




一、事件的發生與處理經過
??晚上22:15 收到數據庫日志報警:ORA-1652 短信,把處理過程記錄下來供大家參考。
- 查看alert日志如下:

- 查看TEMP使用情況:
SELECT S.sid || ',' || S.serial# sid_serial,
S.username,
T.blocks * TBS.block_size / 1024 / 1024 mb_used,
T.tablespace,
T.sqladdr address,
Q.hash_value,
Q.sql_text
FROM v$sort_usage T, v$session S, v$sqlarea Q, dba_tablespaces TBS
WHERE T.session_addr = S.saddr
AND T.sqladdr = Q.address(+)
AND T.tablespace = TBS.tablespace_name
ORDER BY mb_used desc;
??
- 查看AWR報告情況

??找到了引起的2條性能SQL,考慮到此查詢不影響正常交易,且是晚上臨時優化可能會優化出其它BUG,因此擴展了30G的臨時表空間臨時頂一下,等待明天上班后再做優化處理。(期間已經和領導做了匯報,并與開發確認了SQL功能。及時的上報問題是職場必備技能)
- 擴展臨時表空間語句:
alter tablespace temp add tempfile '+DATA/RAC/tempfile/temp.02.dbf' size 100m AUTOEXTEND ON NEXT 500M MAXSIZE 30g;
二、問題復現及優化
1、數據準備
- 表及數據、性能SQL已經做脫敏處理。
SQL> select count(*) from t_main_order;
COUNT(*)
----------
20136575
SQL> select count(*) from t_INFO;
COUNT(*)
----------
9365634
SQL> select count(*) from t_bank;
COUNT(*)
----------
12944012
create index IDX_mer_id on t_main_order (mer_id);
create unique index idx_t_order_id on t_main_order (t_order_id);
create index IDX_out_id on t_bank (out_id);
create index ind_REVERSE_bank_no on t_bank (REVERSE(bank_no));
2、性能SQL
select t.mer_id,
t.t_order_id,
o.amt,
t.create_date,
case when o.source is null then '10000' else o.source end source
from t_main_order t
