




Data Guard的架構
Table of Contents
概述
Primary Database主庫
處于open狀態(tài)對外提供服務,用戶在Primary Database 上進行操作,操作被記錄在聯(lián)機日志和歸
檔日志中。
需要設置 logging force 模式:
即使在歸檔模式下,也可能會有一些有nologging的操作不產(chǎn)生redo,這在DG下是不允許的,因此
必須啟用數(shù)據(jù)庫強制記錄redo。
Standby Database備庫
處于恢復狀態(tài),接收并應用主庫傳遞過來的日志。
概述
DG的運行遵循一個很簡單的原則:主庫將redo日志傳給備庫,備庫接受后驗證并應用redo日志
-
DG只傳輸恢復數(shù)據(jù)庫事務所需的redo日志,以便同步備庫和對應的主庫
- redo由redo entries組成,一個redo entry由一組變更向量構成,每個向量描述數(shù)據(jù)庫中的一個數(shù)據(jù)塊的變更
- redo entry : redo entry包含重新生成數(shù)據(jù)庫更改所需的所有信息,例如雇員表中的薪水值
- 變更向量:撤銷段數(shù)據(jù)塊的變化、撤銷段的事務表的變化以及表的數(shù)據(jù)段塊的變化
-
DG會在備庫應用redo日志之前執(zhí)行Oracle驗證,以免擴散主庫中的受損的數(shù)據(jù)
-
如果網(wǎng)絡中斷或者備庫斷電導致主備庫的連接臨時中斷,DG會自動使用在主庫上已經(jīng)歸檔的redo日志重新同步備庫
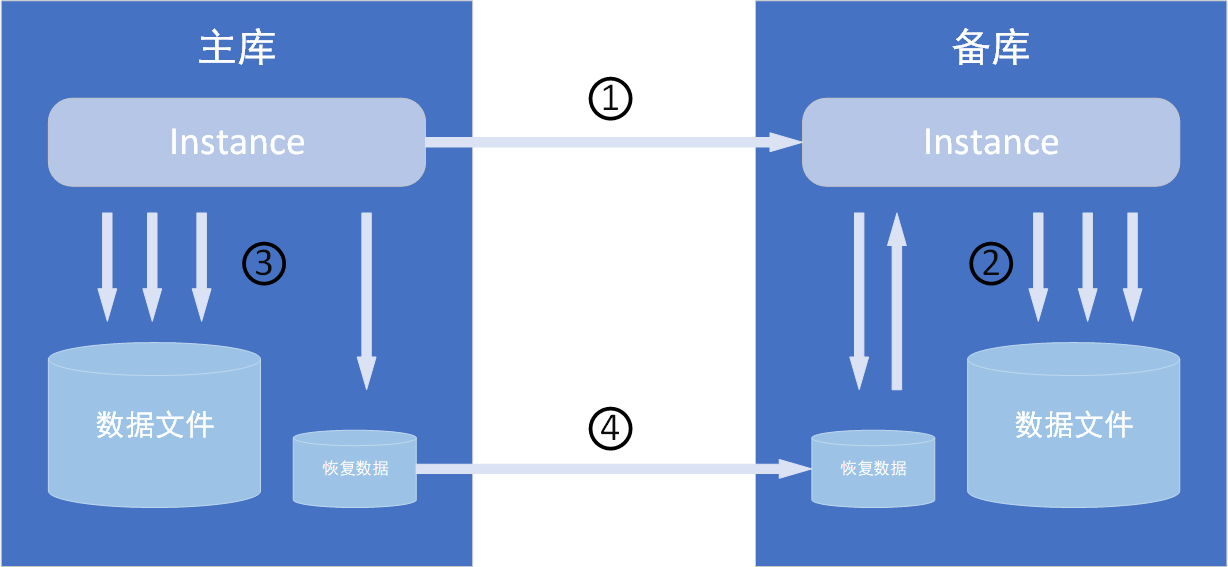
① 生成redo時,redo傳輸服務將redo日志從主庫傳到備庫
② 應用服務驗證redo日志并更新備庫數(shù)據(jù)庫文件
③ 獨立于DG,DBWn進程更新數(shù)據(jù)庫文件
④ 在網(wǎng)絡中斷或備庫停運后,DG使用已在主庫上歸檔的redo日志,自動重新同步備庫
傳輸方式
Redo Transport Service
Redo Transport Service主要協(xié)調(diào)從主庫到備庫的redo傳輸過程
主要傳輸過程:
- 主庫的LGWR進程將redo從SGA的redo log buffer中寫入到online redo log中
- 主庫的LNS(Log Network Service)進程從SGA的redo log buffer中讀取數(shù)據(jù),并交由Oracle Net服務傳輸?shù)絺鋷斓腞FS進程
