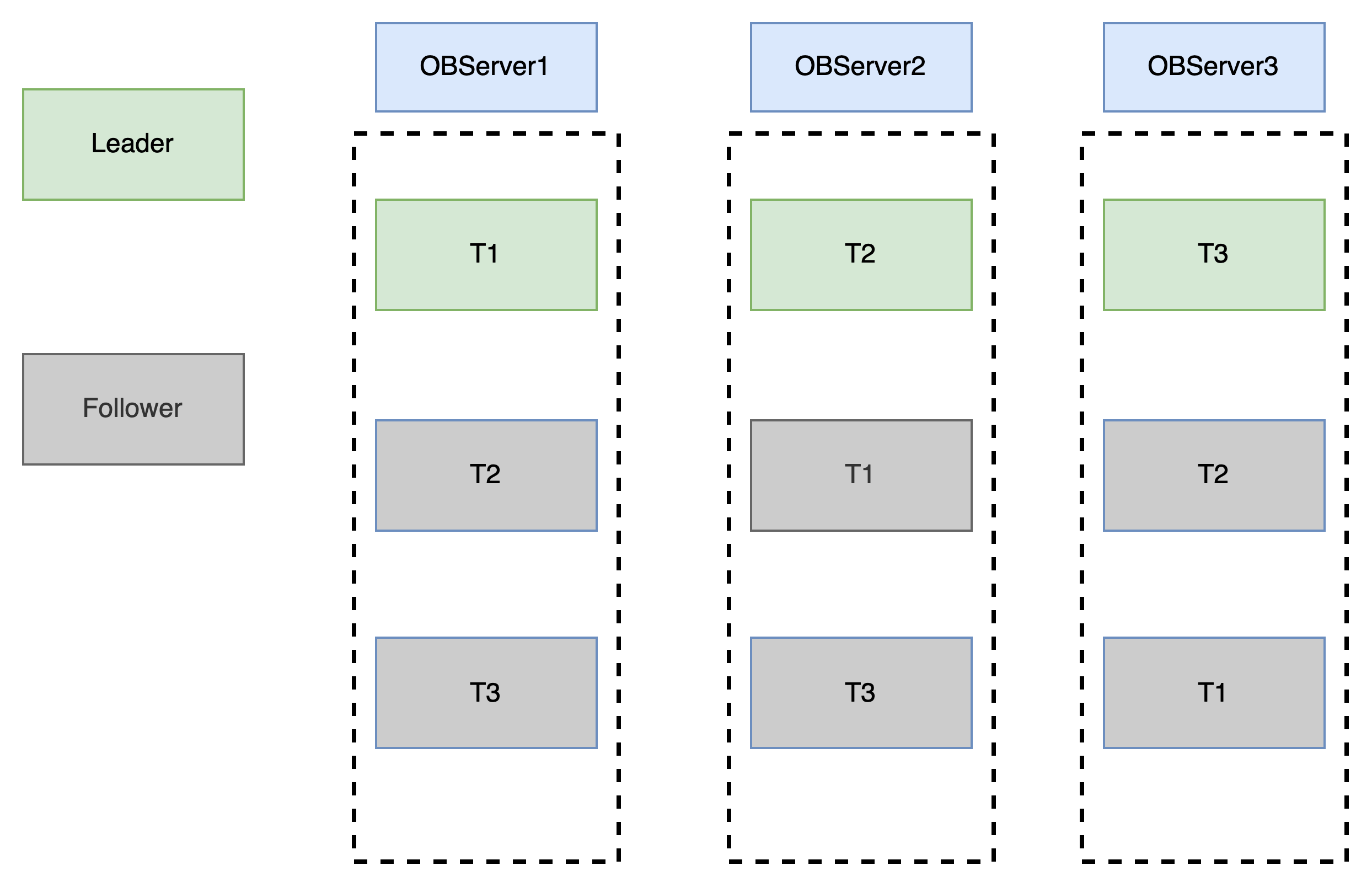
這里可以了解到OB如果的分布式性能提升有兩個維度,表級別和分區級別,表級別這個維度如果所有表訪問流量都很均衡會且每臺機器負載都很高的情況下,有一定負載均衡效果,但如果某幾張表流量很大,那可能效果就不是很明顯,而且還會有遠程通信的延遲。
OB中另外一個特性就是多租戶,類似于Oracle中的PDB,即可在一個OBServer進程內不同的租戶之間資源相互隔離,每個租戶內都有自己的DataBase、Table、View等,這樣在一個OBServer中運行多個應用且相互之間互不干擾,租戶資源都可動態調整。
Tidb與OB存儲引擎是LSM-TREE,針對寫場景均為順序寫會有比較大的優勢,缺點是查詢可能需要掃描多個版本,但OB中有布隆過濾盡量較少這方面影響。另外就是SSTable文件的合并操作會對磁盤IO和集群有一定影響,默認情況下在凌晨2點出發合并操作,需要與跑批時間錯開
Shared-Storage
這類架構靈感來自于AWS 的Aurora,采用計算存儲分離架構,利用軟硬件結合提供高彈性(NVME,RDMA)、高性能、高可用的數據庫服務。
計算存儲分離架構下,底層是分布式文件系統。為保證Partial Transaction(未提交的數據有可能從buffer pool中刷新到磁盤上,導致Secondary節點讀到未提交的數據),Primary節點寫入數據利用Redo同步到Secondary節點,加上利用新型硬件跨越了用戶態的交互。
雖然是單寫,但可滿足大部分應用場景,同時具備以下優點:
- 兼容性:此架構多數的修改都是在存儲引擎層,所以可以100%兼容原有數據庫,應用無需改造,其它分布式架構多數都會需要做一些應用改造。
