




目錄
在上一篇文章中我給大家介紹了Vertica數據庫脫穎而出的15個特性中的前5個,那么,今天我們繼續介紹另外5個。好的,我們現在開始!

不依賴于底層存儲

Vertica數據庫以對基礎設施的不可知而出名,它不在乎是什么品牌的供應商,這些供應商的存儲設備可以裝載TB容量級的數據,存儲設備內置FPGA和GPU芯片并通過InfiniBand這樣的高速帶寬技術進行網絡連接。

從上圖我們可以看出,Vertica數據庫甚至可以將一個表的不同分區的數據保存在不同的存儲設備上,也可以將不同的表放在不同的存儲上,如:本地磁盤和HDFS,或者是,SAN存儲和亞馬遜的S3上。還有一點,建議將表中的舊分區數據保存在價格相對便宜的存儲上。另外,這些存儲對用戶來說,是完全透明的。

為物聯網和點擊流場景而生
Vertica數據庫可以兼容ANSI SQL標準,能夠對數據進行實時的洞察和分析,以了解當前新的趨勢。一般來說,物聯網和點擊流場景正需要像Vertica這樣的大數據分析平臺。
Vertica總是領先一步,它現在提供對OLAP擴展的全面支持,像地理空間分析、時間序列和機器學習這樣的場景。
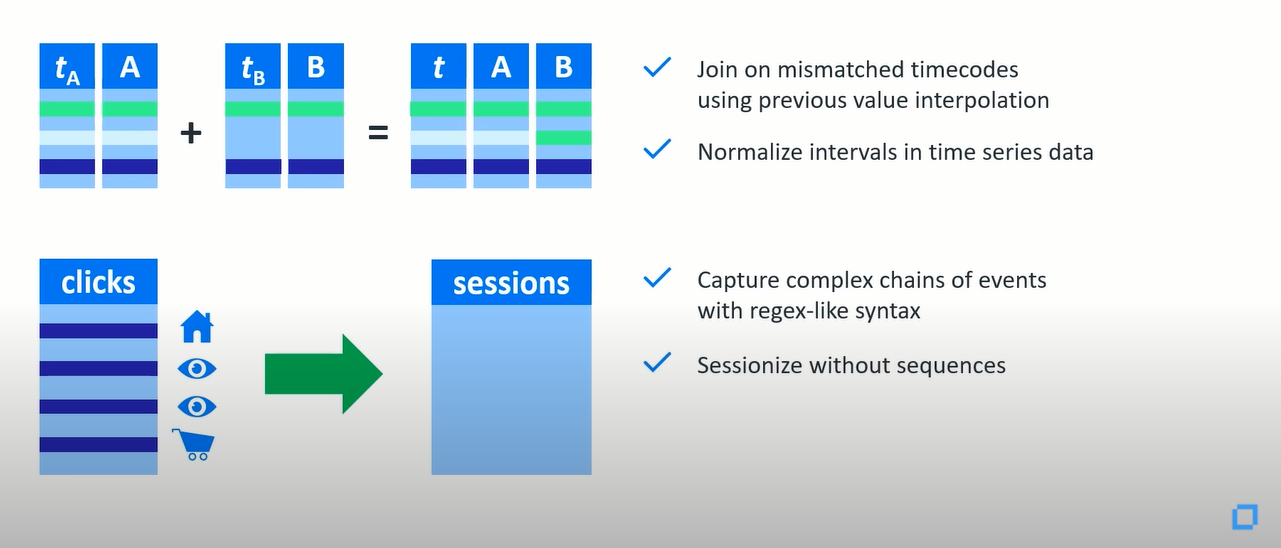
現在我們只考慮物聯網場景的時間序列。假如,這里有兩個傳感器的數據不同步,如何把它們很好地結合起來?您只需在不匹配的時間碼上插入值并連接兩個表,您還可以對時間序列數據中的間隔進行標準化。如果你想讓你的傳感器數據變得有意義,一定需要做很多事情。
接著,讓我們談一下點擊流場景中的復雜事件處理,您需要捕獲在幾個小時中發生的一系列事件,這個沒有問題。將單個事件定義為連續的條件為B和C并查找包含B和C的正則表達式,客戶輸入您的站點,您在網站內進行了購買,是否還有其他東西定義了整個點擊鏈?它是作為單個用戶會話的整個序列,然后找到它發生的所有時間,這里會話作為您的數據,而不使用性能瓶頸序列或者填補數據的空白。因為傳感器總是不可靠的,您不需要寫自定義代碼或為此安裝專用的時間序列數據庫。這一切都是開箱即用的!!!