- 備庫的RFS(Remote File Server)進程接受LNS傳輸?shù)膔edo日志,然后將其寫入standby redo log文件的順序文件中
同步傳輸SYNC
同步傳輸(synchronous transport, SYNC)又稱為“零數(shù)據(jù)損失”,使用同步傳輸可以使主庫與備庫隨時處于同步狀態(tài),傳輸過程中主庫要等到事務恢復所需的redo已被寫入備庫的磁盤里,才允許LGWR認可提交操作成功,具體的傳輸過程如下:
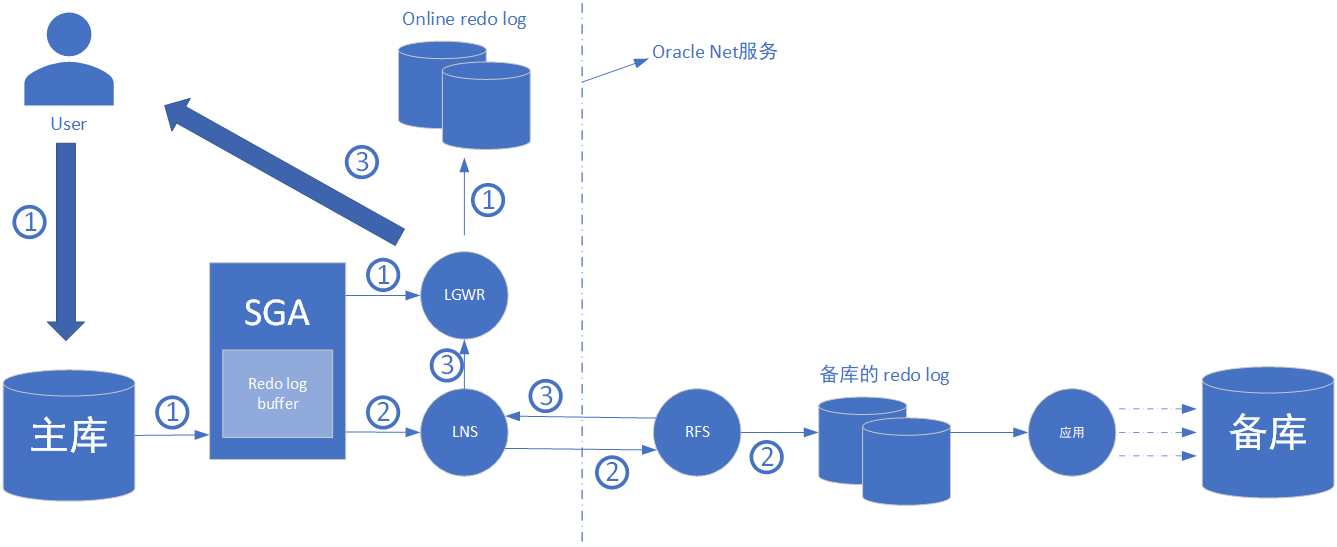
① 用戶提交事務,事務再SGA中創(chuàng)建一個redo entry。LGWR從redo log buffer中讀取redo entry,寫入online redo log,并等待LNS的確認
② LNS從redo log buffer中讀取相同的redo entry,通過Oracle Net服務傳給備庫。備庫上的RFS接受redo,然后將其寫入備庫的redo log中
③ 備庫的RFS從磁盤接受到寫完的消息,會傳回一個確認消息給主庫的LNS,LNS接著通知LGWR傳輸完成。LGWR向用戶發(fā)送確認信息
同步傳輸?shù)牟蛔悖?/strong>
SYNC可以確保得到數(shù)據(jù)庫提交確認的每個事務都得到保護,但這種方式會對主庫的性能造成影響。主要的原因就是:LGWR只有等到數(shù)據(jù)已在備庫受到保護的確認消息后,才能才是繼續(xù)處理下一個事務
redo log的大小、可用的網(wǎng)絡寬帶、往返網(wǎng)絡延遲(RTT)以及備庫寫入standby redo log的I/O性能都會對應用程序響應速度和數(shù)據(jù)庫吞吐量。所以網(wǎng)絡RTT隨著距離的延長而增加,主庫的性能也就會受到影響,實際上則會對主庫與備庫之間的距離形成限制
異步傳輸ASYNC
異步傳輸(asynchronous transport, ASYNC)與SYNC的最大的不同就在于LGWR不用等待來自LNS的確認消息,無論主備庫之間相距多遠,都可以做到幾乎不影響主庫的性能
即使由于寬帶有限,使得redo不能立即傳給備庫,LGWR也將繼續(xù)確認提交操作成功完成。如果LNS趕不上LGWR的提交進度,主庫在LNS將redo傳給備庫前就回收了redo log buffer,LNS將自行轉為從online redo log 讀取和發(fā)送redo;當LGWR趕上進度后,將自行轉回直接從redo log buffer中讀取發(fā)送