- 低成本:計算存儲分離,相比以前的一主多備架構,計算資源可單獨增加,無需多購買多余的存儲資源。簡單說:以前一主多備10T的數據庫,在計算資源不夠需要在增加一個備庫提升讀能力,此時需要購買的資源包括計算(8C)和存儲(10T),但這種架構下可單獨溝通一個8C的計算資源即可。
- 彈性擴展:相比主備架構擴展計算資源,不再需要通過備份恢復方式,可做到快速彈性擴展,在一些大促場景下很有用。可以想象一個3T的庫備份去搭建一個從庫多費時間。
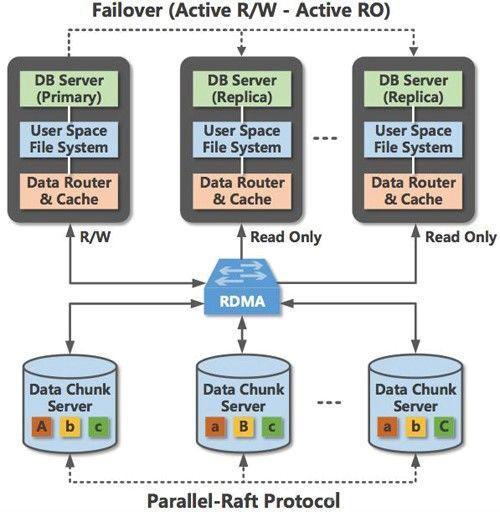
這類架構的產品通常都需要云底座,依賴于底層硬件和文件系統,各廠商代表產品:
| MySQL | PostgreSQL | |
|---|---|---|
| 騰訊 | TDSQL-C MySQL | TDSQL-C PG |
| 阿里 | PolarDB MySQL | PolarDB PG |
| 華為 | GaussDB MySQL |
總結
從國產數據庫發展來看,從分庫分表架構發展時間較長,技術相對成熟且一些ISV廠商已熟悉這類架構開發模式,在一些行業中各類系統已形成了解決方案。Tidb這種NewSQL可作為替代MySQL較好的一種解決方案,在某些行業中ISV開發相對比較薄弱很難做業務改造,Tidb是一個不錯的選擇。PolarDB則充分利用了軟硬件結合,即使在單點寫入情況下也可以得到很好性能,其實國產數據庫當前廠商眾多,如果還延續20年前的架構和存儲引擎很難做到差異化,如果能抓到新硬件帶來的紅利,做出差異化的產品則能領先一大步,從AWS一些資料中發現軟硬件結合也是AWS一直研究和探索的方向。
