




在我工作的地方,一直存在關于生成測試數據的討論。
目前,我們不會替換或更改任何用于測試環境的生產數據,也不會生成測試數據。
因為生產數據是標記化的,上述的做法安全且合法。換句話說,PII和PCI數據正在被持有該占位符的令牌所替代,應用程序可以使用這個令牌通過一種特殊保護服務去訪問受保護的數據。只有一部分有限的人可以處理特殊保護服務后面的數據。
在測試環境中使用生產數據比較高效,因為我們以并行和線性復制數據,或者我們可以開啟寫入時重定向(SSD時代的“寫入時復制”)可寫快照。
假設一下,我們想改變并且想達成以下目的:
- 在復制到測試數據庫時,屏蔽掉一些數據
- 在保持數據參照完整性的同時,減少測試數據庫中使用的數據量
- 在保持參考完整性和一些基本統計屬性前提下,產生任意大小的測試數據集,而不是使用生產數據
制作數據:
假設復制生產數據到測試環境,我們把每個想隱藏的數據復本修改一下數據項,例如用sha(“secret” + original value),或者一些其它的替換令牌。
kris@localhost [kris]> select sha(concat("secret", "Kristian K?hntopp"));
+---------------------------------------------+
| sha(concat("secret", "Kristian K?hntopp")) |
+---------------------------------------------+
| 9697c8770a3def7475069f3be8b6f2a8e4c7ebf4 |
+---------------------------------------------+
1 row in set (0.00 sec)
為什么我們用一個哈希函數或者等價的公式來實現?我們當然是想保證數據的參照完整性。所以每個Kristian K?hntopp將被9697c8770a3def7475069f3be8b6f2a8e4c7ebf4代替,這是一個可以預測且穩定的值,而不是在第一次產生一個隨機的數字17,第二次則產生一個隨機數字25342.
關于數據庫工作,表示在復制完數據完成后,我們更新數據的每一行記錄,并且為每次更新創建一個binlog記錄。如果被修改的列存在索引,那么包含對應列的索引也應該被更新。如果我們更改的列是主鍵,則該記錄的物理位置也會被修改,因為InnoDB將數據聚集在主鍵上。
簡而言之,雖然復制數據很快,但屏蔽數據的成本要高得多,而且在任何硬件上都無法以線速運行。
減少數據量
在公司歷史的早期,大約 15 年前,一位同事致力于通過選擇生產數據的子集來創建更小的測試數據庫,同時保持參照完整性。 他失敗了。
許多其他人后來嘗試過,我們有項目大約每 3 到 5 年嘗試一次。 他們也失敗了。
每次嘗試總是選擇一個空數據庫或生產中的所有數據。
這是為什么?
讓我們來看一個簡單的模型:有用戶,酒店,他們的關系是n:m。
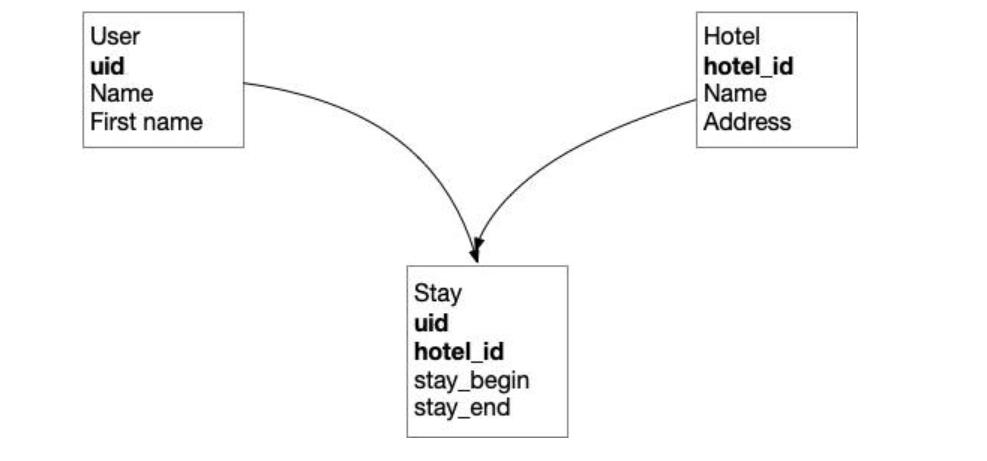
“克里斯”住在“卡薩”酒店。我們從生產環境中選擇Kris進入測試數據集,酒店也選擇“Casa”。 其他住在 Casa酒店的客人,他們也被導入到測試數據集中,由于這些客人也住在其他酒店,所以這些酒店也被導入。 經過3次反射,6次轉換,結果我們選擇了整個生產數據庫進入測試集。
由于我們的生產數據是相互關聯的,保持生產數據的參照完整性將意味著選擇一個最終選擇所有。
限制時間范圍會對前述情況有所幫助:我們只選擇過去一周或其他時間的數據。但這還有其他含義,例如在數據分布方面。此外,在可用性操作方面,我們的生產數據在時間上存在嚴重不均勻的,如上周發生了很多預訂。
生成測試數據
生成垃圾數據很快,但仍然比復制慢。 這是因為從生產機器復制數據不僅要復制二進制文件,還需要預建存在的索引,對比生成垃圾數據相當于導入mysqldump。需要解析數據,更糟糕的是,需要構建所有索引。