① 用戶提交事務,事務再SGA中創(chuàng)建一個redo entry。LGWR從redo log buffer中讀取redo entry,寫入online redo log,并向用戶發(fā)送確認信息
② LNS從redo log buffer中讀取相同的redo entry,通過Oracle Net服務傳給備庫。備庫上的RFS接受redo,然后將其寫入備庫的redo log中
③ 主備庫之間的日志傳輸出現(xiàn)異常等情況時,LNS自動轉為從online redo log讀取和發(fā)送redo;恢復后自動轉回從redo log buffer中讀取和發(fā)送redo
異步傳輸?shù)牟蛔悖?/strong>
ASYNC最大的不足就在于增加了數(shù)據(jù)丟失風險。如果某個故障破壞了主庫,而此時傳輸滯后尚未降低到0,那么傳輸滯后所包含的任何已提交事務都將丟失。所以在使用ASYNC時,提供足夠打的網(wǎng)絡寬帶來處理峰值期間告訴產(chǎn)生的redo,可以最大限度地降低數(shù)據(jù)損失的風險
應用服務
DG提供了兩種不同的方式在備庫中應用redo:Redo Apply(物理備用)和sql apply(邏輯備用)
DG的宗旨是防止丟失數(shù)據(jù),設計目標是讓備庫成為主庫的同步副本。DG的設計純粹的是為了實現(xiàn)對整個數(shù)據(jù)庫的單向復制。因此,DG還嵌入了safeguard,以免在備庫上對主庫是上復制來的數(shù)據(jù)進行任何未授權的改動
DG的第二目標旨在高度分離主庫和備庫,以防主庫上發(fā)生的問題影響到備庫,進而危及數(shù)據(jù)的保護和可用性,這樣做也可以防止備庫上出現(xiàn)的問題影響到主庫的可用性或性能
DG的第三目標是在主庫出現(xiàn)故障時提供數(shù)據(jù)可用性和高可用性。**Redo Apply和sql apply都能將一個同步備庫快速的轉成主角色。**這樣可以主庫出現(xiàn)計劃內(nèi)或計劃外中斷后保護數(shù)據(jù)和恢復可用性
DG的最后一個目標是為備用系統(tǒng)、存儲和軟件投資提供高額回報,而不會影響“數(shù)據(jù)保護和可用性”這項重要使命。Redo Apply和sql apply都允許將仍擔當備用角色的備庫投入生產(chǎn),同時不影響數(shù)據(jù)保護或實現(xiàn)恢復時間目標(recovery time objectives)的能力
Redo Apply

