




問題現象
1、數據庫進程內存占比較高
- 長時間占比較高:觀察監控平臺內存占用的變化曲線,無論當前數據庫是否有業務在運行,數據庫進程內存占總機器內存的比例長時間處于較高狀態,且不下降。
- 執行作業期間占比較高:數據庫進程在沒有業務執行時,內存使用持續處于較低的狀態,當有業務執行時,內存占用升高,待作業執行結束后,內存又恢復到較低的狀態。
- 內存上漲不下降:數據庫進程在執行業務過程中內存呈緩慢上漲趨勢,且業務執行完后無下降趨勢。
執行SQL語句報內存不足的錯誤,如下所示。
gaussdb=# select contextname, sum(totalsize)/1024/1024 sum, sum(freesize)/1024/1024, count(*) count from gs_shared_memory_detail group by contextname order by sum desc limit 10;
ERROR: memory is temporarily unavailable
DETAIL: Failed on request of size 46 bytes under queryid 281475005884780 in heaptuple.cpp:1934.
原因分析
如果出現集群內存不足或者長時間內存占用處于較高狀態的情況,一般是由以下幾種原因造成的。
1、內存堆積
當SQL語句執行過程中臨時內存未及時釋放時,會導致內存堆積。
2、并發過高導致內存占用過高
客戶端向server端建立的連接數過多,導致server端創建了大量的session,占用大量內存,這種場景下會出現內存出現占用較高的情況。
3、單條SQL語句內存占用較高
對于部分SQL語句,執行過程中會使用大量的內存,導致內存出現短暫性上漲,如復雜的存儲過程語句,執行時內存占用可能達到幾十GB大小。
4、內存緩存過多
GaussDB Kernel引入了jemalloc開源庫來管理內存管理,但是jemalloc在面對大量的內存碎片時會存在內存持續緩存不釋放的問題,導致數據庫進程使用的內存遠遠超過了實際使用的內存,具體表現為使用內存視圖pv_total_memory_detail查詢時,other_used_memory占用過大。如下所示。
gaussdb=# select * from pv_total_memory_detail;
nodename | memorytype | memorymbytes
----------------+-------------------------+--------------
coordinator1 | max_process_memory | 81920
coordinator1 | process_used_memory | 14567
coordinator1 | max_dynamic_memory | 34012
coordinator1 | dynamic_used_memory | 1851
coordinator1 | dynamic_peak_memory | 3639
coordinator1 | dynamic_used_shrctx | 394
coordinator1 | dynamic_peak_shrctx | 399
coordinator1 | max_backend_memory | 648
coordinator1 | backend_used_memory | 1
coordinator1 | max_shared_memory | 46747
coordinator1 | shared_used_memory | 11618
coordinator1 | max_cstore_memory | 512
coordinator1 | cstore_used_memory | 0
coordinator1 | max_sctpcomm_memory | 0
coordinator1 | sctpcomm_used_memory | 0
coordinator1 | sctpcomm_peak_memory | 0
coordinator1 | other_used_memory | 1013
coordinator1 | gpu_max_dynamic_memory | 0
coordinator1 | gpu_dynamic_used_memory | 0
coordinator1 | gpu_dynamic_peak_memory | 0
coordinator1 | pooler_conn_memory | 0
coordinator1 | pooler_freeconn_memory | 0
coordinator1 | storage_compress_memory | 0
coordinator1 | udf_reserved_memory | 0
(24 rows)
定位思路
出現內存過載的問題時,如果有內存過載的環境可以實時定位,可以使用思路一中的定位流程定位內存問題,如果現場環境已經被破壞(集群重啟等導致),則按照思路二中的流程進行定位。當前GaussDB Kernel的內存管理采用內存上下文機制管理,在內存使用的統計上有著精準的統計和可視化的視圖方便查詢定位。
思路一:有現場環境
1、查詢內存統計信息
表:信息說明

2、確定內存占用分類
根據查詢內存統計信息中查詢出的內存統計視圖結果,根據內存統計視圖可以分析出如下結果。