雖然我們可以以每秒數百MB的速度復制數據,最高可達GB/s范圍,但導入數據的速度為個位數MB/s,還是達幾十MB/s,很大程度上取決于 RAM 的可用性、磁盤的速度、索引的數量以及輸入數據是否按主鍵排序。
生成良好的數據比較難,且效率也低。
你需要定義或從模式推斷出的引用完整性約束列表。 在工作中,我們的模式很大,比單個數據庫或服務大得多——用戶服務(測試用戶服務,帶有測試用戶數據)中的用戶需要在預訂服務(帶有測試預訂的測試預訂服務)中被引用,引用 到酒店中測試房源和測試酒店商店。
這意味著要么為每個測試創建和維護一個一致的第二個環境,要么跨服務從頭開始創建這個。 一個是對生產力的拖累(保持一致的環境需要大量工作),另一個是緩慢的。
但是,一致性并不是唯一的要求。 如果您想測試驗證代碼,一致性很好(但我的測試名稱不是 utf8,它們來自 ASCII 的十六進制數字子集!)。
但是如果要談性能,就會出現額外的要求:
- 數據大小
如果您的生產數據大小為 2 TB,但您的測試集為 200 GB,那么它的速度并不會線性提高 10 倍。 這種關系是非線性的:在給定的硬件上,生產數據可能會受到 IO 限制,因為工作集無法放入內存,而測試數據可以將 WSS 放入內存。 生產數據將產生與負載成比例的磁盤讀取,測試數據將從內存運行,預熱后沒有讀取 I/O——應用完全不同的性能模型。 對測試數據的性能測試對生產性能的預測價值為零。
- 數據分布
生產數據和生產數據訪問受制于很大程度上未知和未記錄的數據訪問模式,并且也在不斷變化。 一些用戶像是鯨魚,他們的遍歷數據次數是正常標準的100倍,而其他一些用戶是經常遍歷的人,他們的訪問數據的次數是平時的10倍。 一些用戶是一次性的,在數據集中只出現一次。 這些集合之間的關系是什么,它們對數據訪問有什么影響?
例如:
我丟失的數據庫基準
德國計算機雜志c‘t在2006年有一個應用程序基準,描述了對DVD租賃商店的Web請求訪問。參賽者應該使用他們希望的任何技術編寫DVD出租商店,在所需的輸出和他們將在測試中暴露的URL請求中定義。我希望作為MySQL顧問想參與其中,為此我將提供的模板放入使用MySQL的網上商店,并相應地調整商店和數據庫。
我沒進入前10名。
那是因為我使用了一個真實的網上商店,對用戶行為有真實的假設,包括緩存和物品。
生成所使用的測試數據,并且平均分配請求:模擬DVD商店中的每張 DVD 被租用的可能性相同,并且每個用戶租用的DVD數量相同。您放入存儲中的任何緩存都會溢出并進入脫粒狀態,或者必須有足夠的內存才能將整個存儲保存在緩存中。
真正的DVD出租店擁有前100名的熱門影片,而且還有一條長長的尾巴。緩存有幫助。在測試中,緩存破壞了性能。
我丟失的另一個數據庫基準
另一本德國計算機雜志有另一個數據庫基準測試,它基本上以非常高的負載錘擊被測系統。不幸的是,這里的負載分布不均,但是經常使用一些鍵,而從未請求過很多鍵。 實際上,負載生成器有大量線程,每個線程都在使用數據庫中的“他們的”鍵——線程1到表中的 id 1,依此類推。
這鍛煉了一定數量的熱鍵,并在幾個鎖上等待非常快,但實際上并沒有準確地模擬任何吞吐量限制。 如果您以更多類似生產的負載運行系統,它的總吞吐量將增加大約 100 倍。
TL和DR
生成用于測試的掩碼或模擬數據的計算成本比復制生產數據的計算成本高 100 倍左右。 如果生產數據已經被標記化,那么與所花費的努力相比,勝利也是值得懷疑的。
生成有效的測試數據在計算上是昂貴的,尤其是在要跨服務邊界維護引用完整性的微服務架構中。
有效的測試數據在測試中不一定有用,尤其是在性能測試方面。 性能測試還特別依賴于影響鎖定時間的數據訪問模式、工作集大小和到達率分布。
最后,實際的測試環境始終是生產環境,以我個人的專業經驗,使生產中的測試安全比生產準確的測試環境更有價值。
原文標題:MySQL: Data for Testing
原文作者:KRISTIAN K?HNTOPP
原文地址:https://blog.koehntopp.info/2022/09/26/mysql-data-for-testing.html
