




前言
–
在日常運維過程中,經(jīng)常發(fā)現(xiàn)操作系統(tǒng)使用率高的情況,碰倒這種問題如果通過top命令能看到明確的占用內(nèi)存高的進程還好,好多使用并不能直接看出來哪個進程占用內(nèi)存高,或者說知道占內(nèi)存高,但是不知道原因或者如何處理,這就比較難受了。本文總結(jié)了我日常運維過程中碰到的內(nèi)存使用率高的情況,以及我個人的一個排查思路,主要針對linxu平臺,希望對大家有幫助,由于能力有限,難免有解釋的不對的地方,也歡迎大家在評論區(qū)批評指正。
問題分析工具
linux系統(tǒng)中能查看內(nèi)存使用情況的命令有很多,如top、free、vmstat或者查看/proc/meminfo,關(guān)于這些命令的具體使用方法就不在仔細介紹了,我只想說幾個不容易被大家熟知的知識點:
1、top命令顯示的輸出,可以按shift+m按內(nèi)存使用率排序。
2、free命令顯示如果swap有被使用到,并不一定是當前真正的被使用到了,而有可能是之前由于某些原因被使用過,而后內(nèi)存使用降下來了,這個used值并不會再變回0,只有重啟才能使這個值變成0。
3、如果想看當前內(nèi)存和swap使用的情況,可以用vmstat,重點關(guān)注swap和memory列的變化。
4、free命令顯示的available是linux內(nèi)核評估出來的當前系統(tǒng)的可用內(nèi)存,跟used、free、buffer、cache并沒有直接的關(guān)系,由于linux內(nèi)存管理很復(fù)雜,所以這個值跟以上值的大小比較沒有任何意義!!!我們只要知道available是內(nèi)核評估的內(nèi)存剩余量,相對來說比較有參考意義。
這里想重點介紹一個我經(jīng)常使用的內(nèi)存分析工具—smem。smem是Linux系統(tǒng)上的一款可以生成多種內(nèi)存耗用報告的命令行工具。與現(xiàn)有工具不一樣的是smem可以報告實際使用的物理內(nèi)存(PSS),這是一種更有意義的指標。可以衡量虛擬內(nèi)存系統(tǒng)的庫和應(yīng)用程序所占用的內(nèi)存數(shù)量。由于linux使用的是虛擬內(nèi)存管理技術(shù),所以無論從top、vmstat都很難看出每個進程的真是內(nèi)存占用情況,使用smem可以更好的衡量內(nèi)存的占用情況。這個工具使用方法網(wǎng)上也有很多介紹,我也不過多說了主要是解壓就能用。
[root@docker01 tmp]# tar -xzvf smem-1.4.tar.gz
smem-1.4/.hg_archival.txt
smem-1.4/.hgtags
smem-1.4/COPYING
smem-1.4/smem
smem-1.4/smem.8
smem-1.4/smemcap.c
[root@docker01 tmp]# cd smem-1.4
[root@docker01 smem-1.4]# ls
COPYING smem smem.8 smemcap.c
[root@docker01 smem-1.4]# chmod +x smem
[root@docker01 smem-1.4]# ./smem -t -k >res_smem =====================>這個就可以直接打開看了
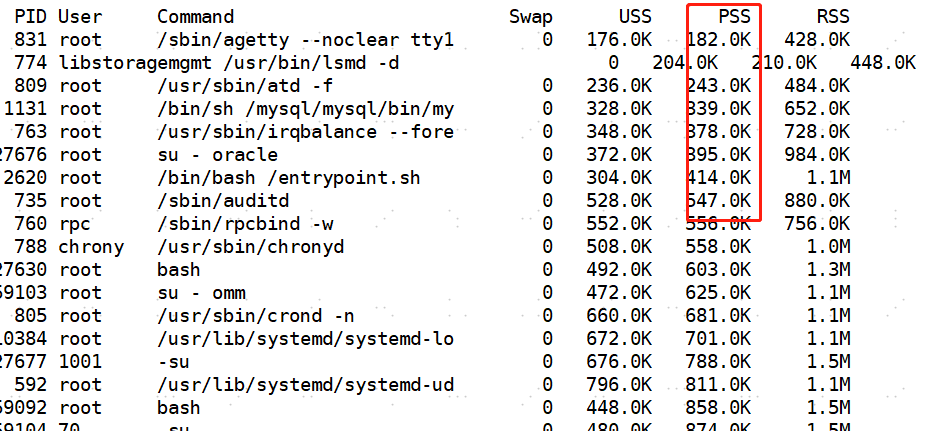