Redo Apply維護的備庫是與主庫逐塊對應的精確的物理副本
當備庫上的RFS進程收到從主庫傳來的redo,然后將其寫入standby redo log時,Redo Apply使用戒指恢復將standby redo log中的redo entry寫入內(nèi)存,接著直接在備庫上應用更改。
介質(zhì)恢復包括一個MRP進程以及多個并行應用進程(pr0x)
MRP管理恢復會話,按照SCN順序合并來自多個實例的redo(在使用RAC主實例的情形下)然后將redo解析到按應用進程劃分的更改映射中。應用進程讀取數(shù)據(jù)塊,組裝映射中的重做更改,然后將重做更改應用于數(shù)據(jù)塊。Redo Apply將應用進程數(shù)量自動配置為比備庫系統(tǒng)中的CPU數(shù)量少1。
Oracle針對Data Gurad Redo Apply的基準測試表明,在承擔OLTP(聯(lián)機事務處理)工作負荷時其速度高達47MB/s,在直接路徑加載情形下速度高達112MB/s
Redo Apply可防止將主庫上的物理損壞應用到備庫,從而提供了卓越的保護能力。以SYNC或ASYNC模式直接從SGA傳輸?shù)膔edo與主站點上的組件故障造成的物理I/O損壞完全隔離
當備庫使用Redo Apply應用redo時,將讀取相應的數(shù)據(jù)塊,并將SCN(對應剛從主庫中傳過來的redo的SCN,主庫的SCN)與redo log中的SCN(保存在備庫的redo log中的SCN,備庫的SCN)進行比較,可能出現(xiàn)的比較結果如下:
- 主備庫相同:說明主備庫數(shù)據(jù)同步正常
- 主庫的數(shù)據(jù)塊SCN小于備庫的數(shù)據(jù)塊SCN:說明主庫出現(xiàn)了寫丟失,此時回報錯ORA-752,建議的響應操作是執(zhí)行到物理備庫的故障轉移,然后重建主庫
- 主庫的數(shù)據(jù)塊SCN大于備庫的數(shù)據(jù)塊SCN:說明備庫出現(xiàn)了寫丟失,此時回發(fā)生內(nèi)部錯誤ORA-600 3020。如有可能,需要使用受影響的數(shù)據(jù)文件在主庫的備份來修復備庫;否則,必須重建備庫。
Sql Apply
Sql Apply(邏輯備庫)使用邏輯備用進程(LSP)將更改協(xié)調(diào)應用于備庫。
DG 轉換日志文件中的數(shù)據(jù)為SQL語句在邏輯standby上執(zhí)行SQL語句,因為邏輯standby是通過SQL語句來實現(xiàn)數(shù)據(jù)同步,所以在同步期間其必須保持打開狀態(tài)。