表:分析結果
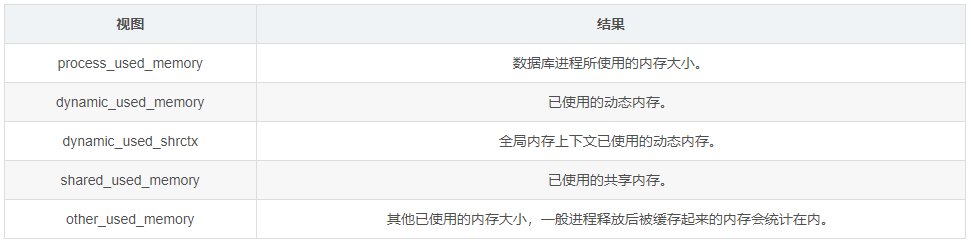
- 如果dynamic_used_memory較大,dynamic_used_shrctx較小,則可以確認是線程和session上內存占用較多,則直接查詢線程和session上的內存上下文的內存占用即可確認內存堆積的具體內存上下文。
- 如果dynamic_used_memory較大,dynamic_used_shrctx和dynamic_used_memory相差不大,則可以確認是全局內存上下文使用的動態內存較大,直接查詢全局的內存上下文的內存占用即可確認內存堆積的具體內存上下文。
- 如果只有shared_used_memory占用較大,則可以確認是共享內存占用較多,忽略即可。
- 如果是other_used_memory較大,一般情況下應該是出現了頻繁的內存申請和釋放的業務導致內存碎片緩存過多,此時需要聯系華為工程師定位解決。
3、確定內存堆積原因
根據確定內存占用分類中查詢出來的內存統計信息數據就可以確認數據庫進程內存使用過高的原因,一般內存占用較高都是由如下2類原因導致。
表:內存較高原因

思路二:無現場環境
某些內存過載出現時會導致集群環境重啟等,這種情況下沒有實時的環境能夠定位內存過載的原因是什么,就需要使用如下流程來定位已發生過的內存過載導致的原因。
1、查看歷史內存占用曲線
在環境上查看數據庫進程使用內存大小的監控數據。根據數據庫在一段時間內的內存變化曲線,可以確認內存過載的時間節點,如下圖所示。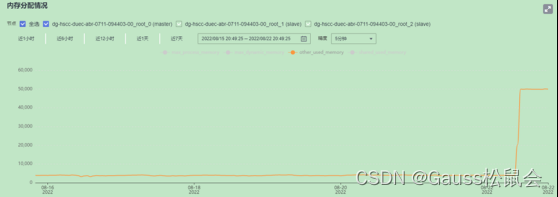
從歷史內存曲線中,可以看出在8月22日內存出現瞬間上漲的情況。
2、分析歷史內存統計信息
根據查看歷史內存占用曲線中確認的時間節點信息,使用視圖gs_get_history_memory_detail可獲得該時間節點的內存快照日志,快照日志以時間戳作為文件名,能夠迅速查找,根據快照日志能夠快速的找到內存居高的內存上下文信息,然后聯系華為工程師協助即可解決。
如果沒有在歷史內存統計信息中找到對應時間節點的內存快照信息,此時需要關注該時間節點業務的并發量,執行語句的復雜度等,根據實際業務情況進一步分析內存上漲的原因,需聯系華為工程師協助解決。
處理方法
遇到內存占用過高或者內存不足報錯的場景時可以通過如下流程來分析定位原因并解決。
1.獲取內存統計信息
必須要獲取出現內存故障的數據庫進程上的內存統計信息。
實時內存統計信息
查詢GaussDB Kernel進程總的內存統計信息。
gaussdb=# select * from pv_total_memory_detail;
nodename | memorytype | memorymbytes
----------------+-------------------------+--------------
coordinator1 | max_process_memory | 81920
coordinator1 | process_used_memory | 14567
coordinator1 | max_dynamic_memory | 34012
coordinator1 | dynamic_used_memory | 1851
coordinator1 | dynamic_peak_memory | 3639
coordinator1 | dynamic_used_shrctx | 394
coordinator1 | dynamic_peak_shrctx | 399
coordinator1 | max_backend_memory | 648
coordinator1 | backend_used_memory | 1
coordinator1 | max_shared_memory | 46747
coordinator1 | shared_used_memory | 11618
coordinator1 | max_cstore_memory | 512
coordinator1 | cstore_used_memory | 0
coordinator1 | max_sctpcomm_memory | 0
coordinator1 | sctpcomm_used_memory | 0
coordinator1 | sctpcomm_peak_memory | 0
coordinator1 | other_used_memory | 1013
coordinator1 | gpu_max_dynamic_memory | 0
coordinator1 | gpu_dynamic_used_memory | 0
coordinator1 | gpu_dynamic_peak_memory | 0
coordinator1 | pooler_conn_memory | 0
coordinator1 | pooler_freeconn_memory | 0
coordinator1 | storage_compress_memory | 0
coordinator1 | udf_reserved_memory | 0
(24 rows)
查看數據庫進程全局的內存上下文占用大小,按照內存上下文分類從大到小排序,取top10即可。