left join t_INFO r
on r.t_order_id = t.t_order_id
left join t_bank o
on r.th_id = o.out_id
where reverse(o.bank_no) like reverse('5033061623001736751456013595') || '%';
??看到此SQL第一反應是 like 條件沒走索引導致的性能問題
3、執行計劃
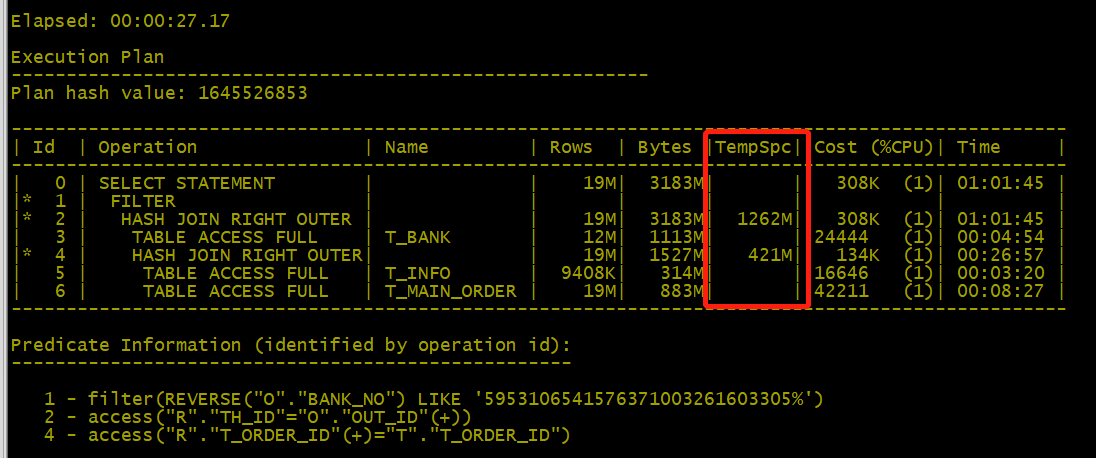
- 發現的問題:
1、執行耗時:27s
2、臨時表空間使用:1262M+421M=1683M - 問題分析
??從執行計劃可以看出TEMP表空間消耗在HASH JOIN(TempSpc),簡述一下HASH JOIN原理:借助HASH算法將2張表做關聯(關聯僅一次),此操作在PGA空間完成,當PGA空間放不下時,會占用臨時表空間(TEMP),因此HASH JOIN適用于小表之間的關聯。
??這條SQL涉及到的表的數據量達到了千萬量級的大表,且where 條件篩選的是輔表(t_bank)reverse(o.bank_no) 字段,從執行計劃的執行順序可以發現SQL執行是先做的表關聯再做的條件篩選。
??因此第一反應的"LIKE"并不是此SQL的性能問題。
4、優化一:把t_bank做主表,同樣可以滿足業務需求
select t.mer_id,
t.t_order_id,
o.amt,
t.create_date,
case when o.source is null then '10000' else o.source end source
from t_bank o
left join t_INFO r
on r.th_id = o.out_id
left join t_main_order t
on r.t_order_id = t.t_order_id
where reverse(o.bank_no) like reverse('5033061623001736751456013595') || '%';
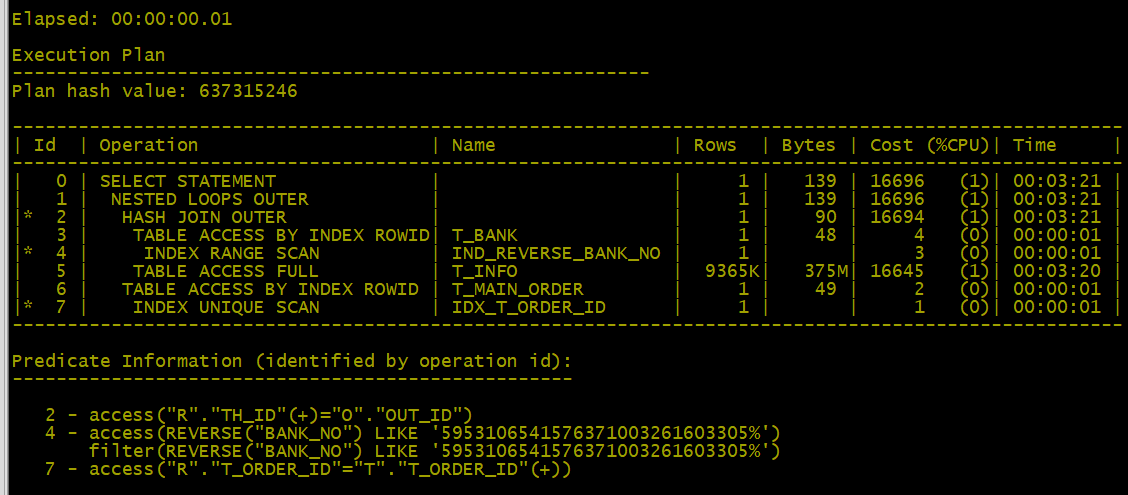
- 優化后的執行計劃分析:
1、SQL執行順序先做了條件篩選(*4|INDEX RANGE SCAN|IND_REVERSE_BANK_NO)并使用了索引,減少了表(t_bank )與(t_INFO )關聯的記錄,同樣也使用到了hash join但此操作未使用TEMP。
2、執行時間消耗:00:00:00.01與00:00:27.17是質的提升。
5、優化二:把left join 改為 inner join
select t.mer_id,
t.t_order_id,
o.amt,
t.create_date,
case when o.source is null then '10000' else o.source end source
from t_main_order t
inner join t_INFO r