我們要關(guān)注PSS列,這一列基本上就是去掉共享內(nèi)存實際占用的內(nèi)存的情況,RSS是包含共享內(nèi)存值。
內(nèi)存使用率高的幾種情況
一、操作系統(tǒng)systemd-journal進程占用較大內(nèi)存
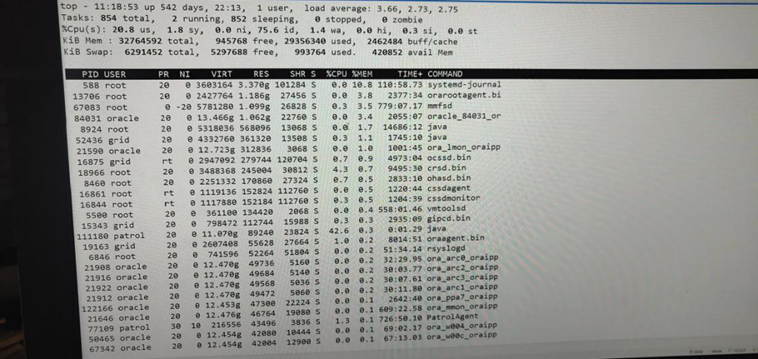
操作系統(tǒng)進程systemd-journald提供日志功能,默認配置是在內(nèi)存中存儲日志記錄,最大占用4G。RedHat官方給出了systemd-journald對性能的負面影響及其緩解措施,按照建議,將內(nèi)存占用最大值縮小至500M。但是根據(jù)生產(chǎn)實際測試,即使將該值限制到500M,systemd-journald占用內(nèi)存依然會超過500M,這也是紅帽的一個bug,這個就需要打補丁解決。也可以通過重啟該服務(wù)環(huán)境此問題。
二、操作系統(tǒng)未配置大頁
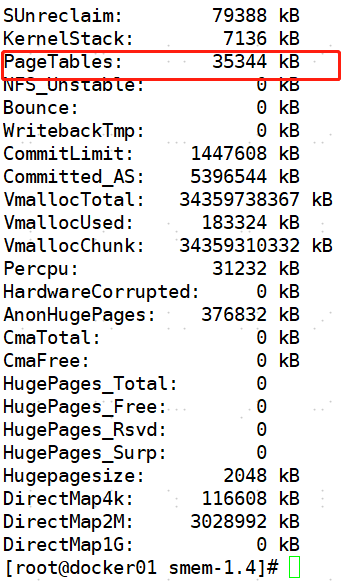
設(shè)置了大頁以后,只有能使用大頁內(nèi)存的程序才能使用該內(nèi)存,而大頁內(nèi)存在配置以后,系統(tǒng)啟動后立馬進行分配出在oracle數(shù)據(jù)庫的最佳實踐中,如果SGA比較大,會建議配置大頁,大頁內(nèi)存是集成在Linux 2.6內(nèi)核的一個特性。與傳統(tǒng)的4K頁面相比,啟用大頁內(nèi)存可以使操作系統(tǒng)支持更大的頁面。使用大頁內(nèi)存將會減少系統(tǒng)維護page table entries(頁表條目,PTE)所消耗的資源,從而提高系統(tǒng)性能。大頁內(nèi)存對于32位和64位的配置都有用。大頁內(nèi)存的大小從2MB到256MB不等,依賴于內(nèi)核版本和硬件架構(gòu)。對于Oracle數(shù)據(jù)庫,使用大頁內(nèi)存可以減少操作系統(tǒng)對頁面狀態(tài)的維護,并且能夠提升Translation Lookaside Buffer (頁面緩沖,TLB)的命中率。如果沒有配置大頁,而SGA又特別大,很有可能導(dǎo)致pte占用特別大的內(nèi)存,這個可以通過查看/proc/meminfo中的PageTables確認。
三、操作系統(tǒng)大頁配置不合適
設(shè)置了大頁以后,只有能使用大頁內(nèi)存的程序才能使用該內(nèi)存,而大頁內(nèi)存在配置以后,系統(tǒng)啟動后立馬進行分配出去,比如配置了30G的大頁內(nèi)存,這部分內(nèi)存在os啟動后就被分配出去了,即使數(shù)據(jù)庫沒有啟動,我們從free命令看used就是30G。如果你的SGA配置了10G,那相當于有20G的內(nèi)存是被浪費掉的,因為沒有別的進程能占用這個20G內(nèi)存。所以在配置大頁的時候,一定要規(guī)劃好os內(nèi)存和數(shù)據(jù)庫內(nèi)存的關(guān)系。
四、oracle 12c的mgmt的bug
在Oracle 12c 中Management Database 用來存儲Cluster HealthMonitor(CHM/OS,ora.crf) ,Oracle Database QoS Management,Rapid Home Provisioning和其他的數(shù)據(jù)。ManagementRepository 是受12c Clusterware 管理的一個單實例,在Cluster 啟動的時會啟動MGMTDG并在其中一個節(jié)點上運行,并受GI 管理,如果運行MGMTDG的節(jié)點宕機了,GI 會自動把MGMTDB 轉(zhuǎn)移到其他的節(jié)點上。這個東西在oracle12c安裝的時候是必選項,在19c的時候又變成了可選項,在實際生產(chǎn)中是沒啥用處的。而且這個實例的mmnl進程存在內(nèi)存泄漏的bug,