gaussdb=# select contextname, sum(totalsize)/1024/1024 sum, sum(freesize)/1024/1024, count(*) count from pg_shared_memory_detail group by contextname order by sum desc limit 10;
contextname | sum | ?column? | count
-----------------------------------+----------------------+-----------------------+-------
IncreCheckPointContext | 250.8796234130859375 | .00273132324218750000 | 1
AshContext | 64.0950317382812500 | .00772094726562500000 | 1
DefaultTopMemoryContext | 60.5699005126953125 | 1.0594177246093750 | 1
StorageTopMemoryContext | 16.7601776123046875 | .05357360839843750000 | 1
GlobalAuditMemory | 16.0081176757812500 | .00769042968750000000 | 1
CBBTopMemoryContext | 14.9503479003906250 | .04009246826171875000 | 1
Undo | 8.6680450439453125 | .21752929687500000000 | 1
DoubleWriteContext | 6.5549163818359375 | .02331542968750000000 | 1
ThreadPoolContext | 5.4042663574218750 | .00525665283203125000 | 1
GlobalSysDBCacheEntryMemCxt_16384 | 4.2232666015625000 | .89799499511718750000 | 16
(10 rows)
查看數據庫進程所有線程的內存上下文占用大小,按照內存上下文分類從大到小排序,取top10即可。
gaussdb=# select contextname, sum(totalsize)/1024/1024 sum, sum(freesize)/1024/1024, count(*) count from pv_thread_memory_context group by contextname order by sum desc limit 10;
contextname | sum | ?column? | count
---------------------------------+----------------------+-----------------------+-------
LocalSysCacheShareMemoryContext | 612.5096435546875000 | 57.4630737304687500 | 543
StorageTopMemoryContext | 311.8157348632812500 | 3.2519149780273438 | 543
DefaultTopMemoryContext | 168.5756530761718750 | 10.7153015136718750 | 543
LocalSysCacheMyDBMemoryContext | 167.4375000000000000 | 65.7499847412109375 | 543
ThreadTopMemoryContext | 161.4440002441406250 | 4.0309295654296875 | 543
CBBTopMemoryContext | 109.1161880493164063 | 6.7845993041992188 | 543
LocalSysCacheTopMemoryContext | 93.4109802246093750 | 13.2236938476562500 | 543
Timezones | 43.2421417236328125 | 1.4333953857421875 | 543
gs_signal | 32.2394561767578125 | 4.9155120849609375 | 1
Type information cache | 22.9119262695312500 | .86848449707031250000 | 329
(10 rows)
查看數據庫進程所有session的內存上下文占用大小,按照內存上下文分類從大到小排序,取top10即可。
gaussdb=# select contextname, sum(totalsize)/1024/1024 sum, sum(freesize)/1024/1024, count(*) count from pv_session_memory_context group by contextname order by sum desc limit 10;
contextname | sum | ?column? | count
-------------------------+----------------------+-----------------------+-------