on r.t_order_id = t.t_order_id
inner join t_bank o
on r.th_id = o.out_id
where reverse(o.bank_no) like reverse('5033061623001736751456013595') || '%';
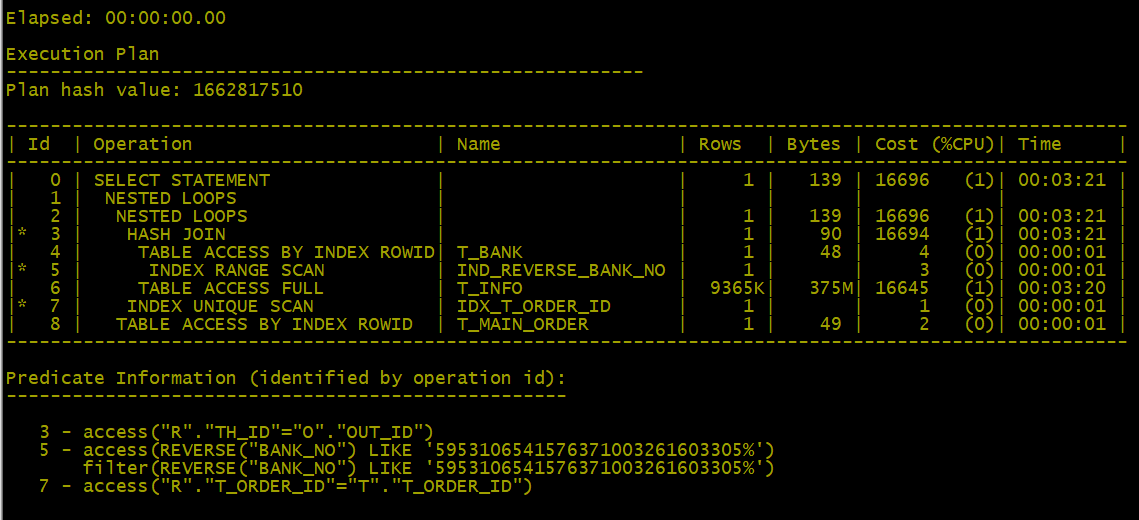
6、進一步優化t_INFO表增加索引
create index IDX_INFO_order_id on t_INFO (t_order_id );
create index IDX_INFO_th_id on t_INFO (th_id );
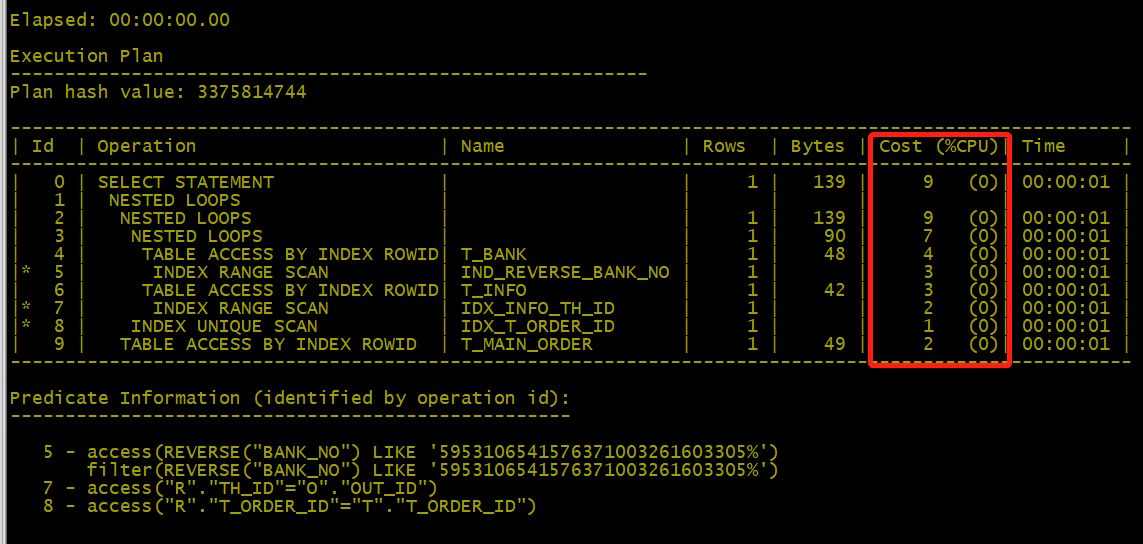
- 消耗(Cost (%CPU))從16696直接降到了9.
- 注:個人覺得這一步優化非必要,通過上次的2個優化方案執行時間已經降至:00:00:00.01。
增加索引代表著空間使用率增加。一切的優化沒必要做到極致,極致是有代價的。
三、總結:
??分析到最后發現這條性能SQL的根本問題:主表輔表開發人員沒整清楚(:!)
文章推薦
– 故障
《Oracle_索引重建—優化索引碎片》
《Oracle 自動收集統計信息機制》
《DBA_TAB_MODIFICATIONS表的刷新策略測試》
《FY_Recover_Data.dbf》
《Oracle RAC 集群遷移文件操作.pdf》
《Oracle Date 字段索引使用測試.dbf》
《Oracle 診斷案例 :因應用死循環導致的CPU過高》
《記錄一起索引rebuild與收集統計信息的事故》
《RAC DG刪除備庫redo時報ORA-01623》
《問答榜上引發的Oracle并行的探究(一)》
《問答榜上引發的Oracle并行的探究(二)》
《DG 同步延遲之奇怪的經典報錯:ORA-16191》
– 等待事件
《log file sync》 等待事件問題分析匯總
《ASH報告發現:os thread startup 等待事件分析》
– 監控&腳本
《DG standby time 監控腳本部署》
《Oracle 慢SQL監控腳本》
《Oracle 慢SQL監控測試及監控腳本.pdf》
《oracle 監控表空間腳本 每月10號0點至06點不報警》
《Oracle 腳本實現簡單的審計功能》
– 安裝系列
《ORACLE_19C_linux安裝.pdf》
《Oracle 19c-手工建庫.pdf》
《19c單庫升級19.11補丁.pdf》
《19c_rac補丁《19.11-p32841500》.pdf 》
《oracle_圖形-單實例11.2.0.4升級19.3.pdf》
《oracle_11.2.0.3升級11.2.0.4–單實例升級.pdf》
《oracle_靜默-單實例 11.2.0.4升級19.3.pdf》
《CentOS_6.7系統一步一步 RAC 11.2.0.4升級19.3.pdf》
《整理后_RAC_11.2.0.4升級19c.pdf》
歡迎贊賞支持或留言指正
