




針對于 PostgreSQL 中的統計信息有些迷惑,稍微查閱了一些資料,在此分享下,本人拙見,有不妥的還請指正
在 PostgreSQL 數據庫,統計信息可以大致分為兩種。一種是通常意義上規劃器用于生成執行計劃的關于數據分布的統計信息,還有一種是跟蹤服務進程的統計信息
一、數據分布統計信息
1、什么是數據分布統計信息?
與每張表的數據分布有關,是一種描述數據分布的統計數據。
規劃器使用的統計信息有兩種:
-
單列統計信息
比較常見的,可以從pg_statistic表中查看某張表單個字段的統計信息
-
擴展統計信息
analyze只能收集表的單列統計信息,對于查詢子句中用到多個列相關聯的情況,可能會由于缺乏相對應的統計信息而導致走了錯誤的執行計劃的慢查詢產生。針對常規的統計信息無法捕捉到跨列關聯,可以創建擴展統計信息(CREATE EXTENSION)來指示服務器獲得相關的列集合的統計信息,實現自動計算多元統計信息
2、有什么作用?
數據庫在執行一條SQL時可以有多種執行方式,例如順序掃描、索引掃描等等,那么數據庫要選擇哪一種方式來生成執行計劃呢?這就要用到統計信息。規劃器可以通過收集的統計信息為查詢語句選擇一個最優的方式來生成執行計劃
(所以統計信息的更新不及時也可能導致統計信息的不準確,進而影響規劃器生成的執行計劃,從而可能會導致走錯誤執行計劃的慢查詢)
3、誰收集的?
- vacuum
- analyze
4、保存在哪?
1)單列統計信息
-
pg_class.reltuples、pg_class.relpages
記錄表的tuple的行數和page頁數
-
pg_statistic 系統表(由于pg_statistic 系統表中的數據人為不易閱讀, 一般從pg_stats 系統視圖查看)
記錄表的單個字段的值的分布率
pg_statistic 中也存儲關于索引表達式值的統計數據
2)擴展統計信息
- pg_statistic_ext
- pg_statistic_ext_data
5、什么時候更新
-
手動執行
- 手動 vacuum
- 手動執行 analyze
- 部分DDL語句(如CREATE INDEX)也會更新統計信息
-
自動更新
autovacuum 達到閾值時觸發
autovacuum線程不止負責對過期元組進行清理,同時也負責定期更新表的統計信息。
為什么要把這兩個操作放在一起?
- PG的MVCC機制數據和數據的舊版本是統一存放在表文件上的,在清理時要進行全表掃描的操作,而統計信息的收集也是需要讀取表文件的,這兩個操作放在一起做可以在一定程度上節省IO;
- 清理廢舊元組和更新統計信息都是通過收集表的元組變更數據來觸發的,共享一套機制,因此放在一起處理也比較方便;
6、什么時候重置/刪除
目前還沒有找到相關的函數或者命令來重置此類的統計信息
7、其他注意事項
-
對于大型表,
ANALYZE對表內容進行隨機抽樣,而不是檢查每一行。這允許在很短的時間內分析非常大的表。 -
ANALYZE考慮的樣本數量取決于default_statistics_target參數。該參數值越大,直方圖的分組越多統計信息就越準確,但同時較大的值會增加ANALYZE執行所需的時間,統計信息收集的開銷也會變大,在pg_statistic中也會消耗更多空間。默認值為 100。也可以通過
ALTER TABLE SET STATISTICS命令為每一列單獨設置
pg_stats
postgres=# \d pg_stats
View "pg_catalog.pg_stats"
Column | Type | Collation | Nullable | Default
------------------------+----------+-----------+----------+---------
schemaname | name | | | --- schema 名
tablename | name | | | --- 表名
attname | name | | | --- 列名
inherited | boolean | | | --- 是否繼承列
null_frac | real | | | --- null空值的比率
avg_width | integer | | | --- 平均寬度,字節
n_distinct | real | | | --- 大于零就是非重復值的數量,小于零則是非重復值的個數除以行數
most_common_vals | anyarray | | | --- MCV,高頻值
most_common_freqs | real[] | | | --- MCF,高頻值的頻率
histogram_bounds | anyarray | | | --- 直方圖
correlation | real | | | --- 物理順序和邏輯順序的關聯性。
most_common_elems | anyarray | | | --- 高頻元素,比如數組
most_common_elem_freqs | real[] | | | --- 高頻元素的頻率
elem_count_histogram | real[] | | | --- 直方圖(元素)
-
correlation:物理順序和邏輯順序的關聯性。(-1 ~ 1)
1- 邏輯順序與存儲的物理順序相同-1- 邏輯順序與存儲的物理順序相反
當該值接近-1或+1時,對列的索引掃描估計要比接近0時便宜,這是因為減少了對磁盤的隨機訪問
二、監控統計信息
1、什么是監控統計信息?