CachedPlan | 223.4433593750000000 | 64.6083068847656250 | 12394
CachedPlanQuery | 134.7382812500000000 | 42.3366699218750000 | 12596
SessionTopMemoryContext | 132.3496398925781250 | 25.9272155761718750 | 302
CachedPlanSource | 98.6943359375000000 | 28.3841018676757813 | 12897
CBBTopMemoryContext | 60.6870880126953125 | 3.0470962524414063 | 302
GenericRoot | 35.1962890625000000 | 14.1624069213867188 | 471
Timezones | 24.0499572753906250 | .79721069335937500000 | 302
SPI Plan | 21.0664062500000000 | 6.8149719238281250 | 2396
AdaptiveCachedPlan | 17.5449218750000000 | 4.7733078002929688 | 546
Prepared Queries | 16.4062500000000000 | 7.5508117675781250 | 300
(10 rows)
歷史內存統計信息
歷史內存信息只有在沒有實時現場環境的時候才會被用到,通過歷史內存統計信息來定位過去發生過的內存過載的原因。
查詢視圖gs_get_history_memory_detail可以獲得數據庫在過去所有時間段的內存使用超過90%時的內存使用詳情,如下所示。
gaussdb=# select * from gs_get_history_memory_detail(NULL) order by memory_info desc limit 10;
memory_info
-------------------------------
mem_log-2023-03-10_205125.log
mem_log-2023-03-10_205115.log
mem_log-2023-03-10_205104.log
mem_log-2023-03-10_205054.log
mem_log-2023-03-10_205043.log
mem_log-2023-03-10_205032.log
mem_log-2023-03-10_205022.log
mem_log-2023-03-10_205012.log
mem_log-2023-03-10_205002.log
mem_log-2023-03-10_204951.log
(10 rows)
選取其中一個log文件,執行如下查詢語句即可閱覽log內容,記載了全局的內存概況與全局級內存上下文,線程級內存上下文,session級內存上下的top20內存上下文占用詳情,如下所示。
gaussdb=# select * from gs_get_history_memory_detail('mem_log-2023-03-10_205125.log');
memory_info
--------------------------------------------------------------------------------------
{
"Global Memory Statistics": {
"Max_dynamic_memory": 34012,
"Dynamic_used_memory": 3645,
"Dynamic_peak_memory": 3664,
"Dynamic_used_shrctx": 401,
"Dynamic_peak_shrctx": 401,
"Max_backend_memory": 648,
"Backend_used_memory": 1,
"other_used_memory": 0
},
"Memory Context Info": {
"Memory Context Detail": {
"Context Type": "Shared Memory Context",
"Memory Context": {
"context": "IncreCheckPointContext",
"freeSize": 2864,
"totalSize": 263066352
},
...
},
"Memory Context Detail": {
"Context Type": "Session Memory Context",
"Memory Context": {
"context": "CachedPlan",
"freeSize": 68041368,
"totalSize": 235937792
},
...
},
"Memory Context Detail": {
"Context Type": "Thread Memory Context",
"Memory Context": {
"context": "LocalSysCacheShareMemoryContext",
"freeSize": 60431360,
"totalSize": 644141760
},
...
