




最近的一套PostgreSQL(12.6)數據庫在進行UAT測試的時候,發現服務器空間爆滿,導致了PostgreSQL異常關閉。問題發生后,現場的DBA讓我配合做了如下的一些分析,這里去除敏感信息,分享給大家。
一、問題分析
問題發生的時候,現場的DBA其實經過檢查發現了暴漲的源頭是這個pgsql_tmp目錄,
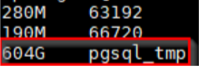
而且現場的DBA在PostgreSQL異常關閉前,用strings去看pgsql_temp里面的文件,確認是對應的數據,而且根據文件的命名方式,通過pid查詢到了產生臨時文件的SQL,SQL是一個select語句,并且涉及到fdw遠程表,這方便了我們后續對問題的分析。

select * from pg_stat_activity where pid='24518';
通過查看這個SQL的執行計劃,我們可以看到有兩個sort環節,而且都是在PostgreSQL端執行的。
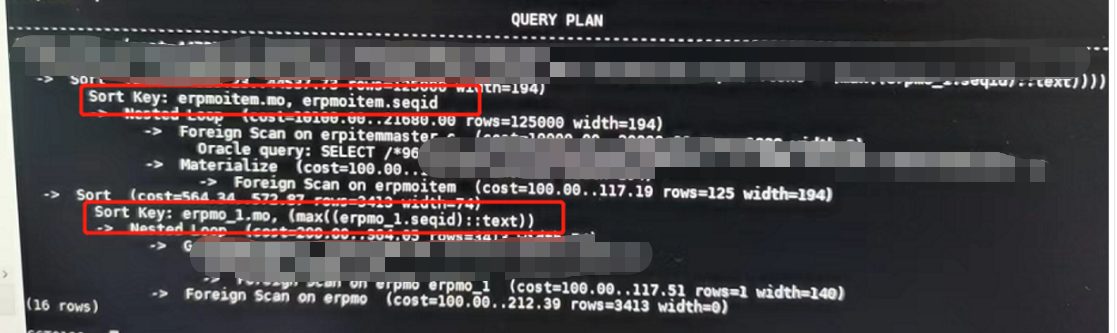
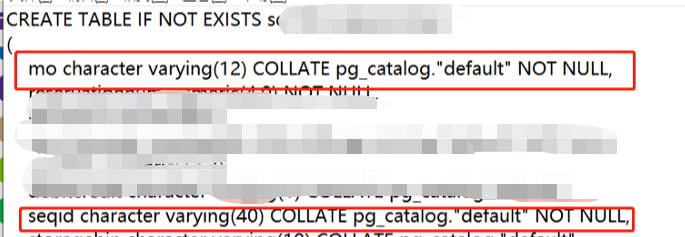
然后看一下涉及的sort列的表的情況,發現這幾列都是字符類型的。要知道oracle_fdw的排序字段是字符類型的時候是不會不下推到oracle端的,但是數字和時間類型都是可以的,因此這個SQL的排序他會先把數據拿到PostgreSQL的內存里,即work_mem里去做這個sort操作。
下推:FDW采用一種稱為 pushdown 的機制,它允許遠程端執行 WHERE、ORDER BY 和 JOIN 子句。下推 WHERE 和 JOIN 減少了本地和遠程服務器之間傳輸的數據量,避免了網絡通信瓶頸。
到這里,我和現場DBA確認了下他們work_mem的大小,經過確認,他們work_mem的值為4MB,也就是默認值,對于這個SQL來說,work_mem明顯太小了,這個參數是寫入臨時文件之前內部排序操作和散列表使用的內存量,超出后,就會溢出到磁盤寫到pgsql_tmp下的臨時文件里,當開始將臨時文件寫入磁盤時,顯然會比內存慢得多,而且臨時文件的太大也可能把空間填滿。
其實可以在啟用log_temp_files后,在PostgreSQL日志中搜索temporary file來查看是否溢出到了磁盤。如果看到了temporary file,就意味著可能需要增加work_mem了。