支持端到端的機器學習工作流
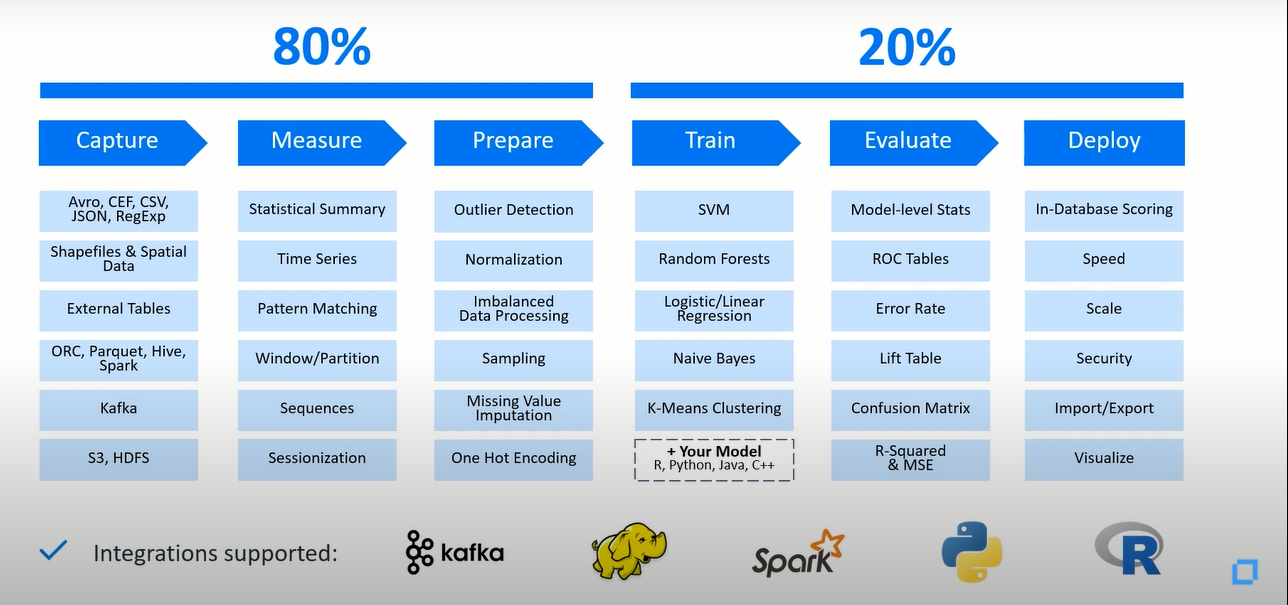
現在人們已經意識到,是時候將他們以某種方式存儲了多年的數據進行變現或盈利了。他們認為這是一件明智的事情,但機器學習是一個技術門檻極高的新型行業,數據科學家是高級DBA們年齡的一半,那么您如何很好地彌合這一差距?您只需要一個單一的平臺,為您提供使用機器學習的整個流程,將數據變現所作的一切工作會占據您80%的時間(在捕獲數據、標準化數據、準備數據這三個階段)。
眾所周知,數據科學家們不開發和研究機器學習的算法,他們只負責收集和準備數據。為機器學習準備大量的源數據,這是一項極其艱巨的任務,我們內置了所有必需的PB數量級的工具(包括:異常值檢測、缺失值插補、標準化、一次性熱編碼)。
如果數據科學家想要在Python中工作,他們可以使用原生的Python客戶端、本機Python庫、用于用戶定義函數的本機Python API,包括機器學習算法。
如果分析師想做機器學習相關的工作,可是他們想要使用用SQL做所有事情,沒有問題。這一切都是原生的SQL,它是一個SQL數據庫。我們沒有額外的硬件、沒有額外的軟件、沒有自定義代碼。一切都是開箱即用!!!

支持原生JSON、日志格式、Hive的orc和parquet文件存儲格式

Vertica數據庫支持原生JSON、日志格式、Hive的Orc和Parquet文件存儲格式,它不僅與基礎架構和存儲無關,而且在很大程度上也與文件存儲格式無關。如果您想使用正則表達式記錄日志文件,您無需為此費心。我們使用彈性表(Flexible Table) 可以做得更好更快,您想將JSON映射到關系數據庫結構模型上,我們可以使用彈性表更好更快地實現。您想從設備的日志中收集CSV文件,但列的順序已更改,適合于一次更新彈性表的一個語句,現在基于列名而不是列順序。您希望比任何基于Hadoop的解決方案更快地使用Parquet和Orc這樣的文件格式,也許您只是恰巧有一些Spark文件,但是根本沒有Hadoop集群。您希望在不將任何數據導入數據庫的情況下完成所有這些工作,通過使用外部表允許您在動態掃描數據的同時執行這些操作,如果您再次加載它時會更快。這些統統沒有添加硬件、沒有添加軟件、沒有自定義代碼,都是開箱即用。

非常靈活的體系架構適用于任何項目

從Oracle或SQL Server準備數據集市以加速他們的數據倉庫,現在他們正在做他們從未想過的事情。一個物理服務器到一個帶有數據和S3的云服務集合,它們能夠以任何方式加載數據。他們想要從隔夜加載到新的實時流媒體,他們準備好了想要從數據庫轉換到實時流,但是他們想要從完全扁平化到標準化扁平化再到數據庫支持的第六范式,所有這一切都歸功于它們具有的靈活性。
以上就是這篇文章的所有內容,感謝您從百忙之中抽出您的寶貴時間閱讀,如果您有好的意見或建議,歡迎在評論區留言,我將逐一回復,再次感謝!另外,我的下一篇文章將要介紹Vertica數據庫脫穎而出的15個特性中的最后5個,敬請期待!!!