}
}
(322 rows)
2.分析內存占用分類
根據獲取內存統計信息中查詢獲得的內存占用概況可分析如下:
- 如果dynamic_used_memory較大,dynamic_used_shrctx較小,則可以確認是線程和session上內存占用較多。
- 如果dynamic_used_memory較大,dynamic_used_shrctx和dynamic_used_memory相差不大,則可以確認是全局內存上下文使用的動態內存較大。
- 如果只有shared_used_memory占用較大,則可以確認是共享內存占用較多,忽略即可。
- 如果是other_used_memory較大,一般情況是由于業務執行時頻繁的內存申請和釋放導致內存碎片緩存過多。
針對這幾種種情況,分別按照下面的4類定位方法定位即可。
1、全局內存上下文占用較高
有現場環境,查詢如下語句即可確認是哪個內存上下文占用內存較高。
gaussdb=# select contextname, sum(totalsize)/1024/1024 sum, sum(freesize)/1024/1024, count(*) count from pg_shared_memory_detail group by contextname order by sum desc limit 10;
contextname | sum | ?column? | count
-----------------------------------+----------------------+-----------------------+-------
IncreCheckPointContext | 250.8796234130859375 | .00273132324218750000 | 1
AshContext | 64.0950317382812500 | .00772094726562500000 | 1
DefaultTopMemoryContext | 60.5699005126953125 | 1.0594177246093750 | 1
StorageTopMemoryContext | 16.7601776123046875 | .04942321777343750000 | 1
GlobalAuditMemory | 16.0081176757812500 | .00769042968750000000 | 1
CBBTopMemoryContext | 14.9503479003906250 | .04009246826171875000 | 1
Undo | 8.6680450439453125 | .20516967773437500000 | 1
DoubleWriteContext | 6.5549163818359375 | .02331542968750000000 | 1
ThreadPoolContext | 5.3873443603515625 | .00525665283203125000 | 1
GlobalSysDBCacheEntryMemCxt_16384 | 4.3115692138671875 | 1.0470581054687500 | 16
(10 rows)
確定內存上下文之后,以IncreCheckPointContext為例,查詢視圖gs_get_shared_memctx_detail,確定內存堆積的代碼位置。
gaussdb=# select * from gs_get_shared_memctx_detail('IncreCheckPointContext');
file | line | size
-------------------------+------+-----------
ipci.cpp | 476 | 64
pagewriter.cpp | 298 | 1024
ipci.cpp | 498 | 4096
pagewriter.cpp | 322 | 19632000
pagewriter.cpp | 317 | 33669120
storage_buffer_init.cpp | 90 | 209756160
(6 rows)
從上述查詢結果可以看出,在代碼storage_buffer_init.cpp的90行申請了大量的內存,可能存在內存堆積不釋放的問題。
無現場環境
若存在內存過載時間節點的內存快照信息,則在內存統計信息中找到Shared Memory Context類型的top20的內存上下文申請詳情,即可確認內存堆積的原因。
若不存在內存過載時間節點的內存快照信息,請聯系華為工程師定位解決。
總結:使用上面2種方法找到內存占用過多的內存上下文后,可進行初步判斷,在數據庫內核執行業務時,一般占用較多的全局內存上下文有“IncreCheckPointContext”,“DefaultTopMemoryContext”,如果是這兩個context占用較多,則需要減小業務的并發來降低內存占用;如果是其他內存上下文,可能是業務執行過程出現內存堆積,請聯系華為工程師解決。
2、線程級內存上下文占用內存較高
有現場環境
查詢如下語句即可確認是哪個內存上下文占用內存較高。
gaussdb=# select contextname, sum(totalsize)/1024/1024 sum, sum(freesize)/1024/1024, count(*) count from pv_thread_memory_context group by contextname order by sum desc limit 10;
contextname | sum | ?column? | count
---------------------------------+----------------------+-----------------------+-------
LocalSysCacheShareMemoryContext | 641.0926513671875000 | 60.0820159912109375 | 543
StorageTopMemoryContext | 311.8157348632812500 | 3.1896591186523438 | 543
LocalSysCacheMyDBMemoryContext | 175.0625000000000000 | 65.0446166992187500 | 543
DefaultTopMemoryContext | 168.5756530761718750 | 10.7153015136718750 | 543