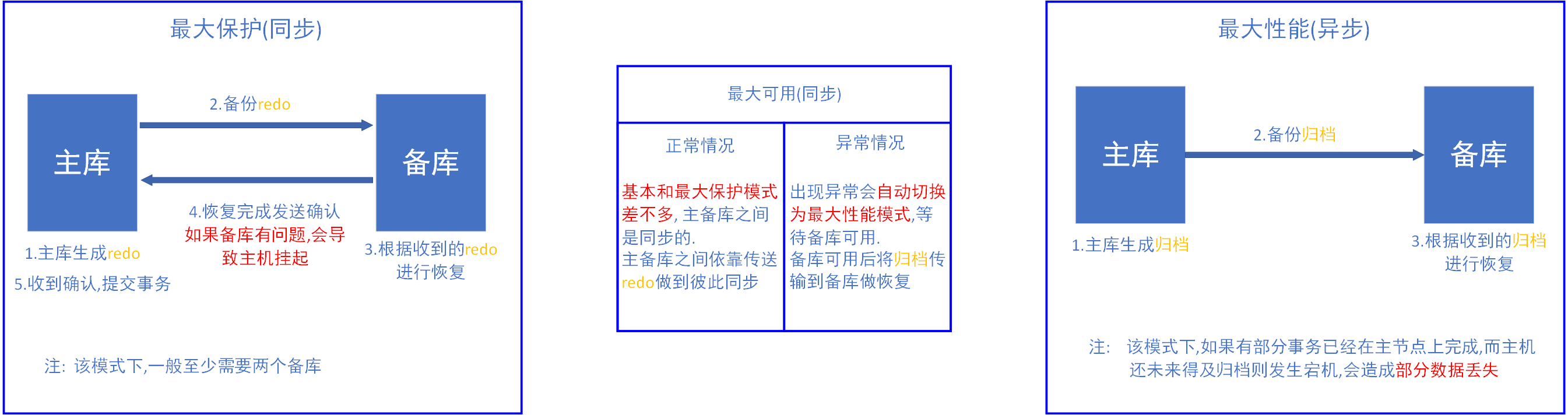
保護模式
DG的三種保護模式
DG相關的進程
Log Transport Service
在主節(jié)點上,日志傳輸服務主要使用如下幾個進程:
- LGWR
LGWR寫聯(lián)機重做日志
在同步模式下,直接將redo信息直接傳送到備庫中的RFS進程,主庫在繼續(xù)進行處理前需要等待備庫的確認在非同步情況下, 直接將日志信息傳遞到備庫的RFS進程,但是不等待備庫的確認信息主庫進程可以繼續(xù)進行處理。 - ARCH
ARCH進程可以在歸檔的同時,傳遞日志流到備庫的RFS進程,該進程還用于檢測和解決備庫的日志不連續(xù)問題(GAP)。 - FAL:(Fetch Archive Log)
fetch archive log只有物理備庫才有該進程,F(xiàn)AL進程提供了一個client/server的機制,用來解決檢測在生產(chǎn)庫產(chǎn)生的連續(xù)的歸檔日志,而在備庫接受的歸檔日志不連續(xù)的問題,該進程只有在需要的時候才會啟動,而工作完成后就關閉,因此在正常情況下,該進程無法看到,可以設置通過LGWR,ARCH進程去傳遞日志到備庫,但是不能兩個進程同時傳送。 - LNSn(LGWR Network Server process)
把日志通過網(wǎng)絡發(fā)送給遠程的目的地,每個遠程目的地對應一個LNS進程,多個LNS進程能夠并行工作。
Log Apply Service
在備庫節(jié)點上,日志應用進程主要使用如下的進程:
- RFS (Remote File Server)
RFS進程主要用來接受從主庫傳送過來的日志信息
對于物理備用數(shù)據(jù)庫而言:
可以直接將日志寫進備用重做日志
可以直接將日志信息寫到歸檔日志
為了使用備庫重做日志,必須創(chuàng)建備用重做日志,一般和主庫的聯(lián)機日志大小一樣, 組比主庫多一組 - ARCH
只對物理備庫,arch進程歸檔備庫重做日志,這些日志以后將被MRP進程應用到備庫。 - MRP:(Managed Recovery Process)
該進程只針對物理備庫,該進程應用歸檔日志到備庫,如果我們使用sql語句啟用該進程 ALTERDATABASE RECOVER MANAGED STANDBY DATABASE , 那么前臺進程將會做恢復,如果加上 disconnect 語句,那么恢復進程將在后臺進行,發(fā)出該語句的進程可以繼續(xù)做其他的事情實現(xiàn)