而且不容忽視的一點是:work_mem這個參數和max_connection是有聯系的,假設你設置為10MB,則500個用戶同時執行查詢排序,很快就會使用5GB的實際內存。或者涉及復雜計算,涉及幾張表的合并,就要用到幾倍的work_mem。因此work_mem是不適宜設置的很大的,如果設置超出256MB,其實很容易因為瞬間的大并發操作導致OOM問題
此外,其實可以通過使用explain analyze 這個SQL去查看這個它執行所需要的內存大小,但生產的環境基本不允許我們隨意explain analyze,因為它會實際執行SQL,如果是問題SQL,不僅可能影響數據庫性能、嚴重甚至造成宕機。而且explain analyze命令跟insert、update、delete的操作更是會修改數據,這是我們絕對不能做的。
下邊我在自己的測試環境給大家演示一下,work_mem對于執行計劃的影響,我原本的work_mem值也是4MB沒有修改:
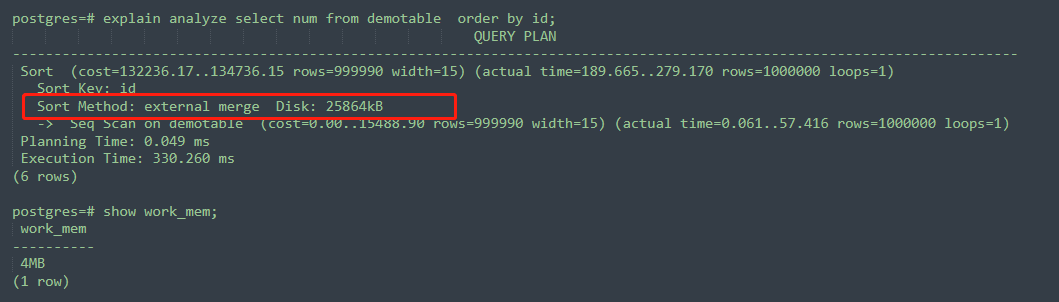
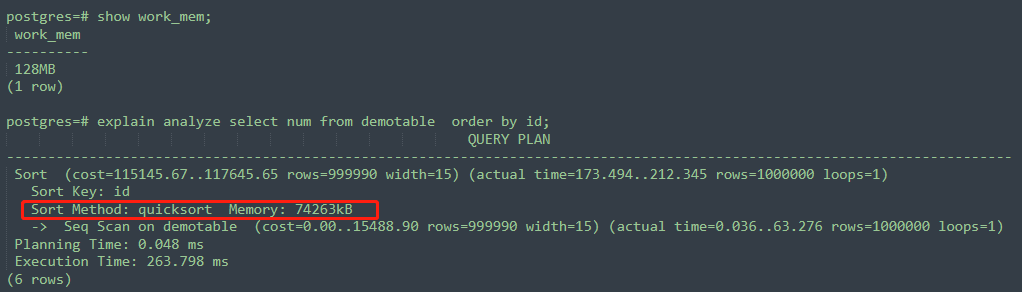
可以看到,這個SQL的執行計劃里,Sort Method部分是external merge Disk,代表了外部合并磁盤,也就是溢出到了磁盤,生成了臨時文件。可以看到這個SQL的執行計劃里Disk:25864KB,大概有25MB,那我work_mem的值改成128MB,會怎樣呢 ,如下所示,相同的SQL,Sort Method部分變成了quicksort Memory ,此時sort的數據都是放在內存里的,而沒有溢出磁盤。
二、結論
通過上面的分析,我們知道這次的問題,主要是出在了oracle_fdw處理SQL的sort操作的的時候字符類型不能下推,而且在PostgreSQL本地進行sort的時候,超出了work_mem的設置,導致溢出到磁盤,我們可以把work_mem的值稍微提升一點,但一定不要過大,否則業務的瞬間高并發很可能導致OOM。而且對于work_mem的大小我們肯定是要根據平時的業務以及并發量來綜合評估的,基本確定了一個值不會去輕易改動,不能對于個別SQL進行調整,這樣也不利于數據庫的穩定性。因此,最好的方式還是結合業務看是否這條SQL能進行調整,修改sort的列的類型,或者調整寫法讓其能下推到oracle端執行,減少傳輸到PostgreSQL本地的數據量。除此之外我們也可以使用temp_file_limit這個參數對此類臨時文件的大小做一個限制,避免數據目錄的爆滿。