ThreadTopMemoryContext | 161.9752502441406250 | 4.1196441650390625 | 543
CBBTopMemoryContext | 109.1161880493164063 | 6.7845993041992188 | 543
LocalSysCacheTopMemoryContext | 93.4109802246093750 | 13.2236938476562500 | 543
Timezones | 43.2421417236328125 | 1.4333953857421875 | 543
gs_signal | 32.2394561767578125 | 4.9155120849609375 | 1
Type information cache | 23.8869018554687500 | .90544128417968750000 | 343
(10 rows)
確定內存上下文之后,以StorageTopMemoryContext為例,查詢視圖gs_get_thread_memctx_detail(第一個入參為線程ID,可以通過查詢視圖gs_thread_memory_context獲得 ),確定內存堆積的代碼位置。
gaussdb=# select * from gs_get_thread_memctx_detail(140639273547520,'StorageTopMemoryContext');
file | line | size
--------------+------+--------
syncrep.cpp | 1608 | 32
elog.cpp | 2008 | 16
fd.cpp | 2734 | 128
syncrep.cpp | 1568 | 32
deadlock.cpp | 175 | 512
deadlock.cpp | 169 | 342656
deadlock.cpp | 157 | 85664
deadlock.cpp | 146 | 21416
deadlock.cpp | 144 | 32112
deadlock.cpp | 136 | 10712
deadlock.cpp | 135 | 10712
deadlock.cpp | 128 | 85664
deadlock.cpp | 126 | 21416
(13 rows)
從上述查詢結果可以看出,在代碼deadlock.cpp的169行申請了大量的內存,可能存在內存堆積不釋放的問題。
無現場環境
若存在內存過載時間節點的內存快照信息,則在內存統計信息中找到Thread Memory Context類型的top20的內存上下文申請詳情,即可確認內存堆積的原因。
若不存在內存過載時間節點的內存快照信息,請聯系華為工程師定位解決。
總結:使用上面2種方法找到內存占用過多的內存上下文后,可進行初步判斷,在數據庫內核執行業務時,一般占用較多的全局內存上下文有“LocalSysCacheShareMemoryContext”,“StorageTopMemoryContext”,如果是這兩個context占用較多,則需要減小業務的并發來降低內存占用;如果是其他內存上下文,可能是業務執行過程出現內存堆積,請聯系華為工程師解決。
3、session級內存上下文占用內存較高
有現場環境,查詢如下語句即可確認是哪個內存上下文占用內存較高。
gaussdb=# select contextname, sum(totalsize)/1024/1024 sum, sum(freesize)/1024/1024, count(*) count from pv_session_memory_context group by contextname order by sum desc limit 10;
contextname | sum | ?column? | count
----------------------------+----------------------+-----------------------+-------
CachedPlan | 226.1093750000000000 | 67.1747817993164063 | 12450
CachedPlanQuery | 134.8027343750000000 | 41.8541030883789063 | 12612
SessionTopMemoryContext | 132.1605682373046875 | 26.1002349853515625 | 301
CachedPlanSource | 98.7617187500000000 | 28.4135513305664063 | 12912
CBBTopMemoryContext | 60.4861373901367188 | 3.0370101928710938 | 301
Timezones | 23.9703216552734375 | .79457092285156250000 | 301
SPI Plan | 21.1307907104492188 | 6.8435440063476563 | 2412
GenericRoot | 19.9628906250000000 | 7.7032165527343750 | 374
Prepared Queries | 16.4062500000000000 | 7.5508117675781250 | 300
unnamed prepared statement | 14.3437500000000000 | 6.6462554931640625 | 300
(10 rows)
確定內存上下文之后,以CachedPlan為例,查詢視圖gs_get_session_memctx_detail,確定內存堆積的代碼位置。
gaussdb=# select * from gs_get_session_memctx_detail('CachedPlanQuery');
file | line | size
---------------+------+---------
copyfuncs.cpp | 2607 | 5031680
copyfuncs.cpp | 7013 | 4176736
copyfuncs.cpp | 7016 | 2088368
copyfuncs.cpp | 5062 | 6918144
copyfuncs.cpp | 3461 | 403552
copyfuncs.cpp | 3397 | 2727104