有三種方案解決該問題:
1、 kill掉該進程,因為mmnl進程會自動啟動,所以kill掉以后釋放的內(nèi)存會慢慢再次被mmnl進程占有,只能定時關(guān)注該進程,定時kill。
2、安裝補丁28831971,需要下載安裝對應(yīng)當前數(shù)據(jù)庫psu版本的補丁,具體有效性需要測試后觀察。
3、關(guān)閉mgmtdb,關(guān)閉后對數(shù)據(jù)庫沒有影響,只有在升級psu的時候需要再次打開mgmtdb。
五、oracle 19c的進程bug
oracle經(jīng)常會有一些后臺進程出現(xiàn)內(nèi)存泄漏的bug,我在生產(chǎn)中碰到的一個bug是bug 31425761 ,這個bug會導(dǎo)致mmon的worker process(m000、m001、m002、m003…)出現(xiàn)pga內(nèi)存的泄漏,一般會有四個類似的進程,
我見過比較夸張的是每一個進程占用的內(nèi)存到了3g多,總共15g的內(nèi)存的泄漏。根據(jù)mos上的處理方案是需要打補丁,我們一般的應(yīng)急操作就是kill相關(guān)進程,oracle會自動把進程拉起來,沒碰到有不好的影響。
六、buffer/cache占用比較高
在內(nèi)存調(diào)度中,buff/cache主要用于緩存讀寫文件系統(tǒng)的數(shù)據(jù)。所以,如果內(nèi)存使用率處于較高水平,且buff/cache占用較高時,可以執(zhí)行slabtop -s c命令查看詳細信息,查看輸出內(nèi)容的CACHE SIZE項,找到占用較多的內(nèi)核調(diào)用。從內(nèi)核調(diào)用的名稱(NAME項),可以判斷出占用較大內(nèi)存是xfs文件系統(tǒng)或是nfs文件系統(tǒng)等。這種一般就是服務(wù)器對文件有較多的IO操作,使用率內(nèi)存作為cache加速。這種情況就要針對具體的進程具體分析了,可以通過重啟os臨時緩解或者擴容。
七、oracle adg的進程bug
生產(chǎn)上碰到過一次oracle adg的bug,從12c開始oracle的后臺進程TTnn進程用來傳輸redo log到備庫,這個進程在某個版本上會存在內(nèi)存泄漏的bug,具體bug號記不太清楚了,如果碰到該進程有內(nèi)存泄漏的情況,可以殺掉該進程,oracle會自動把該進程拉起來,基本上沒有不好的影響。
總結(jié)
1、以上碰到的內(nèi)存問題,大部分可以通過定期重啟os解決,所以我個人覺得,定期重啟操作系統(tǒng)還是非常有必要的,即使是linux。我們好多系統(tǒng)怕麻煩不重啟,這種其實風險還是挺大的。有些上千天沒重啟的服務(wù)器,哪天真正需要重啟的時候,有可能就起不來了,不如找個時間充足的窗口重啟一下,排除下風險。
2、oracle數(shù)據(jù)庫的很多進程內(nèi)存泄漏的bug,我的很多操作方案是kill進程,這種操作并不受官方支持的,對于不重要的系統(tǒng)可以實施,重要系統(tǒng)還是按照官方的思路打補丁解決。
