




一、問題現象
同事反饋國外點在國內的XXX備庫實例宕,嘗試將該實例重啟,結果重啟報如下錯誤,未能正常啟動該數據庫。
Standby crash recovery failed to bring standby database to a consistent
point because needed redo hasn't arrived yet.
MRP: Wait timeout: thread 1 sequence# 0
Errors with log +DG/xxxx/archivelog/2021_12_29/thread_2_seq_24193.3766.1092589235
Standby Crash Recovery aborted due to error 16016.
Errors in file /u01/app/oracle/diag/rdbms/xxxx/xxxx/trace/xxxx_ora_67164.trc:
ORA-16016: archived log for thread 1 sequence# 22789 unavailable
Recovery interrupted!
Some recovered datafiles maybe left media fuzzy
Media recovery may continue but open resetlogs may fail
Completed Standby Crash Recovery.
Errors in file /u01/app/oracle/diag/rdbms/xxxx/xxxx/trace/xxxx_ora_67164.trc:
ORA-10458: standby database requires recovery
ORA-01196: file 1 is inconsistent due to a failed media recovery session
ORA-01110: data file 1: '+DG/xxxx/datafile/system.419.941189591'
ORA-10458 signalled during: ALTER DATABASE OPEN...
幫同事看了下問題,經過多次嘗試,最終將數據庫重新open,并正常接收主庫傳來的日志,數據庫同步正常。
二、問題分析
問題看似解決了,其實只是做了一半,就是為什么這個實例會宕,另外就是這個數據庫之前也配置了告警,為什么本次沒有發出告警,要分析下原因,避免下次再重新改情況。
該數據庫是國外點在國內的一個備庫,和主庫實時同步,數據庫版本是Oracle 11.2.0.4 ,該數據庫服務器上共部署了兩個實例,而本次是只宕了其中一個實例,另一個實例正常。
首先查看了下問題發生時段的alert日志,在日志里看到了在數據庫發生故障時所報的日志信息:
Errors in file /u01/app/oracle/diag/rdbms/xxxx/xxxx/trace/xxxx_lgwr_45171.trc:
ORA-04021: timeout occurred while waiting to lock object
LGWR (ospid: 45171): terminating the instance due to error 4021
Wed Dec 29 17:20:02 2021
System state dump requested by (instance=1, osid=45171 (LGWR)), summary=[abnormal instance termination].
System State dumped to trace file /u01/app/oracle/diag/rdbms/xxxx/xxxx/trace/xxxx_diag_45155_20211229172002.trc
Dumping diagnostic data in directory=[cdmp_20211229172002], requested by (instance=1, osid=45171 (LGWR)), summary=[abnormal instance termination].
Wed Dec 29 17:20:02 2021
ORA-1092 : opitsk aborting process
Wed Dec 29 17:20:02 2021
License high water mark = 49
Instance terminated by LGWR, pid = 45171
USER (ospid: 159932): terminating the instance
Instance terminated by USER, pid = 159932
Wed Dec 29 17:20:04 2021
Adjusting the default value of parameter parallel_max_servers
from 1280 to 970 due to the value of parameter processes (1000)
Starting ORACLE instance (normal)
************************ Large Pages Information *******************
Per process system memlock (soft) limit = 143 GB
Total Shared Global Region in Large Pages = 14 GB (75%)
Large Pages used by this instance: 7329 (14 GB)
Large Pages unused system wide = 6 (12 MB)
Large Pages configured system wide = 17000 (33 GB)
Large Page size = 2048 KB
從日志里可以看到由于產生了ORA-1092 : opitsk aborting process報錯,導致該數據庫實例宕。此時就要去分析是什么原因導致產生ORA-1092報錯。首先看了下報錯時產生的/u01/app/oracle/diag/rdbms/xxxx/xxxx/trace/xxxx_diag_45155_20211229172002.trc文件,文件內容太多,格式化輸出后也不太好排查,希望能從其它地方獲取到一些價值信息。
首先在MOS上查詢了 ORA-1092 : opitsk aborting process報錯原因,MOS上講該問題產生的原因也比較多,此時嘗試看下操作系統日志,看下是否有什么價值的信息。
從操作系統的 /var/log/messages里,發現日志不停的有xxx-xxx-standby-db1 kernel: EXT4-fs warning (device sda2): ext4_dx_add_entry: Directory index full!這樣的報錯:
該報錯的原因是因為 操作系統小文件太多,導致innode塊被占用完了,然后查了下數據庫相關文件,發現是兩個數據庫的審計文件占用了大量innode,通過du -sh 查看都被夯住了,是否是該問題導致數據庫實例宕呢。
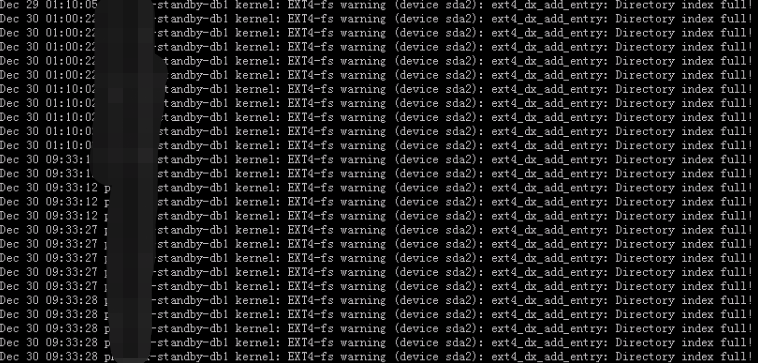
經查詢該數據庫已關閉了審計查詢,但sys用戶依然會產生大量審計文件。
三、問題處理
于是通過find 結合 xargs 和rm 將兩個實例下的審計文件大量刪除,并配置了定時清理任務,后續觀察了幾天,innode已經由原來的89%降到了當前的34%,操作系統日志未在報index full滿的報錯信息,備庫和主庫的同步也正常。