copyfuncs.cpp | 3401 | 487368
datum.cpp | 150 | 2048
copyfuncs.cpp | 2572 | 1113728
copyfuncs.cpp | 6204 | 32
copyfuncs.cpp | 6206 | 32
copyfuncs.cpp | 7021 | 4267200
copyfuncs.cpp | 7037 | 2832000
copyfuncs.cpp | 7048 | 2066400
bitmapset.cpp | 94 | 134400
copyfuncs.cpp | 3430 | 96000
copyfuncs.cpp | 2847 | 2150400
copyfuncs.cpp | 2551 | 5126400
copyfuncs.cpp | 3984 | 105600
list.cpp | 105 | 254400
list.cpp | 108 | 796800
copyfuncs.cpp | 3835 | 7065600
copyfuncs.cpp | 2451 | 1056000
copyfuncs.cpp | 2453 | 244800
copyfuncs.cpp | 3840 | 230400
copyfuncs.cpp | 2895 | 1113600
copyfuncs.cpp | 3442 | 38400
copyfuncs.cpp | 2645 | 115200
list.cpp | 166 | 19200
namespace.cpp | 3853 | 144000
list.cpp | 1460 | 288000
copyfuncs.cpp | 2910 | 38400
copyfuncs.cpp | 2762 | 1075200
copyfuncs.cpp | 3953 | 67200
copyfuncs.cpp | 3000 | 96000
copyfuncs.cpp | 5876 | 28800
copyfuncs.cpp | 2619 | 2400
(37 rows)
從上述查詢結果可以看出,在代碼copyfuncs.cpp的3835行申請了大量的內存,可能存在內存堆積不釋放的問題。
無現場環境
若存在內存過載時間節點的內存快照信息,則在內存統計信息中找到Session Memory Context類型的top20的內存上下文申請詳情,即可確認內存堆積的原因。
若不存在內存過載時間節點的內存快照信息,請聯系華為工程師定位解決。
總結:使用上面2種方法找到內存占用過多的內存上下文后,可進行初步判斷,在數據庫內核執行業務時,一般占用較多的全局內存上下文有“CachedPlan”,“CachedPlanQuery”,“CachedPlanSource”,“SessionTopMemoryContext”,如果是這幾個context占用較多,則需要減小業務的并發來降低內存占用;如果是其他內存上下文,可能是業務執行過程出現內存堆積,請聯系華為工程師解決。
4、其他內存占用較高
內存碎片過多導致內存緩存過多,數據庫執行作業時,數據庫內部頻繁申請和釋放內存如創建大量的cache plan的情況下會造成大量的內存碎片,由于底層內存機制的緣故,這些內存碎片不會被操作系統立即回收,而是緩存起來,數據庫在統計的時候會將其計算在other_used_memory里面,如下所示。
gaussdb=# select * from pv_total_memory_detail;
nodename | memorytype | memorymbytes
----------------+-------------------------+--------------
coordinator1 | max_process_memory | 81920
coordinator1 | process_used_memory | 24567
coordinator1 | max_dynamic_memory | 34012
coordinator1 | dynamic_used_memory | 1851
coordinator1 | dynamic_peak_memory | 3639
coordinator1 | dynamic_used_shrctx | 394
coordinator1 | dynamic_peak_shrctx | 399
coordinator1 | max_backend_memory | 648
coordinator1 | backend_used_memory | 1
coordinator1 | max_shared_memory | 46747
coordinator1 | shared_used_memory | 11618
coordinator1 | max_cstore_memory | 512
coordinator1 | cstore_used_memory | 0
coordinator1 | max_sctpcomm_memory | 0
coordinator1 | sctpcomm_used_memory | 0
coordinator1 | sctpcomm_peak_memory | 0
coordinator1 | other_used_memory | 11013
coordinator1 | gpu_max_dynamic_memory | 0
coordinator1 | gpu_dynamic_used_memory | 0
coordinator1 | gpu_dynamic_peak_memory | 0
coordinator1 | pooler_conn_memory | 0
coordinator1 | pooler_freeconn_memory | 0
coordinator1 | storage_compress_memory | 0
coordinator1 | udf_reserved_memory | 0
(24 rows)
其他原因導致內存未及時釋放
此處需要注意:other_used_memory過大不全部都是因為內存碎片導致的,也可能是如下原因:
1). 業務代碼中存在沒有在內存上下文上申請內存直接使用了malloc接口申請內存的地方,且出現了內存堆積。
2). 第三方開源軟件存在內存未及時釋放的場景。
出現這兩種情況時,需要聯系華為工程師協助解決。
3. 解決方案
- 內存堆積導致內存滿
- 業務原因導致內存滿
- other內存緩存過多導致內存滿
方案二:出現內存堆積長時間不釋放時,且無法通過調整業務來降低內存時則需要通過做主備切換來降低內存的使用。