PostgreSQL的統計收集器是一個支持收集和報告服務器活動信息的子系統
- 對表和索引的訪問計數
- 跟蹤每個表中的 總行數、每個表的 vacuum 和 analyze 的信息
- 統計調用用戶定義函數的次數以及在每次調用中花費的總時間
- 也支持報告有關系統正在干什么的動態信息,例如當前正在被其他服務器進程 執行的命令以及系統中存在哪些其他連接。 這個功能是獨立于收集器進程存在的
2、誰收集的統計信息
由stats collector 統計收集進程來進行這類統計信息的收集(15版本取消收集統計信息的進程,統計信息不再使用文件和文件系統,而是使用動態共享內存)
相關參數
-
參數track_activities允許監控當前被任意服務器進程執行的命令。
-
參數track_counts控制是否收集關于表和索引訪問的統計信息。
-
參數track_functions啟用對用戶定義函數使用的跟蹤。
-
參數track_io_timing啟用對塊讀寫次數的監控。默認為off,打開會導致性能下降
3、如何查看統計信息?
15版本之前,統計收集器通過 UDP 接收統計更新,并通過定期將統計數據寫入臨時文件來共享統計數據。這些文件被存儲在名 字由stats_temp_directory參數指定的目錄中,默認是pg_stat_tmp;
15版本將統計信息存儲在共享內存中。可變編號對象的統計信息存儲在 dshash 哈希表中(由動態共享內存支持)。固定編號的統計信息存儲在普通共享內存中。
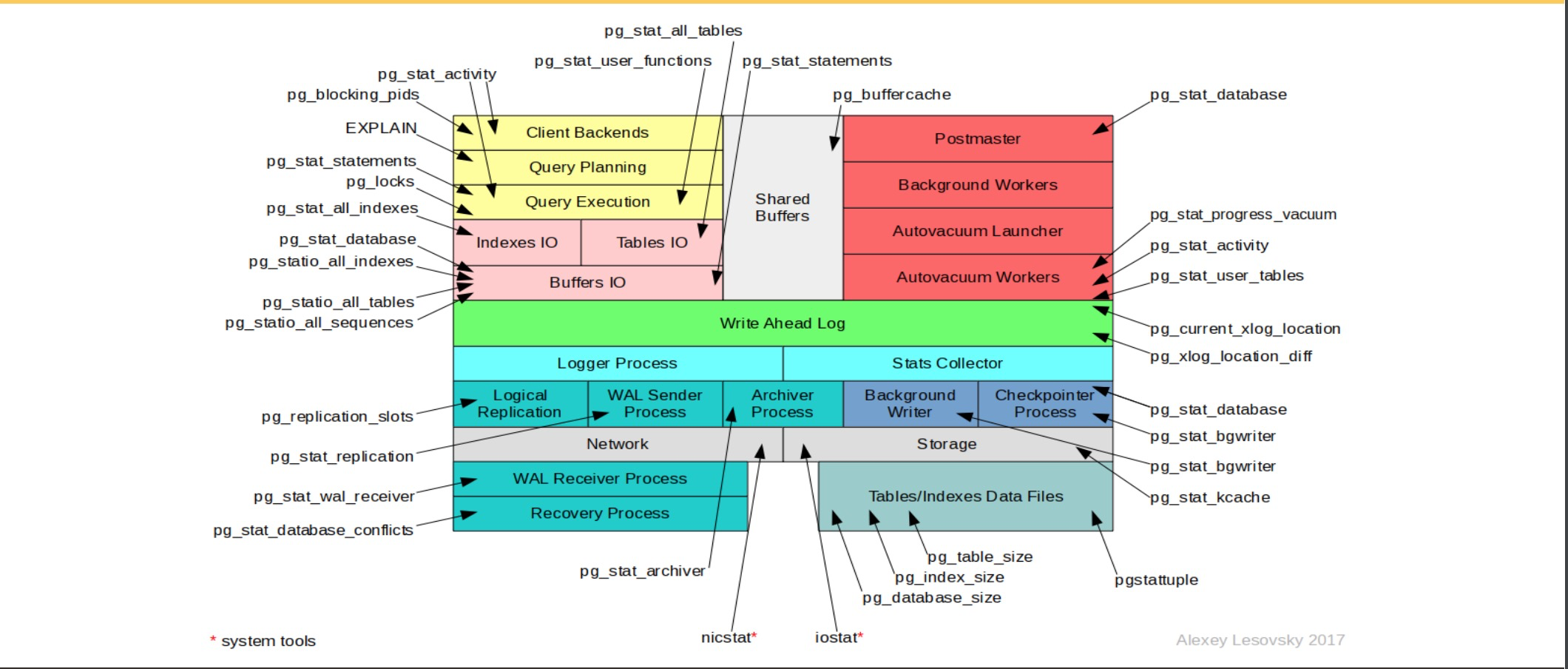
- all:包含所有的表/索引
- sys:只包含系統表/系統表上的索引
- user:只顯示用戶表/用戶表上的索引
1)各個對象級別的統計信息視圖
-
數據庫:pg_stat_database
-
表:pg_stat_all_tables、pg_stat_sys_tables、pg_stat_user_tables
-
索引:pg_stat_all_indexes、pg_stat_sys_indexes、pg_stat_user_indexes
-
函數:pg_stat_user_functions
2)各個對象上發生I/O情況的統計視圖
- 表:pg_statio_all_tables、pg_statio_sys_tables、pg_statio_user_tables
- 索引:pg_statio_all_indexes、pg_statio_sys_indexes、pg_statio_user_indexes
- 序列:pg_statio_all_sequences、pg_statio_sys_sequences、pg_statio_user_sequences
3)動態統計視圖
- 進程相關:pg_stat_activity
- 流復制相關:pg_stat_replication、pg_stat_replication_slots
- wal相關:pg_stat_wal_receiver
- 邏輯訂閱相關:pg_stat_subscription、pg_stat_subscription_stats
- pg_stat_ssl
- pg_stat_gssapi
- 監控進度
- pg_stat_progress_analyze
- pg_stat_progress_create_index
- pg_stat_progress_vacuum
- pg_stat_progress_cluster
- pg_stat_progress_basebackup
- pg_stat_progress_copy
4、什么時候更新
15版本之前,收集器本身最多每PGSTAT_STAT_INTERVAL毫秒(缺省為500ms,除非在編譯服務器的時候修改過)發送一次新的報告。但是由track_activities收集的當前查詢信息總是最新的。
15版本引入stats_fetch_consistency 參數, 有三個值:
-
none - 每次訪問都會從共享內存中重新獲取計數器。
最適合監控系統
-
cache - 第一次訪問對象的統計信息會緩存這些統計信息直到事務結束,除非調用pg_stat_clear_snapshot() 。(默認值)
確保重復訪問產生相同的值
-
snapshot - 第一次統計訪問緩存當前數據庫中可訪問的所有統計信息,直到事務結束,除非調用pg_stat_clear_snapshot() 。
在以交互方式檢查統計信息時很有用,但開銷更高。
5、什么時候刪除/重置?
-
當在服務器啟動時執行恢復時(例如立即關閉、服務器崩潰以及時間點恢復之后),所有統計計數器會被重置。
當服務器被干凈地關閉時,一份統計數據的永久拷貝被存儲在pg_stat子目錄中, 這樣在服務器重啟后統計信息能被保持
- 15版本之前,該過程由 stats collector 進程執行;
- 15版本,由于取消了 stats collector 進程,該統計信息由 checkpointer檢查點 進程輸出寫到文件系統
[postgres@node4 ~]$ cd $PGDATA
[postgres@node4 data5555]$ ll pg_stat
total 0
[postgres@node4 data5555]$ pg_ctl stop
waiting for server to shut down.... done
server stopped
[postgres@node4 data5555]$ ll pg_stat
total 60
-rw-------. 1 postgres postgres 57573 Dec 13 12:35 pgstat.stat
-
執行 pg_stat_reset() 函數重置統計信息
當 pg_stat_reset() 清理監控進程的統計信息時,會將pg_stat_all_tables視圖的數據全部清為0。analyze后會更新pg_stat_user_tables視圖的相關 analyze或者vacuum字段以及n_live_tup、n_dead_tup等字段。
參考
https://aws.amazon.com/cn/blogs/database/understanding-statistics-in-postgresql/
https://xie.infoq.cn/article/a52111ef25e6361f89b0e6d79
https://aws.amazon.com/cn/blogs/database/understanding-statistics-in-postgresql/
https://www.percona.com/blog/postgresql-15-stats-collector-gone-whats-new/
